◆ 목차
- 여러 웹 크롤링
- 시각화
- 데이터분석 & 프로젝트 연습 실습
크롤링
(4주차 이어서)
◆ 와인 데이터
■ 가정해보기
# 와인가게 운영중이라고 가정
# 우리 가게에 와인들은 어떤 와인들이 있고, 어떤 취향으로 구성 되어있는지
# 우리 가게가 장사가 잘 안됨 / 다른가게는 장사가 잘됨
# 무엇이 다른지 잘되는 가게 데이터를 수집
■ 데이터 불러오기
▶ cvs 파일은 꼭 jupyter 폴더에 넣어야 가능
# EDA
# 1) 데이터 불러오기
import pandas as pd
df = pd.read_csv('winequality.csv')
df
# 데이터 타입을 먼저 보고 Dtype에서 변경 해야하는 type을 변경 후 전처리 해주기
df.info()
df.describe()
① 우리 가게 레드와인과 화이트와인의 개수는 몇 개인지?
df_redwine = df[df['type'] == 'red'] # 1599
df_whitewine = df[df['type'] == 'white'] # 4898
df_whitewine

② 당도의 차이는?
df_whitewine['residual sugar'].mean(), df_redwine['residual sugar'].mean()
③ 와인 등급을 3, 9 확인
# 와인 등급이 3보다 낮은
df['quality'].unique() # 3~9등급
df['quality'].value_counts()
df[df['quality'] == 9] # 등급이 9
df[df['quality'] == 3] # 등급이 3
④ 우리 가게에서 등급이 높은 상위 10개 와인은?
# 당도 포함 상위 10개
df[['type','residual sugar','quality']].sort_values(by=['quality'], ascending=False).head(10)
# index 정렬하여 상위10
df[['type','residual sugar','quality']].sort_values(by=['quality'], ascending=False).head(10).sort_index()
⑤ 우리가게에서 등급이 낮은 하위 10개 와인은?
df[['type','residual sugar','quality']].sort_values(by=['quality']).head(10)
# 당도와 등급은 어떤 관계가 있을까? 상관계수 구하기
df_whitewine['quality'].corr(df_whitewine['residual sugar'])
# value_counts()
# 한 개의 컬럼에서 각각 데이터의 개수가 어떻게 되는지 확인
df['quality'].value_counts().sort_index(ascending=False)
⑥ pH가 가장 높은 와인은?
# pH가 가장 높은 와인은?
# df['pH'].idxmax() # pH가 제일 높은것
df.loc[df['pH'].idxmax()].to_frame()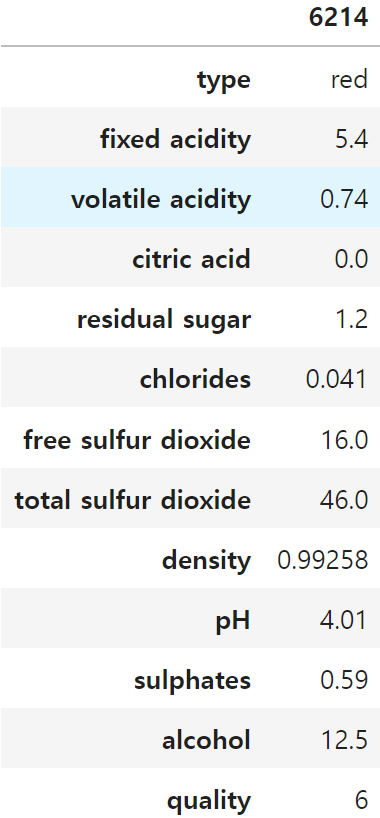
⑦ 알코올 값이 7 이상인 행들의 sulphates 평균은?
df[df['alcohol']>=7]['sulphates'].mean()df.loc[df['alcohol']>=7, 'sulphates'].mean()
⑧ 와인의 타입별 등급의 평균값은 어떻게 되는지?
# 와인의 티입별 등급의 평균값은 어떻게 되는지?
# groupby()
df.groupby('type')['quality'].mean()
◆ NBA 데이터
▶ NBA 데이터 불러오기
import pandas as pd
df = pd.read_csv('nba.csv')
df
▶ 데이터 문제
1) 현재 각 팀별 선수는 몇 명씩 있나요?
2) 포지션별 평균 연봉은 어떻게 되나요?
3) 팀별 평균 연봉은 어떻게 되나요?
4) 학교별로 출신 선수가 몇 명 인지를 보고자 하면 어떻게 하면 될까요?
5) 가장 많은 연봉을 받는 선수를 배출한 학교 top 10
6) 평균 키가 가장 큰 팀은 어디인가요?
① 현재 각 팀별 선수는 몇 명씩 있나요?
df['College'].value_counts().to_frame()
# value_counts()
df['Team'].value_counts().to_frame()
# groupby
groupby_team = df.groupby('Team')
groupby_team.groups # index값
# team을 그룹화
groupby_team.size()
# 정렬하기
groupby_team.size().sort_values() # 내림차순 정렬
# sort_values안에 by는 정렬 기준이 될 레이블을 뜻함
groupby_team.mean(numeric_only=True).sort_values(by='Salary', ascending=False) # 오름차순
② 포지션별 평균 연봉은 어떻게 되나요?
# Position 컬럼에 대해 그룹화
df.groupby('Position')['Salary'].mean(numeric_only=True).sort_values().to_frame()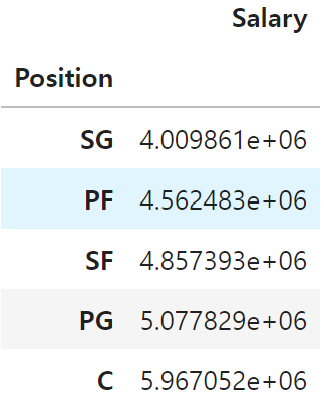
③ 팀별 평균 연봉은 어떻게 되나요?
# Team에 대해서 그룹화
df.groupby('Team')['Salary'].mean().sort_values()
# Position에 대해 unique값을 리스트로
positions = list(df['Position'].unique())
positions
→ 평균값을 구하기
df[df['Position'] == 'C']['Salary'].mean() # 5967052.0
df[df['Position'] == 'PG']['Salary'].mean() # 5077829.215909091
df[df['Position'] == 'PF']['Salary'].mean() # 4562482.989690722
→ 반복문으로 구하기
# list는 반복문 가능
positions = list(df['Position'].unique()) # 해당 컬럼의 유니크 값을 가져옴
for position in positions:
print(f'position : {position}')
print(df[df['Position'] == position]['Salary'].mean())
④ 학교별로 출신 선수가 몇 명 인지를 보고자 하면 어떻게 하면 될까요?
df['College'].value_counts()
→ DataFrame으로 만들기
df['College'].value_counts().to_frame()
⑤ 평균 연봉이 가장 높은 학교 Top10
df['College'].value_counts().head(10)
df.groupby('College').size()
df.groupby('College')['Salary'].mean().sort_values(ascending=False)
⑥ 평균 키가 가장 큰 팀은 어디인지?
df.info()
→ 외국 Height 표기
df['Height'] # 6-2 / 6feet 2inchs라는 뜻
def height_to_cm(height):
feet = int(height.split('-')[0]) # "-" 기준으로 나누기
inch = int(height.split('-')[1])
cm = feet * 30.48 + inch * 2.54
return cm
df['Height'].isna().sum() # 1개의 NaN 있음
# 지우기
df = df.dropna(how='any')
df['Hight(cm)'] = df['Height'].apply(height_to_cm)
df
→ 예외처리
# 키 cm 단위로 계산
Height_cm = []
for i in df['Height']:
try:
ft, inch = i.split('-')
cm = (int(ft) * 12 + int(inch)) * 2.54
Height_cm.append(cm)
except:
cm = ""
Height_cm.append(cm)
# 새로운 컬럼 생성
df['Height_cm'] = Height_cm
# 팀 별 평균 키 계산
df.groupby('Team')['Height_cm'].mean().idxmax()
◆ 타이타닉 데이터
import pandas as pd
df = pd.read_csv('titanic.csv')
df
☞ 컬럼명 정리
Passengerid: 탑승자 데이터 일련번호
survived: 생존 여부, 0 = 사망, 1 = 생존
Pclass: 티켓의 선실 등급, 1 = 일등석, 2 = 이등석, 3 = 삼등석
sex: 탑승자 성별
name: 탑승자 이름
Age: 탑승자 나이
sibsp: 같이 탑승한 형제자매 또는 배우자 인원수 동반한 Sibling(형제자매)와 Spouse(배우자)의 수
parch: 같이 탑승한 부모님 또는 어린이 인원수
ticket: 티켓 번호
fare: 요금
cabin: 선실 번호
embarked: 중간 정착 항구 C = Cherbourg, Q = Queenstown, S = Southampton
df.info()
→ null : age, cabin, embarked
df.isna().sum()
① 등급별(Pclass) 등급별 생존자 수 - 상관관계가 있는지?
df.groupby('Pclass')['Survived'].count()
df.groupby(['Pclass','Survived']).size()
df.arrive = df[df['Survived']==1]
df.arrive
df_alive = df[df['Survived']==1]
df_alive.groupby('Pclass').size()
df_dead = df[df['Survived']==0]
df_dead.groupby('Pclass').size()
df['Pclass'].value_counts()
② Embarked에 따른 고객의 Pclass는 어떻게 분류되는지?
df.groupby(['Embarked','Pclass']).size()
df.groupby(['Embarked','Pclass']).size().to_frame()
df.groupby('Embarked')['Pclass'].value_counts()
③ FamilyNum에 따른 생존율은 어떻게 되는지?
# SibSp + Parch + 1 => FamilyNum
df['FamilyNum'] = df['SibSp'] + df['Parch'] + 1
# df.head()
# FamilyNum 컬럼 추가, SibSp/Parch 컬럼 제거
df = df.drop(columns=['SibSp', 'Parch'])
df
df['FamilyNum'].value_counts()
df.groupby(['FamilyNum', 'Survived']).size()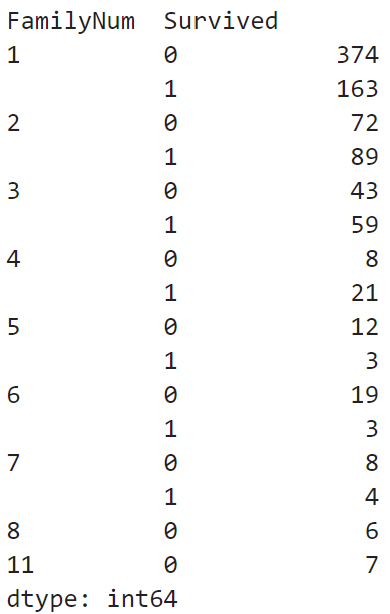
df[df['FamilyNum'] == 11]
④ 고령자(60세 이상)의 생존 확률은 어떻게 될까?
- 고령자만 표로 나타내시오.
df_senior = df[df['Age'] >= 60][['Name', 'Sex', 'Age', 'Survived']]
df_senior['Survived'].value_counts()
⑤ 요금을 가장 많이 낸 상위 10명의 생존확률은?
df.sort_values(by='Fare', ascending=False)[['Fare', 'Survived', 'Embarked']].head(10)
☞ NaN 데이터 처리하기
# Age에 값을 채우기(Null값이 있는것 만큼)
df['Age'] = df['Age'].fillna(df['Age'].mean())
df.isna().sum()
df['Cabin'].nunique() #147
df['Cabin'].unique()
df['Cabin'] = df['Cabin'].fillna(value='C001')
df.isna().sum()
df['Embarked'].value_counts()
df['Embarked'] = df['Embarked'].fillna('S')
df.isna().sum()
→ 3개가 다 같은 결과
df['Sex']
df['Sex'] = df['Sex'].replace('male',0).replace('female',1)
df['Sex']df['Sex'] # f-1, m-0
df['Sex'] = df['Sex'].replace('male',0)
df['Sex'] = df['Sex'].replace('female',1)
df['Sex']df['Sex'] = df['Sex'].replace({
'male':0,
'female':1
})
df['Sex']
시각화
◆ matplotlib
☞ 라이브러리 설치
!pip install matplotlib
☞ matplotlib 시각화 사용
import matplotlib.pyplot as plt
import numpy as np
plt.plot([1,2,3,4,1])
x = np.arange(0, 10, 1)
y = np.sin(x)
y2 = np.cos(x)
# dpi: dots per inch
plt.figure(figsize=(30,10), facecolor='pink', dpi=600) # 도화지
plt.plot(x, y, label='sin', marker='o', # marker는 표시할 모양
markersize=20, color='red') # 공학용 시각화 -> seaborn
plt.plot(x, y2, label='cos', marker='x')
plt.title('Sin Graph')
plt.xlabel('Time')
plt.ylabel('Amplitude')
plt.grid()
plt.xlim(0, np.pi)
plt.ylim(-1.2, 1.2)
plt.legend(loc=(1.01,0)) # 범례
values = [100, 130, 150]
labels = ['kor', 'china', 'usa']
colors = ['red', 'blue', 'yellow']
plt.ylim(90, 160)
plt.bar(labels, values, color=colors, alpha=0.5)
# matplotlib: 방대한 양의 데이터를 시각화 할 때 활용
import matplotlib.pyplot as plt
import numpy as np
species = ("컬럼1", "컬럼2", "컬럼3") # unique
penguin_means = {
'컬럼1': (18.35, 18.43, 14.98),
'컬럼2': (38.79, 48.83, 47.50),
'컬럼3': (189.95, 195.82, 217.19),
}
x = np.arange(len(species)) # the label locations
width = 0.25 # the width of the bars
multiplier = 0
fig, ax = plt.subplots(layout='constrained')
for attribute, measurement in penguin_means.items():
offset = width * multiplier
rects = ax.bar(x + offset, measurement, width, label=attribute)
ax.bar_label(rects, padding=3)
multiplier += 1
# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_ylabel('Length (mm)')
ax.set_title('Penguin attributes by species')
ax.set_xticks(x + width, species)
ax.legend(loc='upper left', ncols=3)
ax.set_ylim(0, 250)
plt.show()
◆ scatter
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/KNN_data.csv')
df
df_large = df[df['Label'] == 'Large']
df_medium = df[df['Label'] == 'Medium']
df_small = df[df['Label'] == 'Small']
plt.scatter(df_large['x'], df_large['y'], label='large')
plt.scatter(df_medium['x'], df_medium['y'], label='medium')
plt.scatter(df_small['x'], df_small['y'], label='small')
plt.legend()
☞ 연습문제
1. 영화 데이터를 활용하여 x 축은 영화, y축은 평점인 막대 그래프를 만드시오.
(1) 막대그래프
(2) x=영화, height=평점
2. 앞에서 만든 막대 그래프에 제시된 세부 사항을 적용하시오.
- 제목: 국내 Top 8 영화 평점 정보
- x축 label: 영화 (90도 회전)
- y축 label: 평점
# font 사용
plt.rc('font', family='AppleGothic')
import pandas as pd
import matplotlib.pyplot as plt
data = {
'영화' : ['명량', '극한직업', '신과함께-죄와 벌', '국제시장', '괴물', '도둑들', '7번방의 선물', '암살'],
'개봉 연도' : [2014, 2019, 2017, 2014, 2006, 2012, 2013, 2015],
'관객 수' : [1761, 1626, 1441, 1426, 1301, 1298, 1281, 1270], # (단위 : 만 명)
'평점' : [8.88, 9.20, 8.73, 9.16, 8.62, 7.64, 8.83, 9.10]
}
df = pd.DataFrame(data)
df

import matplotlib.pyplot as plt
import numpy as np
plt.rc('font', family='Malgun Gothic')
plt.figure(figsize=(10,5))
plt.bar(df['영화'], df['평점'])
plt.xlabel('영화', rotation=90)
plt.ylabel('평점')
3. 개봉 연도별 평균 평점 변화 추이를 꺾은선 그래프(plot)로 그리시오.
- x: 개봉 연도, y: 평점
- marker: 'o'
- x축 눈금: 5년 단위 (2005, 2010, 2015, 2020)
- y축 범위: 최소 7, 최대 10df_개봉연도 = df.groupby('개봉 연도').mean(numeric_only=True)
df_개봉연도
df.info()
x = df_개봉연도.index # series
y = df_개봉연도['평점'] # series
plt.plot(x, y, marker='o')
◆ seaborn
☞ seaborn 라이브러리 설치
!pip install seabornimport seaborn as sns
df = sns.load_dataset("penguins")
sns.pairplot(df, hue="species")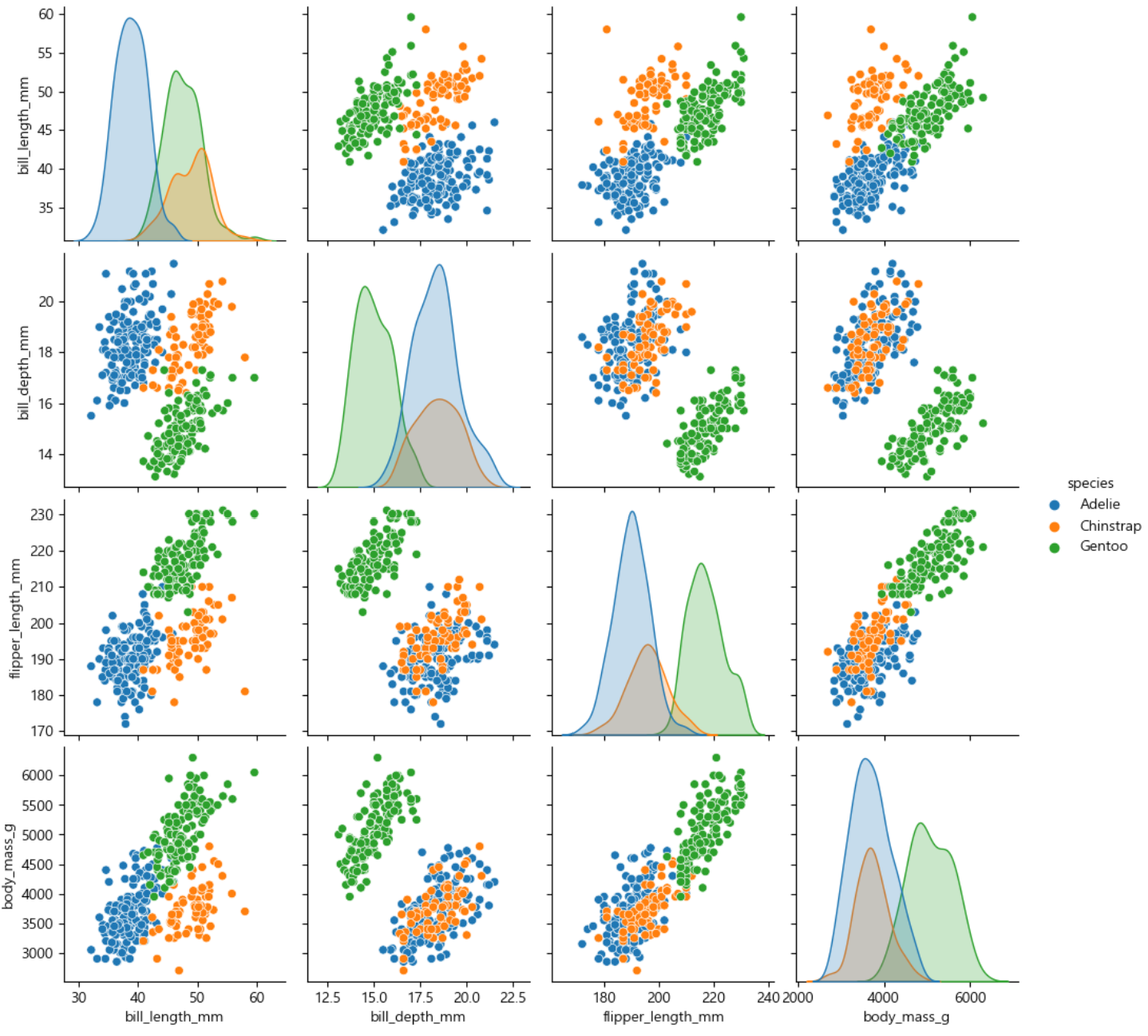
☞ 연습 문제
① 언제 일할 것인가?
df = sns.load_dataset("tips")
df
df.describe()
df.info()
▶시각화
sns.boxplot(x=df['day'], y=df['tip'])
sns.swarmplot(data=df, x='day', y='tip')
② 누구에게 갈 것인가?
# boxplot 시각화
sns.boxplot(data=df, x='smoker', y='tip', hue='sex')
# swarmplot 시각화
sns.swarmplot(data=df, x='smoker', y='tip', hue='sex')
가설 : 전체 금액이 높을수록-> 팁도 많이 주는가?
회귀분석 :
독립변인(X)이 종속변인(Y)에 미치는 영향도를 파악하고자 할 때 실시하는 분석 방법
상관관계 (-1, 1)
ex)
양의 상관관계:
키가 클수록 몸무게도 크다
전체 계산 금액이 클수록 팁도 많다
음의 상관관계:
평균속력이 높을수록 연비는 낮아진다sns.lmplot(data=df, x='total_bill', y='tip')
# 절편 방정식
# y = m * x + b
x = df['total_bill']
y = df['tip']
m, b = np.polyfit(x , y, 1)
plt.scatter(x, y)
plt.plot(x, m*x+b, color='r', label=f'회귀선 y={m:2f}x+{b:.2f}')
df.corr()
# 히트맵
df = sns.load_dataset('flights')
# pivot table
# df.pivot(index, columns, values)
df_pivot = df.pivot(index='month', columns='year', values='passengers')
# df.pivot(index=None, columns=None, values=None)
df_pivot # 시간 데이터를 히트맵으로 나타낸 것을 시계열 데이터
sns.heatmap(df_pivot, annot=True, fmt="d")
데이터분석 프로젝트 실습
(4주차 이어서)
◆ 부동산 데이터 분석을 통해 최적의 자취방 구하기
■ 크롤링하기
☞ user-agent 라이브러리 : 사용자를 대신하여 일을 수행
!pip install user-agent
☞ 임의에 user-agent 값을 생성
from user_agent import generate_user_agent, generate_navigator
user_agent = generate_user_agent()
user_agent
☞ 필요한 라이브러리 실행
import requests
import numpy as np
import pandas as pdfrom tqdm.notebook import tqdm
import time
☞ 네이버부동산 모바일버전 접속 → 매물목록 클릭 → 개발자도구 → Network → 매물 목록 스크롤 → artcleList 클릭 → Request URL 복사하여 새 브라우저에 검색해보기


☞ url을 넣고 user-agent값 가져오기
url = 'https://m.land.naver.com/cluster/ajax/articleList?itemId=&mapKey=&lgeo=&showR0=&rletTpCd=OPST%3AVL%3AOR&tradTpCd=B2&z=12&lat=37.481021&lon=126.951601&btm=37.3880594&lft=126.7838878&top=37.5738671&rgt=127.1193142&totCnt=8922&cortarNo=1162000000&sort=rank&page=2'
user_agent = generate_user_agent()
headers = {'User-Agent' : user_agent}
headers
☞ get을 사용하여 정보 가져오기
res = requests.get(url, headers=headers)
res
# jon 함수를 사용하여 정보 확인
res = requests.get(url, headers=headers)
res.json()
☞ body 부분에서 내가 필요로 하는 매물 정보가 확인(리스트형태로 확인)

☞ page를 변경하도록 for문을 통해 url request 정보들을 수집
article_list = []
for i in tqdm(range(1, 101)):
try: # 페이지가 100개까지 없는 경우를 대비해서 예외처리하기 위함
url = f'https://m.land.naver.com/cluster/ajax/articleList?itemId=&mapKey=&lgeo=&showR0=&rletTpCd=OPST%3AVL%3AOR&tradTpCd=B2&z=12&lat=37.481021&lon=126.951601&btm=37.3880594&lft=126.7838878&top=37.5738671&rgt=127.1193142&totCnt=8922&cortarNo=1162000000&sort=rank&page={i}'
user_agent = generate_user_agent()
headers = {'User-Agent':user_agent}
res = requests.get(url, headers=headers)
time.sleep(1)
article_json = res.json()
article_body = article_json['body']
article_list.append(article_body)
except:
break
☞ 리스트에 담기
article_list1 = [j for i in article_list for j in i]# 0번째에 저장된 값 확인
article_list1[0]
☞ 딕셔너리로 되어있던 정보를 DataFrame으로 변경
data = pd.DataFrame(article_list1)
data
# 필요한 data 가져오고
data = data[['atclNo','rletTpNm','flrInfo','rentPrc','hanPrc','spc1','spc2','direction','atclCfmYmd','repImgUrl','lat','lng','atclFetrDesc','tagList']]
# 가져온 data의 컬럼명 변경
data.columns = ['물건번호','구분','층수(물건층/전체층)','월세','보증금','계약면적(m2)','전용면적(m2)','방향','확인일자','이미지','위도','경도','설명','태그']
data
☞ 엑셀로 저장
data.to_excel('/content/drive/~/data1.xlsx')
■ 질문 만들기
- 최적의 자취방 구하기
- 내가 원하는 조건은?
- 보증금 3000만원 이하
- 월세는 저렴할수록 좋은
- 지하, 반지하, 꼭대기층은 선호하지 않음
- 전용면적이 클수록 좋음
- 북향은 선호하지 않음
- 연식이 오래되지 않을수록 좋음
- 지하철 역에서 가까울수록 좋음
- 내가 원하는 조건은?
■ 데이터 전처리
☞ 라이브러리 불러오기
import plotly.express as px
import folium
import warnings
warnings.filterwarnings(action='ignore')data = pd.read_excel('/content/drive/~/data1.xlsx')data.head()
☞ Unnamed가 중복이라 제거
data = data.iloc[:,1:]data.info()
▶ 월세가 0원인 경우 제외 / 위에 정보를 보면 보증금이 NaN값이 있기 때문에 제거해 주기
data = data.query('월세 > 0')data.dropna(inplace=True)data.info()
▶ 보증금 숫자로 변환
data['보증금'].unique()
# ~을 쿼리에서 사용시 제거 뜻
data = data.query('~보증금.str.contains("억")') #억은 제거# 숫자로 변경하기 위해 ','로 구분, astype에 int로 변환
data['보증금'] = data['보증금'].str.replace(',','').astype(int)
data['보증금'].unique()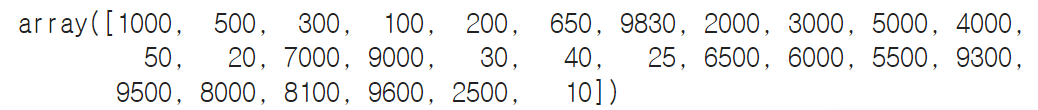
▶ 물건층과 전체층 분리 후 1층과 꼭대기층 유무 컬럼 만들기/ 지하의 경우 마이너스 표시
# expand를 사용하여 열을 생성
data[['물건층','전체층']] = data['층수(물건층/전체층)'].str.split('/', expand=True)
data['물건층'].unique()
def floor_info(target, total):
try:
if target in ['B1','B2']: # 지하이면
return 'y'
elif int(target) == 1 or int(target)/int(total) == 1: # 1층이거나 꼭대기층이면
return 'y'
else:
return 'n'
except ValueError:
return 'n'data.head()
# apply 함수를 사용해서 물건층, 전체층 가져오기
data['비선호층여부'] = data.apply(lambda x: floor_info(x['물건층'], x['전체층']), axis=1)data.head()
■ 질문에 대한 답 구하기
▶ 보증금 3000만원 이하 / 지하, 반지하, 꼭대기층, 북향 비선호
data_filtered = data.query('300 <= 보증금 <= 3000 and 비선호층여부 == "n" and 전체층 != "1" and ~방향.str.contains("북")')data_filtered
▶ 태그 컬럼 분리
# 태그에서 "\'|\[|\]"을 제거
data_filtered[['tag1','tag2','tag3']] = data_filtered['태그'].str.replace("\'|\[|\]","", regex=True) .str.split(', ', expand=True)
→ 쪼개서 보면
data_filtered['태그'].str.replace("\'|\[|\]|\[\]","", regex=True).str.split(', ', expand=True)
data_filtered.head()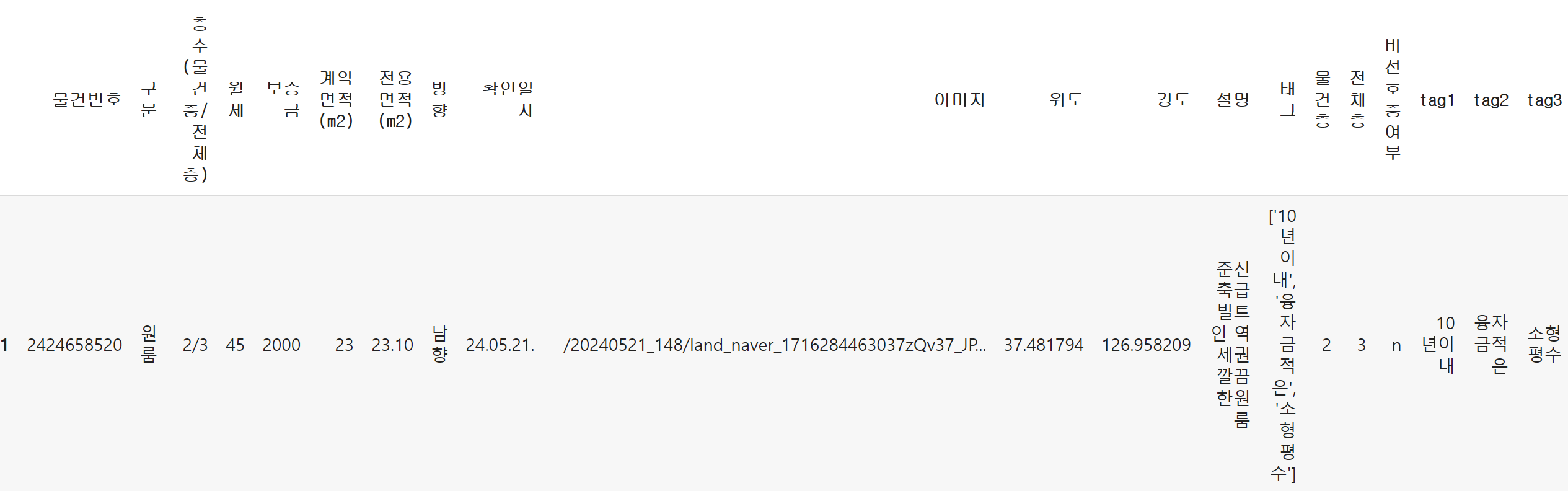
▶연식 컬럼 추가
data_filtered = data_filtered.query('tag1.str.contains("년")') #연식 정보가 있는 데이터만 필터링# tag1을 '년'으로 구분함
data_filtered['tag1'].str.split('년')
→ for문으로 '년'식으로 다시 만들기
data_filtered['연식'] = [int(i[0]) for i in data_filtered['tag1'].str.split('년')]
data_filtered
▶ 필요한 컬럼만 남기기
data_filtered.columns
data_filtered = data_filtered[['물건번호','월세','보증금','전용면적(m2)','방향','위도','경도','물건층','전체층','연식']]
data_filtered.head()
▶ 위도, 경도를 이용하여 역까지의 거리 재기
coordinate = pd.read_csv('/content/drive/~/서울시 역사마스터 정보.csv', encoding='cp949')
coordinate = coordinate.query('호선 == "2호선"')
station_list = ['신대방', '신림', '봉천', '서울대입구(관악구청)', '낙성대', '사당']
coordinate.query('역사명 in @station_list')
#위경도 거리 재는 라이브러리
!pip install haversinefrom haversine import haversine
haversine((37.487462,126.913149), (37.484201,126.929715), unit = 'm')
coordinate.query('역사명 == "신림"')['위도'].values[0]
coordinate.query('역사명 == "신림"')['경도'].values[0]def distance(station_name, lat, long):
station_lat = coordinate.query(f'역사명 == "{station_name}"')['위도'].values[0]
station_long = coordinate.query(f'역사명 == "{station_name}"')['경도'].values[0]
distance = haversine((station_lat, station_long), (lat, long), unit = 'm')
return distancefor s in station_list:
data_filtered[s] = data_filtered.apply(lambda x: distance(s, x['위도'], x['경도']), axis=1)data_filtered.head()
data_filtered['역까지최소거리'] = data_filtered.apply(lambda x: min([x['신대방'], x['신림'], x['봉천'], x['서울대입구(관악구청)'], x['낙성대'], x['사당']]), axis=1)
data_filtered.head()
data_filtered.drop(station_list, axis=1, inplace=True)
data_filtered.head()
■ 분석
☞ 각 항목 분포 확인하기
for x in ['월세','보증금','전용면적(m2)','연식','역까지최소거리']:
fig = px.box(data_frame = data_filtered, x=x, width=700, height=400)
fig.show()




☞ 월세, 전용면적, 연식, 지하철역까지의 거리 점수 매기기
data_filtered
data_filtered['월세_등급'] = pd.qcut(data_filtered['월세'], 5, labels=[1,2,3,4,5])
data_filtered['전용면적_등급'] = pd.qcut(data_filtered['전용면적(m2)'], 5, labels=[5,4,3,2,1])
data_filtered['연식_등급'] = pd.qcut(data_filtered['연식'].rank(method='first'), 5, labels=[1,2,3,4,5])
data_filtered['역까지최소거리_등급'] = pd.qcut(data_filtered['역까지최소거리'], 5, labels=[1,2,3,4,5])data_filtered
data_filtered_final = data_filtered.query('월세_등급 <= 3 and 전용면적_등급 <= 1 and 연식_등급 <= 2 and 역까지최소거리_등급 <= 2')
data_filtered_final
☞ 최종 매물 리스트 시각화
f = folium.Figure(width=700, height=500)
m = folium.Map(location=[37.486313, 126.935378], zoom_start=14).add_to(f)
for idx in data_filtered_final.index:
lat = data_filtered_final.loc[idx, '위도']
long = data_filtered_final.loc[idx, '경도']
num = data_filtered_final.loc[idx, '물건번호']
folium.Marker([lat, long]
, popup=f"<a href=https://m.land.naver.com/article/info/{num}>링크</a>"
).add_to(m)
m
◆ 부동산 뉴스기사 키워드 추출을 통한 연도별 이슈 분석
■ 필요한 라이브러리 다운로드
☞ 한글폰트 다운로드
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
☞ 크롤링 user_agent 생성 라이브러리 다운로드
!pip install user_agent
☞ 한글 형태소 분석기 다운로드
!pip install konlpy
!pip install mecab-python
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
■ 데이터 수집
☞ 2018년도부터 2023년 8월까지 '부동산' 키워드 뉴스 기사 크롤링
from user_agent import generate_user_agent, generate_navigator
user_agent = generate_user_agent()
user_agentimport requests
from bs4 import BeautifulSoup as bs
import pandas as pd
import random
import time
from tqdm.notebook import tqdmfirst_day = pd.date_range('2018-01-01', '2023-08-31', freq='MS').strftime('%Y.%m.%d') # 월 첫날
last_day = pd.date_range('2018-01-01', '2023-08-31', freq='M').strftime('%Y.%m.%d') # 월 마지막날
date_list = list(zip(first_day, last_day)) # 튜플형태로 저장되어짐keyword = '부동산'
data = pd.DataFrame()
for dt in tqdm(date_list):
dt1 = [dt[0].replace('.',''), dt[1].replace('.','')]
for num in range(1, 101, 10):
url = f'https://search.naver.com/search.naver?where=news&query={keyword}&sm=tab_opt&sort=0&photo=0&field=0&pd=3&ds={dt[0]}&de={dt[1]}&docid=&related=0&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so%3Ar%2Cp%3Afrom{dt1[0]}to{dt1[1]}&is_sug_officeid=0&office_category=0&service_area=1&start={num}'
user_agent = generate_user_agent()
headers = {'User-Agent':user_agent}
res = requests.get(url, headers=headers)
time.sleep(random.random())
soup = bs(res.text, 'html.parser')
title = [i.text for i in soup.find_all('a', class_='news_tit')]
link = [i['href'] for i in soup.find_all('a', class_='news_tit')]
press = [i.text for i in soup.find_all('a', class_='info press')]
temp = pd.DataFrame({'title':title, 'link':link, 'press':press, 'date_ym':dt1[0][:6]})
if len(title) < 1 : #크롤링이 아무것도 되지 않았으면 루프를 종료, 시간 텀을 가진 뒤 다시 크롤링
break
data = pd.concat([data, temp])
→ 수집되는 데이터 엑셀로 저장
data.to_excel('/content/drive/~/news_real_estate.xlsx')
■ 질문 만들기
- 연도별로 부동산 전망에 대한 뉴스 키워드는 어떻게 변화했는가?
- 위드클라우드로 시각화
■ 데이터 전처리
☞ 필요 없는 컬럼 제거 및 데이터 타입 변경
data = pd.read_excel('/content/drive/~/news_real_estate.xlsx')
data = data[['title','date_ym']]data['date_ym'] = data['date_ym'].astype(str)
data.info()data.head()
☞ 형태소 분석 : 문장에서 한글 형태소를 기준으로 단어를 분리
from konlpy.tag import Mecab
mecab = Mecab()data['NNG'] = data['title'].apply(lambda x: [i[0] for i in mecab.pos(x) if i[1] in ("NNG")])
data['year'] = data['date_ym'].apply(lambda x: int(x[:4]))
data.head()
from collections import Counter
nng_2018 = [j for i in data.query('year == 2018')['NNG'] for j in i if j not in ['부동산','전망','시장','집값','투자'] and len(j) > 1]
nng_2019 = [j for i in data.query('year == 2019')['NNG'] for j in i if j not in ['부동산','전망','시장','집값','투자'] and len(j) > 1]
nng_2020 = [j for i in data.query('year == 2020')['NNG'] for j in i if j not in ['부동산','전망','시장','집값','투자'] and len(j) > 1]
nng_2021 = [j for i in data.query('year == 2021')['NNG'] for j in i if j not in ['부동산','전망','시장','집값','투자'] and len(j) > 1]
nng_2022 = [j for i in data.query('year == 2022')['NNG'] for j in i if j not in ['부동산','전망','시장','집값','투자'] and len(j) > 1]
nng_2023 = [j for i in data.query('year == 2023')['NNG'] for j in i if j not in ['부동산','전망','시장','집값','투자'] and len(j) > 1]
nng_2018_dict = dict(Counter(nng_2018).most_common(100))
nng_2019_dict = dict(Counter(nng_2019).most_common(100))
nng_2020_dict = dict(Counter(nng_2020).most_common(100))
nng_2021_dict = dict(Counter(nng_2021).most_common(100))
nng_2022_dict = dict(Counter(nng_2022).most_common(100))
nng_2023_dict = dict(Counter(nng_2023).most_common(100))
■ 분석
import matplotlib.pyplot as plt
plt.rc('font', family='NanumGothic')
from wordcloud import WordCloud
path = '/user/share/fonts/truetype/nanum/NanumGothic.ttf'
wc = WordCloud(font_path = path,
background_color='white',
width=1000,
height=1000,
max_font_size=300)
dict_list = [nng_2018_dict, nng_2019_dict, nng_2020_dict, nng_2021_dict, nng_2022_dict, nng_2023_dict]
title_list = [i for i in range(2018, 2024)]
fig = plt.figure(figsize=(25,20))
for i in range(len(dict_list)):
wc.generate_from_frequencies(dict_list[i]) #워드클라우드 생성
ax = fig.add_subplot(2,3,i+1)
ax.imshow(wc, interpolation='bilinear')
ax.set_xlabel(f'{title_list[i]}') #그래프 제목 출력
ax.set_xticks([]), ax.set_yticks([]) #x축, y축을 없앰
plt.imshow(wc, interpolation='bilinear')
fig.suptitle('부동산 뉴스 제목 키워드')
fig.tight_layout()
plt.show()
◆ 타이타닉 데이터 분석
☞ 타이타닉 데이터 가져오기
import pandas as pd
df = pd.read_csv('titanic.csv')
df
☞ matplotlib, seaborn 시각화 사용하기 위해 import 해주기
import matplotlib.pyplot as plt
import seaborn as snssns.histplot(df['Age'], bins=11, kde=True)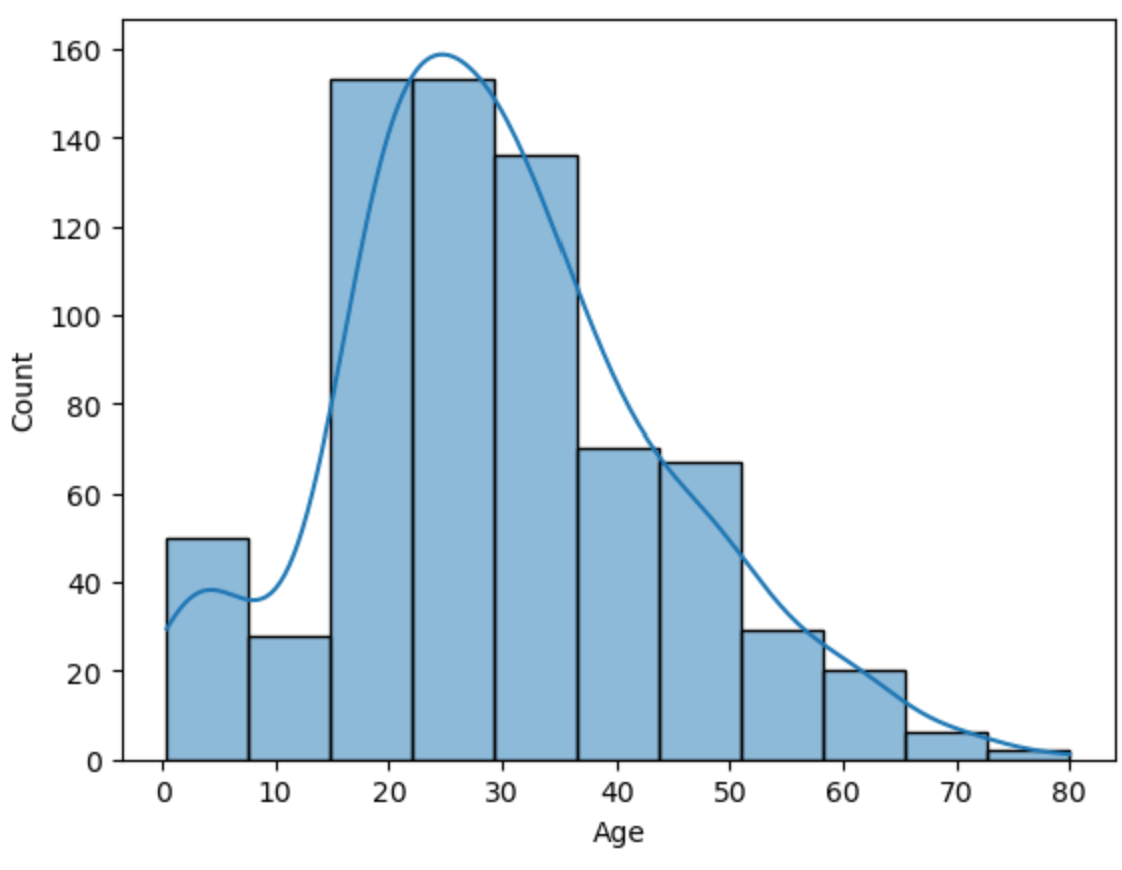
df['Age'].value_counts()
sns.countplot(x=df['Age'])sns.countplot(data=df, x='Age')
sns.histplot(df['Age'], bins=10)
# 0~8세 : child
# 9~19세 : Student
# 20~35세 : Young Adult
# 36~50세 : Adult
# 50세 ~ : Senior
df['Age Category']
df['Age'] = df['Age'].fillna(df['Age'].mean())
df['Age'].isna().sum()
☞ 서울 인구 데이터
☞ 라이브러리 설치
!pip install xlrd→ 위에 실행하고 아래코드 실행하면 xlrd 에러 확인 설치 진행

☞ 엑셀파일 불러오기(pd.read.excel)
import pandas as pd
df = pd.read_excel('seoul_popular_data.xls')
df
→ 보고 싶은 컬럼만 가지고 와서 df 저장
import pandas as pd
df = pd.read_excel('seoul_popular_data.xls', header=1)
# 필요한 컬럼만 뽑아오기
cols = ['자치구', '합계', '한국인', '등록외국인', '세대당인구', '65세이상고령자']
df = df[cols]
df.drop([0], inplace=True)
df.drop([1], inplace=True)
df
☞ index 만들기
df = df.reset_index()
df
☞ 위에 보면 인덱스값이 중복이라 제거
df = df.drop(['index'], axis=1)
df
☞ EX) 쉘터에 외국인이 많은 곳에 외국인 쉘터를 설치하려고 함.
- 어디에 설치하는게 좋을지?
df.sort_values('등록외국인', ascending=False)
df['외국인비율'] = df['등록외국인'] / df['합계'] * 100
df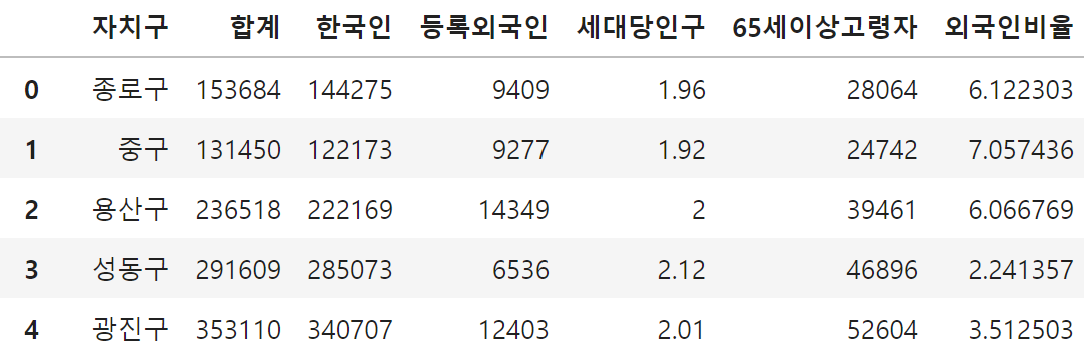
→ 이렇게도 가능
df.sort_values('외국인비율', ascending=False)
→ 확인해 보니 Dtype이 문자형
df.info()
☞ 1) 컬럼 이름 변경
- 자치구 -> 구, 합계 -> 인구수, 등록외국인 -> 외국인, 65세 이상고령자 -> 고령자
df.columns = ['구', '인구수', '한국인', '외국인', '세대당인구', '고령자', '외국인비율']
df
☞ 2) 데이터 타입 변경
- 구 제외 나머지 숫자 데이터를 int로 변경
df.info()
df['인구수'] = df['인구수'].astype('int')
df['한국인'] = df['한국인'].astype('int')
df['외국인'] = df['외국인'].astype('int')
df['세대당인구'] = df['세대당인구'].astype('int')
df['고령자'] = df['고령자'].astype('int')
df.info()
☞ 외국인 비율 구하기
df['외국인비율'] = round(df['외국인'] / df['인구수'] * 100, 1) # 소수 둘째자리에서 반올림
☞ 고령자 비율 구하기
df['고령자비율'] = round(df['고령자'] / df['인구수'] * 100, 1)
☞ 고령자 비율로 오름차순 정렬
df.sort_values(by='고령자비율', ascending=False)
☞ matplotlib으로 시각화
df_gu = df.set_index('구')
import matplotlib.pyplot as plt
plt.rcParams['font.family']='Malgun Gothic'
#plt.rcParams['font.family']='AppleGothic'
df_gu['인구수'].sort_values().plot(kind='barh', grid=True)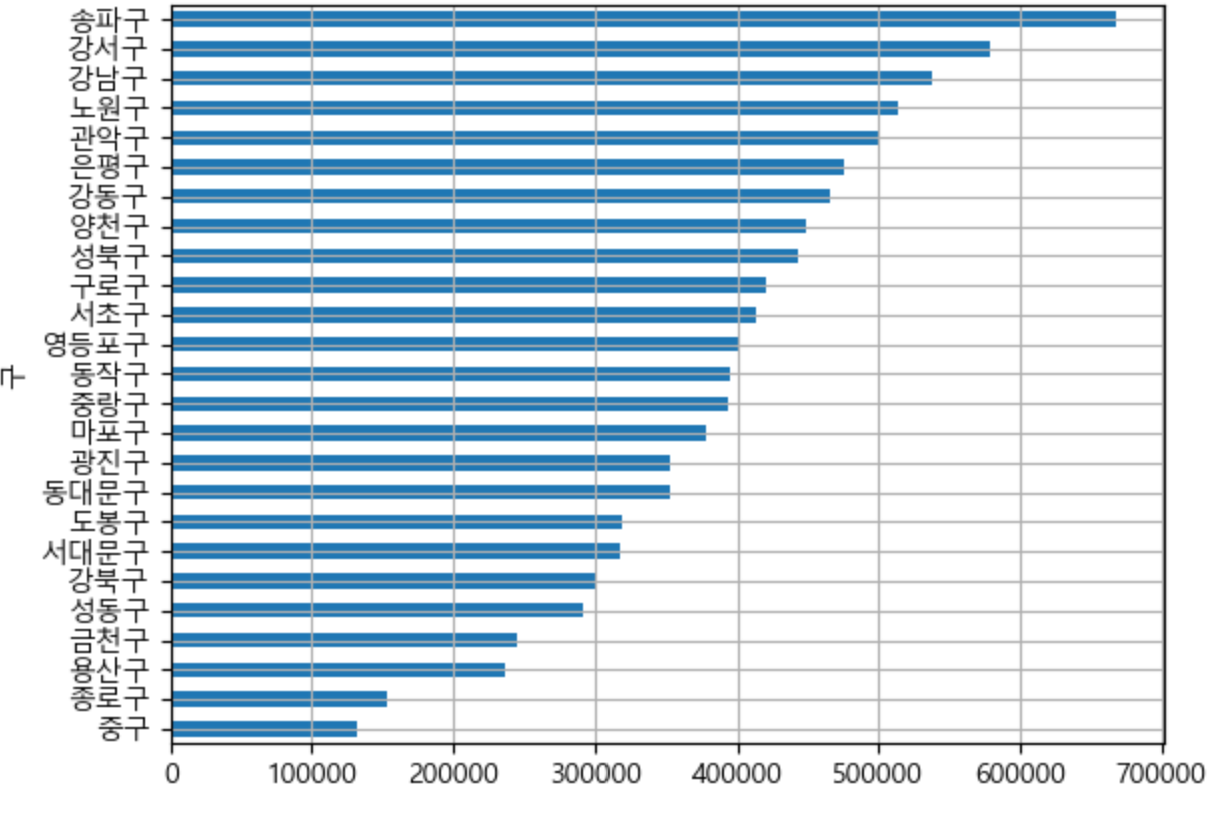
→ 결론
- 서울시에서 가장 많은 인구가 있는 구는 '송파구', 가장 적은 인구가 있는 구는 '중구'
- 송파구의 인구는 약 65만명, 중구는 13만명 정도이다.
☞ 서울시 Top10 인구를 막대그래프로 그리기
# matplotlib
df.sort_values(by='인구수').tail(10)
plt.bar()
→ 위와 아래 중 난 정렬도 되는게 보기 좋아서 아래코드를 선택
df_top10 = df.sort_values(by='인구수', ascending=False).head(10)
df_top10
plt.bar()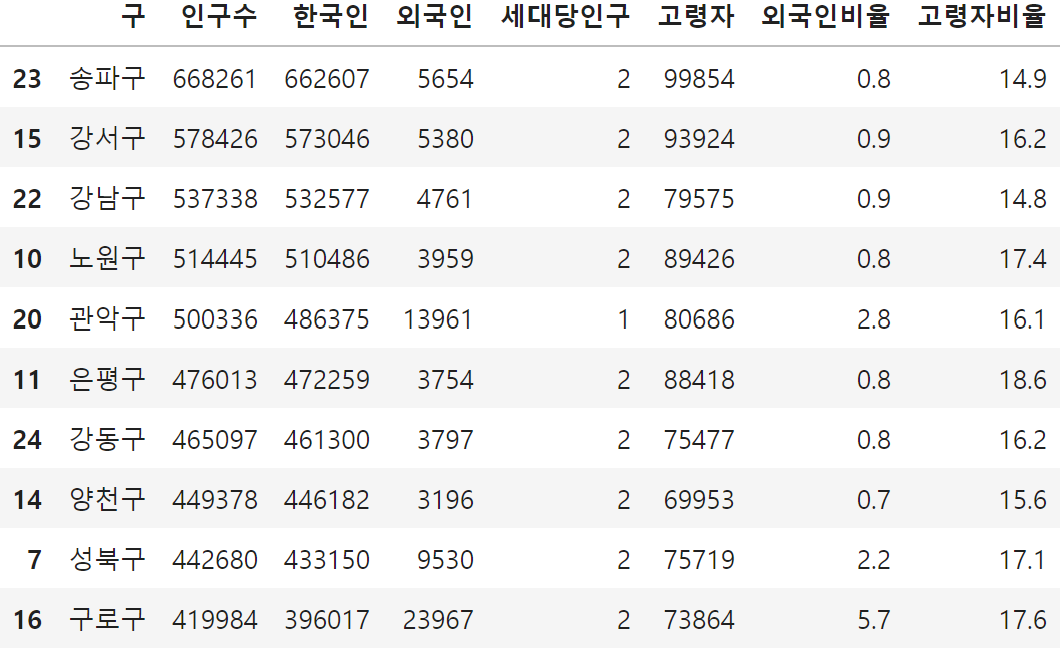
☞ 신용카드 결제 데이터
☞ 라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
☞ 신용카드 결제 데이터 파일 불러오기
df = pd.read_csv('UCI_Credit_Card.csv')
df
☞ 컬럼 설명
ID: 각 고객의 ID
LIMIT_BAL: 신용 한도 (NT 달러, 개인 및 가족/보조 신용 포함)
SEX: 성별 (1=남성, 2=여성)
EDUCATION: 교육 수준 (1=대학원, 2=대학교, 3=고등학교, 4=기타, 5=알 수 없음, 6=알 수 없음)
MARRIAGE: 결혼 상태 (1=기혼, 2=미혼, 3=기타)
AGE: 나이 (년 단위)
PAY_0 to PAY_6: 2005년 4월부터 9월까지의 상환 상태 (-1=정상 상환, 1=1개월 연체, 2=2개월 연체, ... 8=8개월 연체, 9=9개월 이상 연체)
BILL_AMT1 to BILL_AMT6: 2005년 4월부터 9월까지의 청구서 금액 (NT 달러)
PAY_AMT1 to PAY_AMT6: 2005년 4월부터 9월까지의 이전 결제 금액 (NT 달러)
default.payment.next.month: 다음 달 연체 여부 (1=연체, 0=정상)
df.info()
☞ 가설 세우기
일변량 EDA
가설 : 나이가 많은 고객일수록 연체율이 높을 가능성이 있다.
가설 : 교육 수준이 높은 고객일수록 연체율이 낮을 가능성이 있다.
가설 : 결혼 여부가 연체율에 영향을 미칠 수 있다.
☞ 필요한 데이터만 가져오기 위해 컬럼 확인
df.columns
☞ 필요한 컬럼만 가지고 오기
need_cols = ['ID', 'LIMIT_BAL', 'SEX', 'EDUCATION', 'MARRIAGE', 'AGE', 'default.payment.next.month']
# df에 가져온 컬럼 저장
df = df[need_cols]
☞ 가져온 컬럼명 변경
df.columns = ['ID', '신용한도', '성별', '학력', '결혼 여부', '나이', '연체여부']
☞ 컬럼 데이터값 변경
조건
1) 성별 : 1-> male, 2-> female
2) 학력 : 1-> Graduate School, 2->University, 3-> HighSchool, 4-> Etc, 5-> Etc, 6-> Etc, 0-> Etc
3) 결혼 여부 : 1-> Married, 2-> Single, 3-> Etc, 0-> Etcdf['학력'].unique()→ unique 조회해서 조건을 만들기

# 1) 성별
df['성별'] = df['성별'].replace({
1: 'Male',
2: 'Female'
})
df
# 학력 바꾸기
df['학력'] = df['학력'].map({
1: 'Graduate School',
2: 'University',
3: 'HighSchool',
4: 'Etc',
5: 'Etc',
6: 'Etc',
0: 'Etc'
})# 결혼 여부 바꾸기
df['결혼 여부'] = df['결혼 여부'].map({
1: 'Married',
2: 'Single',
3: 'Etc',
0: 'Etc'
})
☞ 가설에 ID는 상관이 없어서 빼고 불러오기
# ID컬럼은 필요 없기 때문에 빼고 불러오기
df = df[['신용한도', '성별', '학력', '결혼 여부', '나이', '연체여부']]
df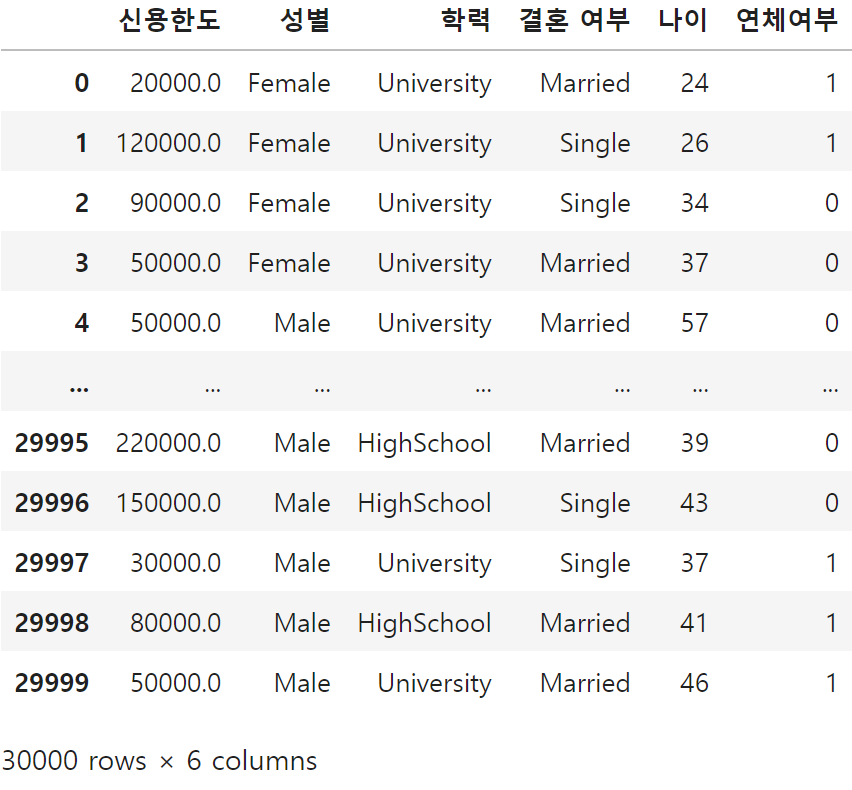
☞ 가설1 ) 나이가 많은 고객일수록 연체율이 높을 가능성이 있다.
df['나이'].value_counts()
▶ 나이대로 나누기
bins_age = [20, 30, 40, 50, 60, 70, 80]
labels_age = ['20s', '30s', '40s', '50s', '60s', '70s'] # 6개 구간
df['나이_그룹'] = pd.cut(df['나이'], bins=bins_age, labels=labels_age)df_age_group = df.groupby('나이_그룹')['연체여부'].mean().reset_index()
df_age_group→ 나이 컬럼을 "나이_컬럼"으로 변경, 나이 그룹별 연체여부에 평균을 구해서 그룹화하기

▶ barplot으로 시각화
plt.rc('font', family='Malgun Gothic')
sns.barplot(data=df_age_group, x='나이_그룹', y='연체여부')
'데이터분석 부트캠프' 카테고리의 다른 글
| 데이터분석 부프캠프 14기 - 7주차_MySQL (1) | 2024.06.08 |
|---|---|
| Python 프로젝트 (0) | 2024.06.05 |
| 데이터분석 부프캠프 14기 - 4주차 (0) | 2024.05.17 |
| 데이터분석 부프캠프 14기 - 3주차 (0) | 2024.05.08 |
| Python 주피터 설치 방법 & 가상환경 설정 (0) | 2024.05.03 |


