◆ 목차
- 데이터분석 & 프로젝트 연습실습
- 여러 웹 크롤링
- Jupyter & Pandas
데이터분석
1. 데이터 시각화(3주차 이어서)
◆ Plotly
■ 문법
fig = px.그래프 종류(data_frame=데이터, x=x축 컬럼, y=y축 컬럼, color=범례 컬럼, title=제목, labels=dict(X출 컬럼=X축 라벨, Y축=Y축 라벨), width=그래프 가로길이, height=그래프 세로길이, text_auto=True/False)
fig.show()
# plotly 라이브러리 가져오기
import plotly.express as px
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns☞ Plotly
fig = px.bar(data_frame=df_groupby1, x='island', y='body_mass_g', color='sex', barmode='group', text_auto='.0d', width=700, height=500, title='island별 몸무게 평균', labels=dict(body_mass_g='몸무게(g)', island='', sex='성별'))
fig.show()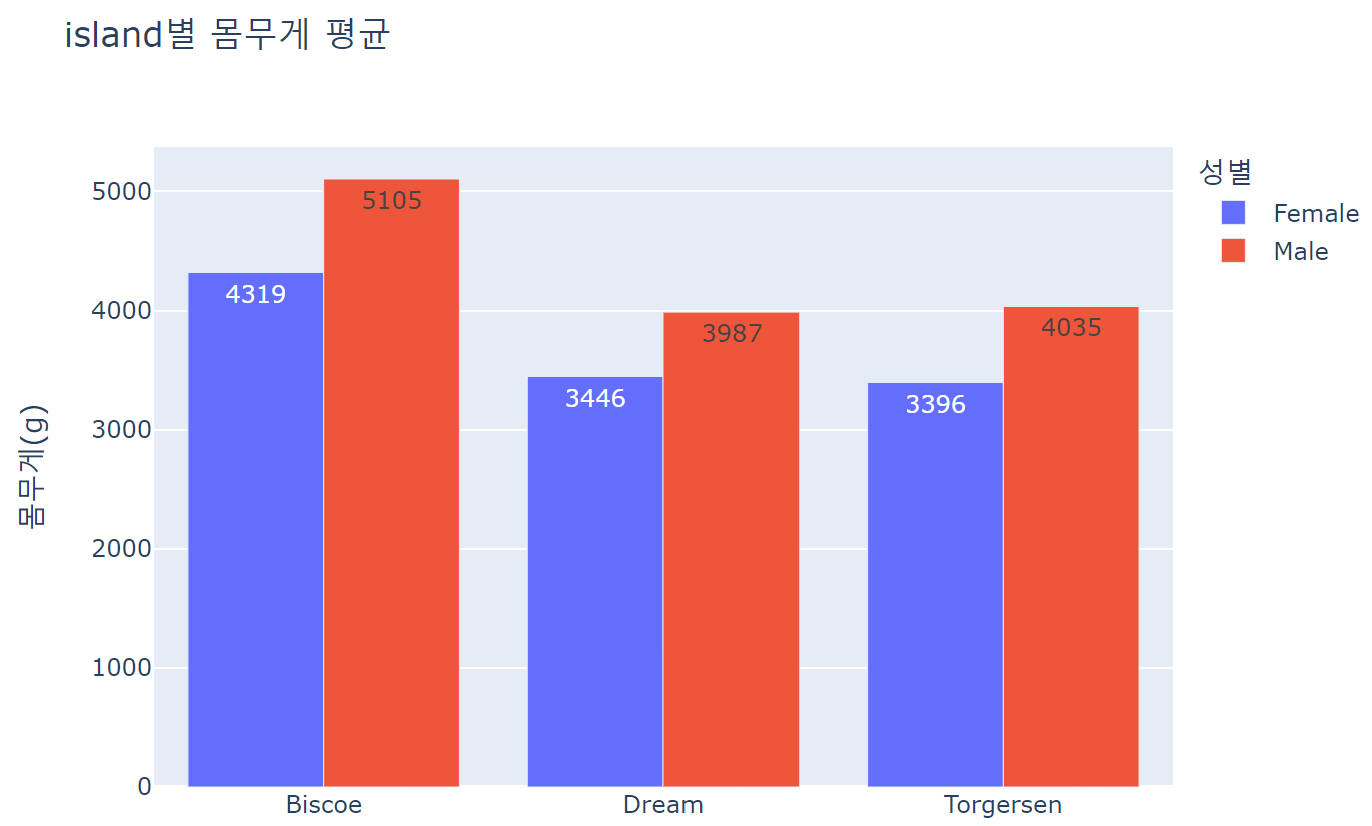
■ 스타일 설정
- template = 템플릿명
- color_discrete_sequence = 컬러맵명 : 범주형 데이터
- color_continuous_scale = 컬러맵명 : 연속형 데이터
☞ 여러가지 스타일의 template 적용
for temp in ['ggplot2', 'seaborn', 'simple_white', 'plotly', 'plotly_white', 'plotly_dark']:
fig = px.bar(data_frame=df_groupby1, x='island', y='body_mass_g', color='sex', barmode='group', text_auto='.0d', width=700, height=500, title=f'템플릿: {temp}', labels=dict(body_mass_g='몸무게(g)', island='', sex='성별'), template=temp)
fig.show()
☞ 여러가지 컬러맵 적용
fig = px.colors.sequential.swatches_continuous()
fig.show()fig = px.colors.qualitative.swatches()
fig.show()# 한가지만 적용하고 싶다면, for문은 제거하고 color_discrete_sequence에 스타일 넣기
for color_map in [px.colors.qualitative.Pastel1, px.colors.qualitative.Safe, px.colors.qualitative.Antique]:
fig = px.bar(data_frame=df_groupby1, x='sex', y='body_mass_g', color='island', barmode='group', text_auto='.0d', width=700, height=500, color_discrete_sequence=color_map)
fig.show()
for color_map in [px.colors.sequential.Burg, px.colors.sequential.Mint, px.colors.sequential.PuBuGn]:
fig = px.scatter(data_frame=df, x='bill_length_mm', y='bill_depth_mm', color='flipper_length_mm', width=700, height=500, color_continuous_scale=color_map, template='simple_white')
fig.show()
■ HTML 파일로 저장
- fig.write_html(파일경로 및 파일명)
fig = px.scatter(data_frame=df, x='bill_length_mm', y='bill_depth_mm', color='flipper_length_mm', width=700, height=500, color_continuous_scale=px.colors.sequential.PuBuGn, template='plotly_white')
fig.show()
fig.write_html('test.html')
◆ plotly 유형별 그래프
■ 산점도
- px.scatter(data_frame=데이터, x=x축 컬럼, y=y축 컬럼, color=색, trendline='ols')
- trendline : 추세선
☞ 일반 산점도 적용
fig = px.scatter(data_frame=penguins, x='bill_length_mm', y='bill_depth_mm'
, color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()
☞ 성별에 따라 색구분 산점도
fig = px.scatter(data_frame=penguins, x='bill_length_mm', y='bill_depth_mm', color='sex'
, color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()
☞ 점 모양 구분 : symbol
fig = px.scatter(data_frame=penguins, x='bill_length_mm', y='bill_depth_mm', color='island', symbol='sex'
, color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()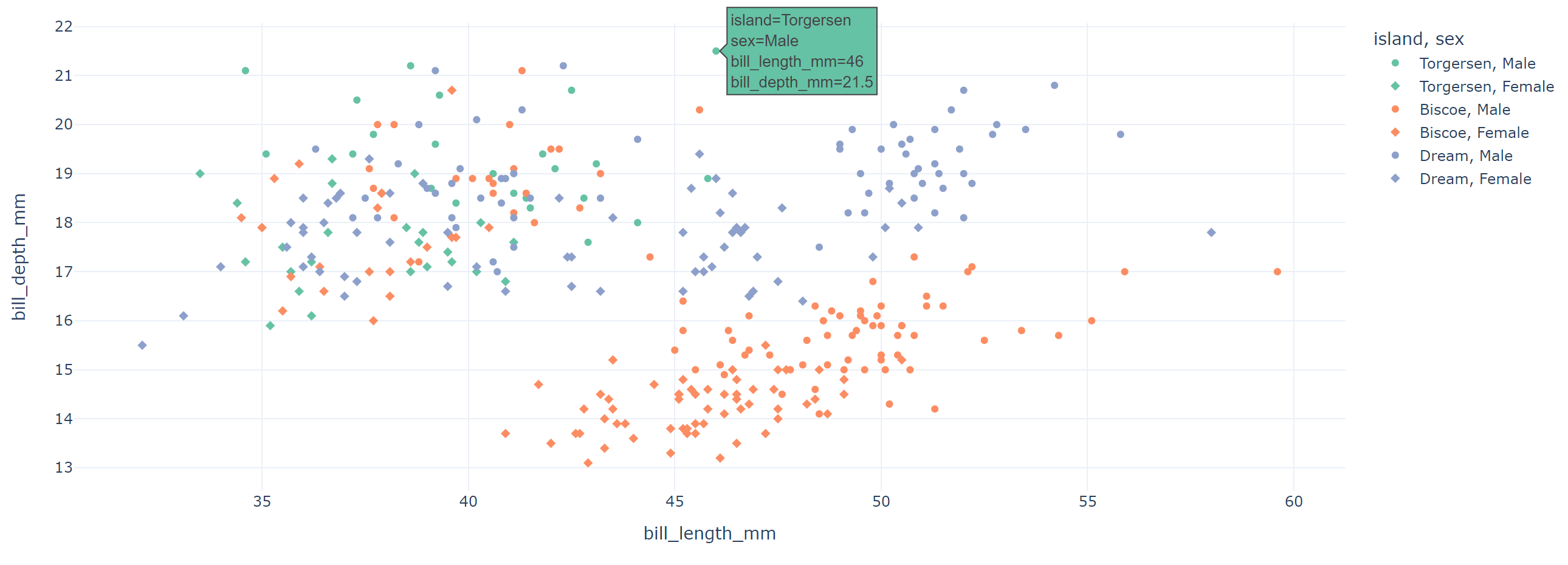
☞ 구역별 추세선
fig = px.scatter(data_frame=penguins, x='bill_length_mm', y='bill_depth_mm', color='sex', facet_col='island', trendline='ols'
, color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()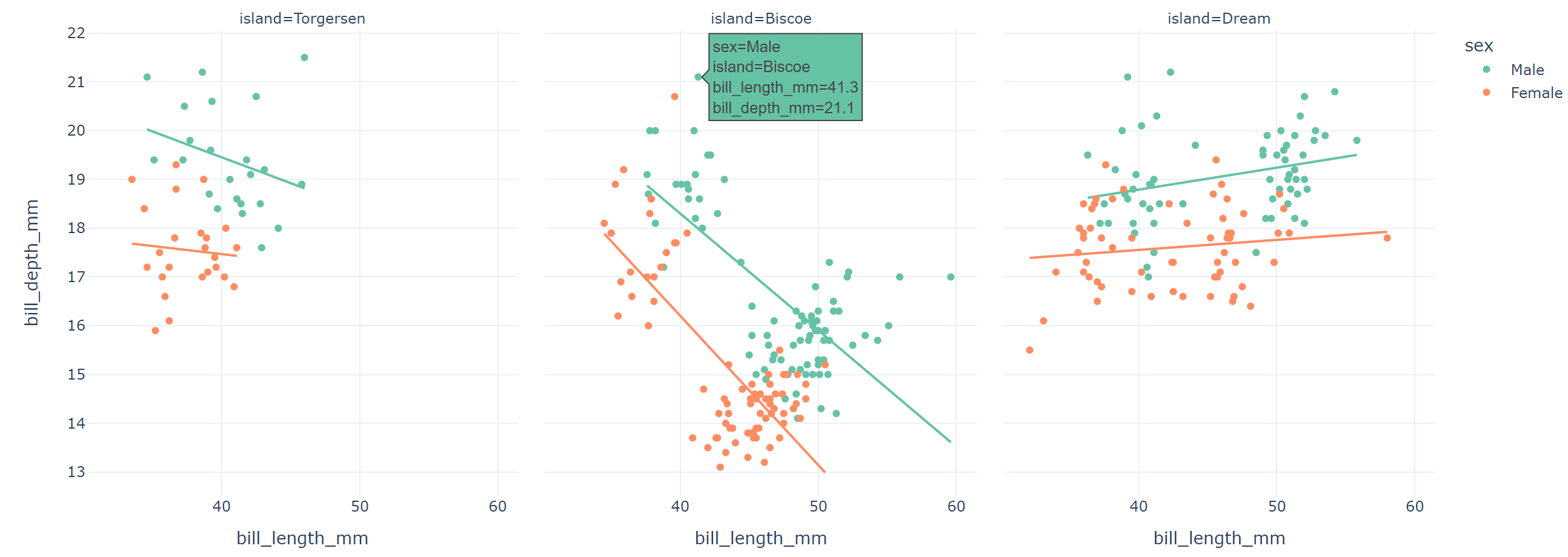
■ 분포
- px.histogram(data_frame=데이터, x=x축 컬럼, color=색) : 히스토그램
- px.box( data_frame=데이터, x=x축 컬럼, y=y축 컬럼, color=색) : 상자그림
☞ 히스토그램
fig = px.histogram(data_frame=penguins, x='flipper_length_mm', color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()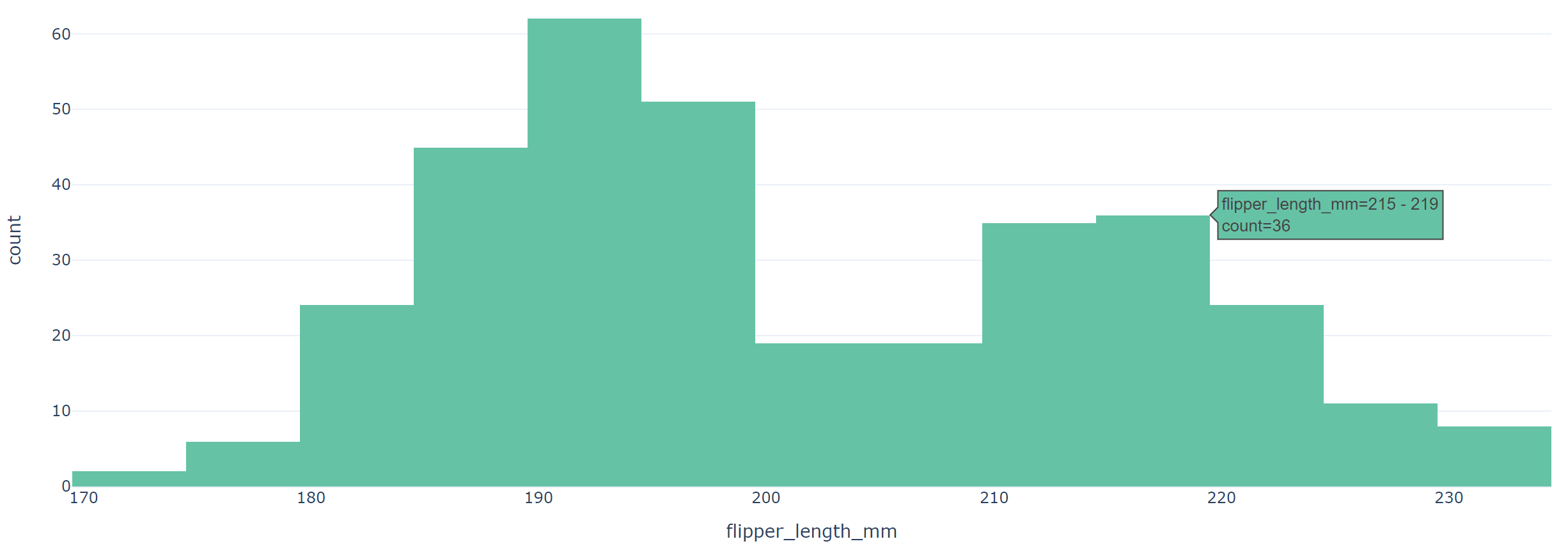
☞ 상자그림
fig = px.box(data_frame=penguins, x='body_mass_g', y='species', color='sex'
, color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()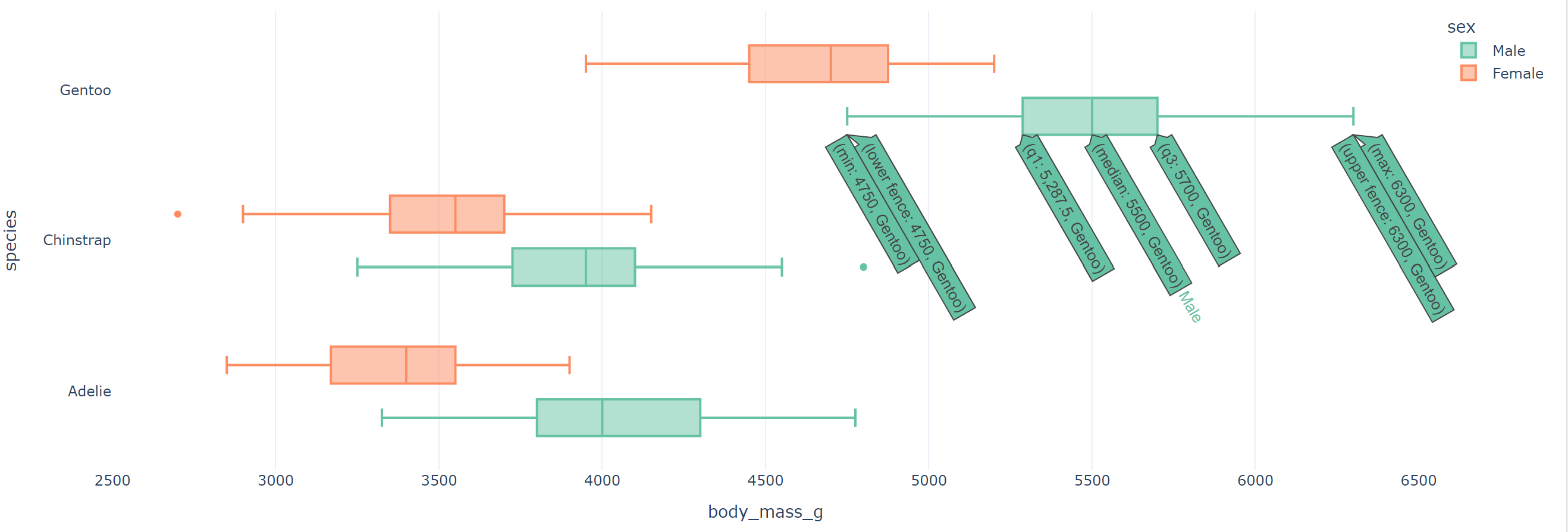
■ 막대그래프
- px.bar(data_frame=데이터, x=x축 컬럼, y=y축 컬럼, color=색, barmode='group') : 누적이 싫다면 barmode 안 넣기
☞ barmode 넣어서 그래프
fig = px.bar(data_frame=titanic_groupby, x='class', y='survived', color='sex', barmode='group'
, color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()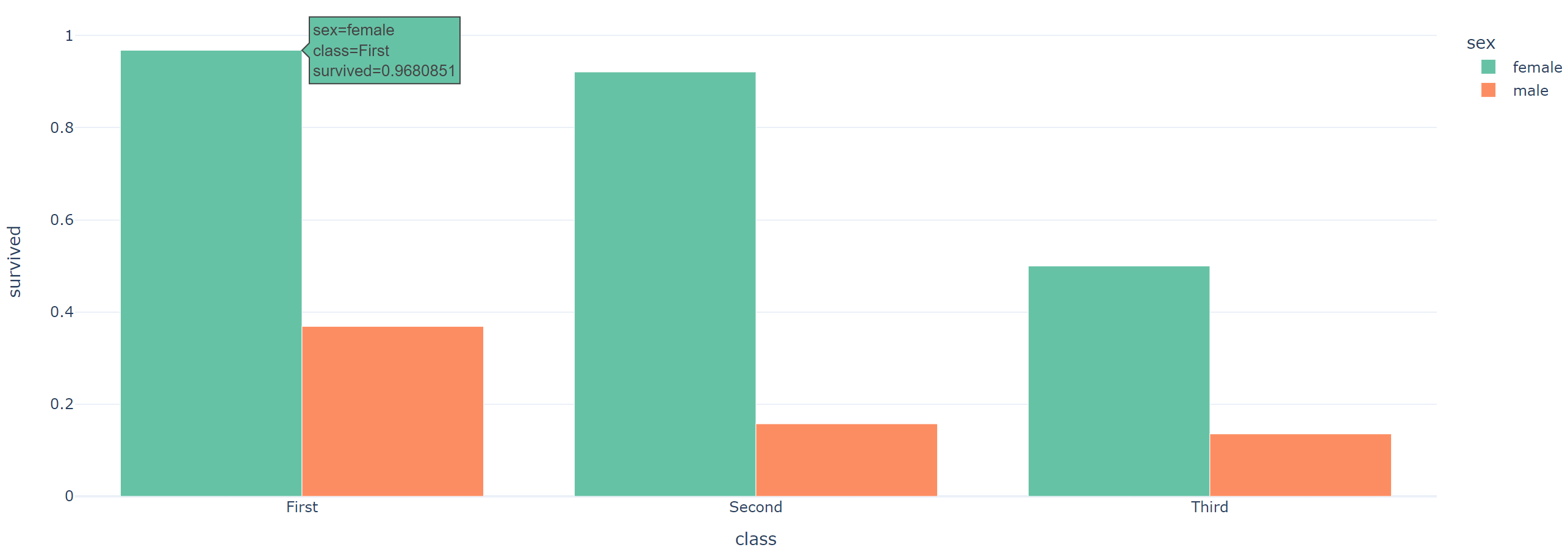
☞ barmode 없이 누적 그래프
fig = px.bar(data_frame=titanic_groupby, x='class', y='survived', color='sex'
, color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()
■ 선그래프
- px.line(data_frame=데이터, x=x축 컬럼, y=y축 컬럼, color=색)
☞연도별 5월에 대한 passengers 데이터
may_flights = flights.query('month == "May"')
fig = px.line(data_frame=may_flights, x="year", y="passengers"
, color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white')
fig.show()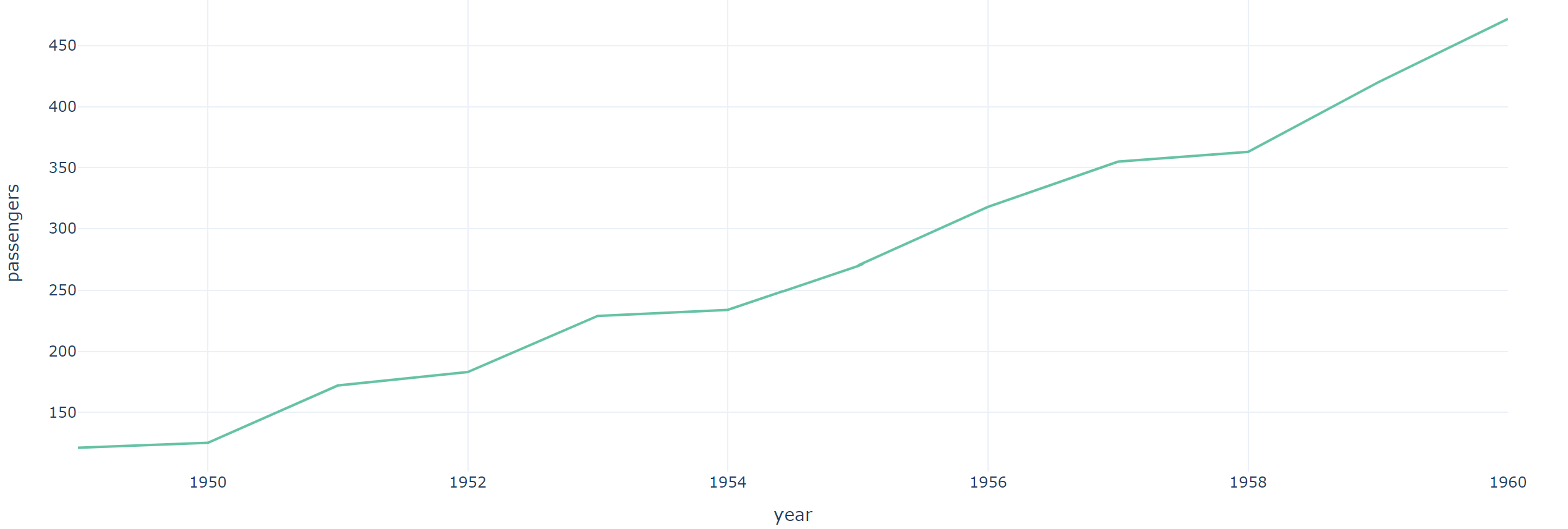
■ 히트맵
- px.imshow(데이터, text_auto=덱스트포맷(원하는 숫자 형식을 뜻함), color_continuous_scale=컬러맵)
☞ 상관관계 그래프
titanic_corr = titanic[['survived','age','fare','sibsp','pclass']].corr()
titanic_corr
# titanic_corr에 대한 상관관계 그래프
fig = px.imshow(titanic_corr, text_auto='.2f', color_continuous_scale='YlOrBr')
fig.show()
■ 파이차트
- px.pie(data_frame=데이터, values=값, names=라벨)
☞ day별 파이차트
fig = px.pie(df, values='tip', names='day', color_discrete_sequence=px.colors.qualitative.Pastel)
fig.show()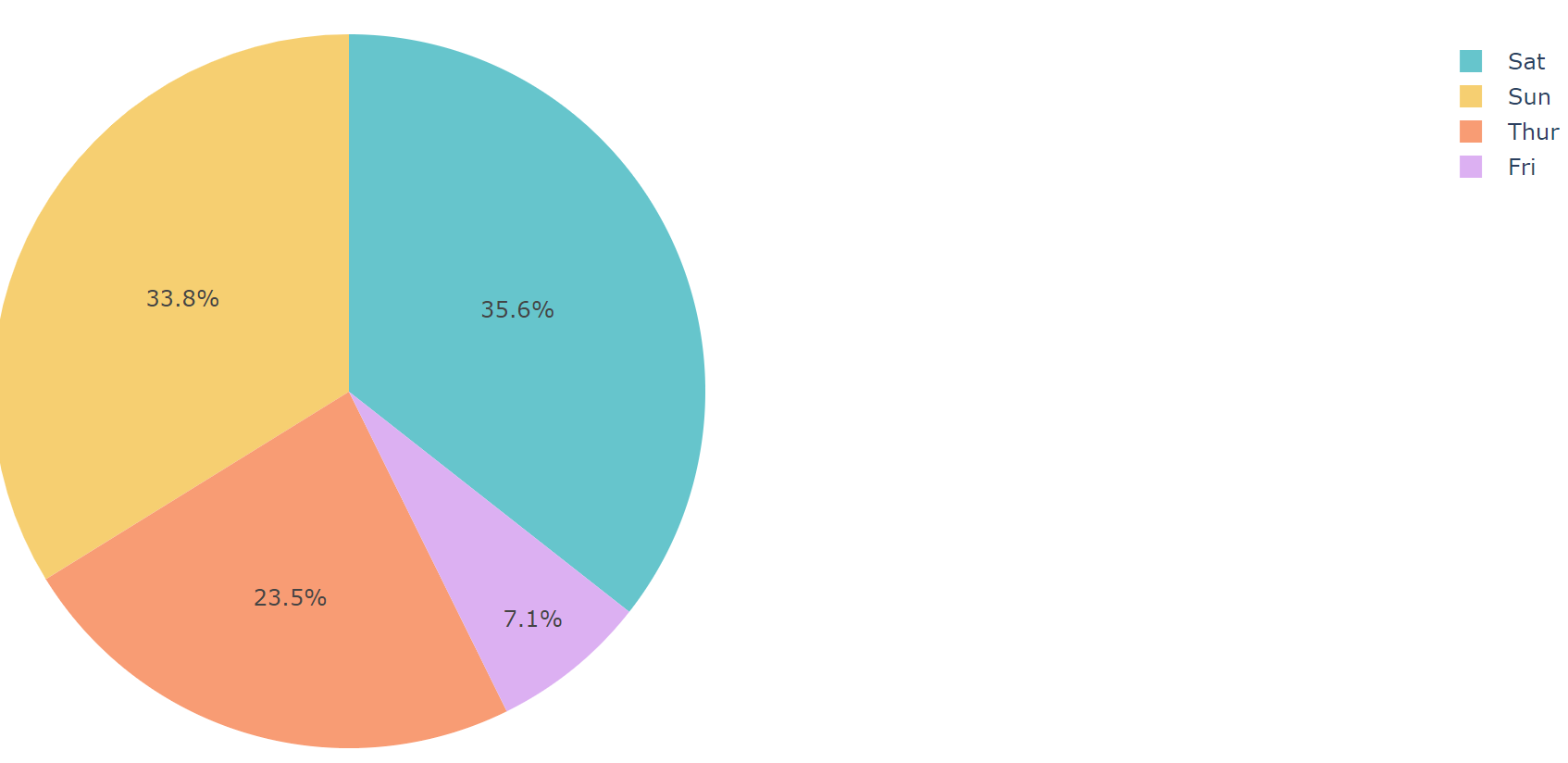
◆ folium
# 라이브러리 사용
import folium
■ 특정 장소의 지도 시각화하기
f = folium.Figure(width=가로길이, height=세로길이)
m = folium.Map(location=[위도, 경도], zoom_satart=줌 할 정도). add_to(f)
m.save('test.html') : 지도 저장
m
☞ 용산아이파크몰 지도 시각화
f = folium.Figure(width=700, height=500)
m = folium.Map(location=[37.52942459999984, 126.9609825539374], zoom_start=16).add_to(f)
m
■ 마커 추가하기
① 장소 표시 마커
folium.Marker([위도, 경도]
,tooltip=마우스 오버시 나타남
,popup=클릭시 나타남
,icom=folium.lcon(color=색, icon=모양)).add_to(지도)
② 원 형태 마커
folium.CircleMarker([위도, 경도]
,radius=범위
,color=색).add_to(지도)☞ 용산아이파크몰 지도에 마커 표시
folium.Marker([37.52942459999984, 126.9609825539374]
, tooltip='용산아이파크몰').add_to(m)
m
☞ 용산아이파크몰 지도에 아이콘 변경해서 마커 표시
folium.Marker([37.52942459999984, 126.9609825539374]
, tooltip='용산아이파크몰'
, icon = folium.Icon(color='red', icon='star')).add_to(m)
m
☞ 용산아이파크몰 지도에 표시된 마커 클릭 시 사진 표시
folium.Marker([37.52942459999984, 126.9609825539374]
, tooltip='용산아이파크몰'
, icon = folium.Icon(color='red', icon='star')
, popup = '<iframe src="https://i.namu.wiki/i/7sRsagrjCGu4QAC6CbGHWy0oax9GByWDjn_1LBnznl2Avvs3pHDkNDHL5YIId0tGIoFohVxiChyx7Fjfk3QpQaLSWf2Fs1VIDeuljChMyOPst5xruuGuyENW4Zl35b2_NQlM0bno8a_TwZ2Lk2_OLg.webp"></iframe>').add_to(m)
m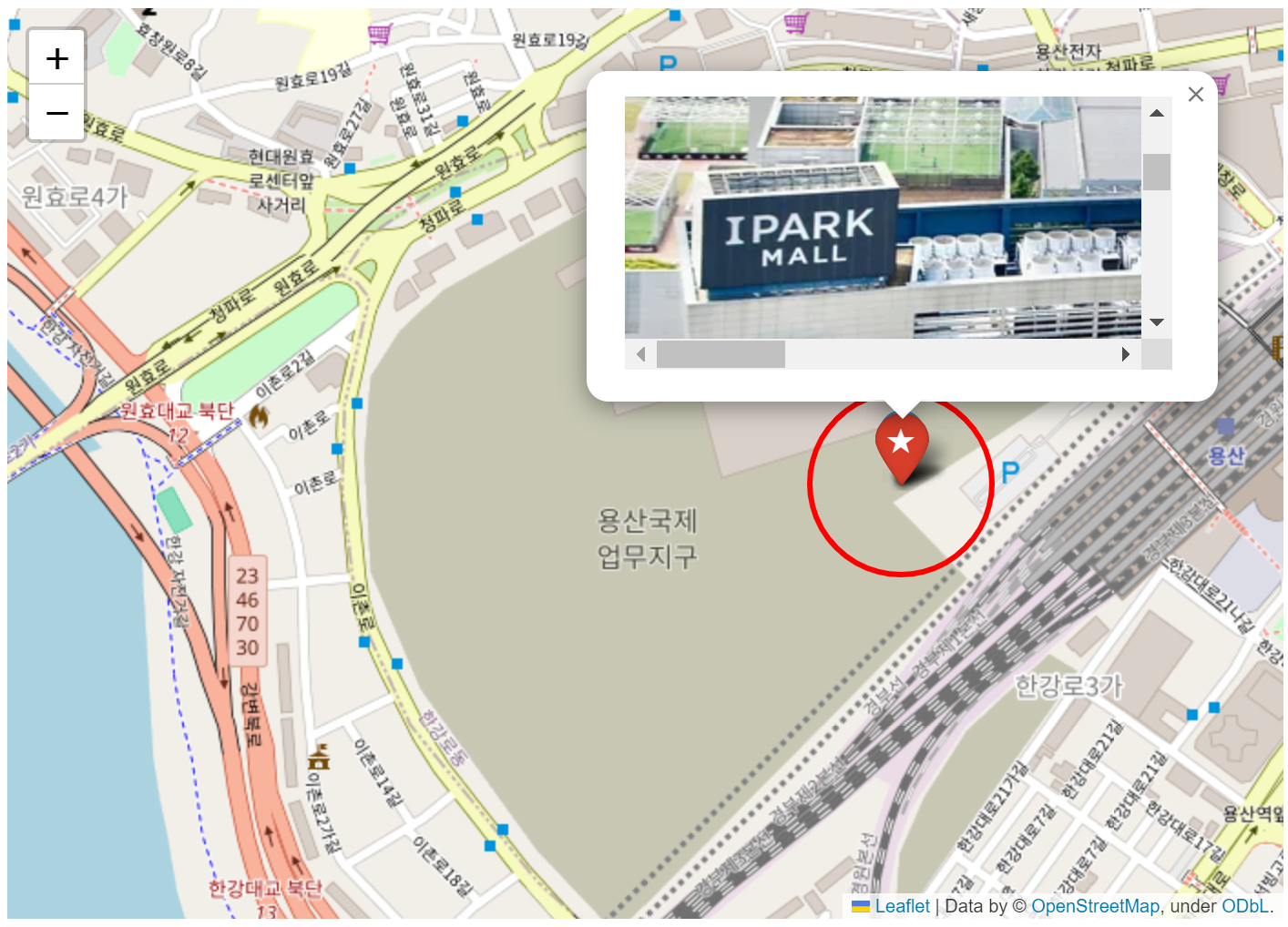
☞ 용산아이파크몰 지도에 원 형태 마커 표시
folium.CircleMarker([37.52942459999984, 126.9609825539374]
, color = 'red'
, radius = 50).add_to(m)
m
■ folium으로 지리 데이터 시각화
# 라이브러리 사용
import json
import folium
import pandas as pd
☞서울시 구별 경계 데이터 가져오기
# 종로구에 대한 서울시 경계 데이터 json 파일 불러오기
geo_path = '/content/drive/MyDrive/Python/Part2) 파이썬을 이용한 데이터 분석/Part2) 파이썬을 이용한 데이터 분석/data/seoul_municipalities_geo_simple.json'
geo_json = json.load(open(geo_path, encoding='utf-8'))
☞서울시 상가 정보 데이터 가져오기(포털에서 csv파일 다운로드하여서 사용)
- 공공데이터포털
df = pd.read_csv('/content/drive/MyDrive/Python/Part2) 파이썬을 이용한 데이터 분석/Part2) 파이썬을 이용한 데이터 분석/data/소상공인시장진흥공단_상가(상권)정보_서울_202306.csv', low_memory=False)
☞ 카페별로 데이터를 전처리하고 EDA 하기(이디야, 투썸플레이스)
- 이디야
cafe = df.query('상권업종소분류명 == "카페"')ediya = cafe.loc[cafe['상호명'].str.contains('이디야'),]
ediya# 이디야 시군구명에 따른 수, 'count', ascending=False은 count를 기준으로 내림차순
ediya_count = ediya.groupby('시군구명').size().to_frame().reset_index().rename({0:'count'}, axis=1).sort_values('count', ascending=False)
ediya_count
→ 이디야 점포수 시각화
import plotly.express as px
fig = px.bar(data_frame=ediya_count, x='시군구명', y='count', color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white', text_auto=True, title='서울시 구별 이디야 점포수')
fig.show()
- 투썸플레이스
twosome = cafe.loc[cafe['상호명'].str.contains('투썸플레이스'),]
twosometwosome_count = twosome.groupby('시군구명').size().to_frame().reset_index().rename({0:'count'}, axis=1).sort_values('count', ascending=False)
twosome_count
→ 투썸플레이스 점포수 시각화
fig = px.bar(data_frame=twosome_count, x='시군구명', y='count', color_discrete_sequence=px.colors.qualitative.Set2, template='plotly_white', text_auto=True, title='서울시 구별 투썸플레이스 점포수')
fig.show()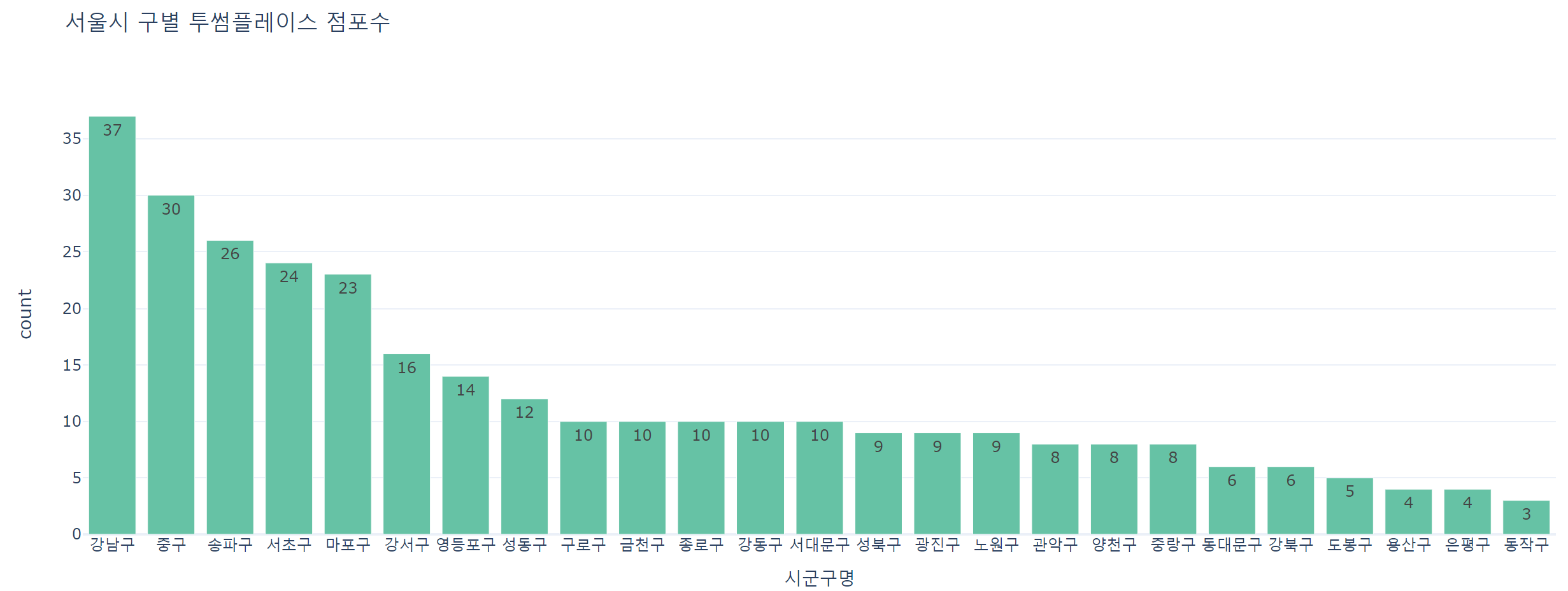
■ folium으로 지도에 시각화하기
☞ 서울시 위도와 경도 설정
f = folium.Figure(width=700, height=500)
m = folium.Map(location=[37.566535, 126.9779692], zoom_start=11).add_to(f)
m
☞ 서울시 구별 경계 데이터 표시
folium.Choropleth(geo_data = geo_json, fill_color = 'gray').add_to(m)
m
☞ 서울시 구별 이디야 매장수
f = folium.Figure(width=700, height=500)
m = folium.Map(location=[37.566535, 126.9779692], zoom_start=11).add_to(f)
folium.Choropleth(geo_data = geo_json #서울시 경계 데이터 넣기
, data=ediya_count
, columns=['시군구명', 'count']
, key_on='properties.name'
, fill_color = 'YlGn' # 색상
, fill_opacity = 0.7 # 투명도
, line_opacity = 0.7
, legend_name = '서울시 구별 이디야 매장수').add_to(m)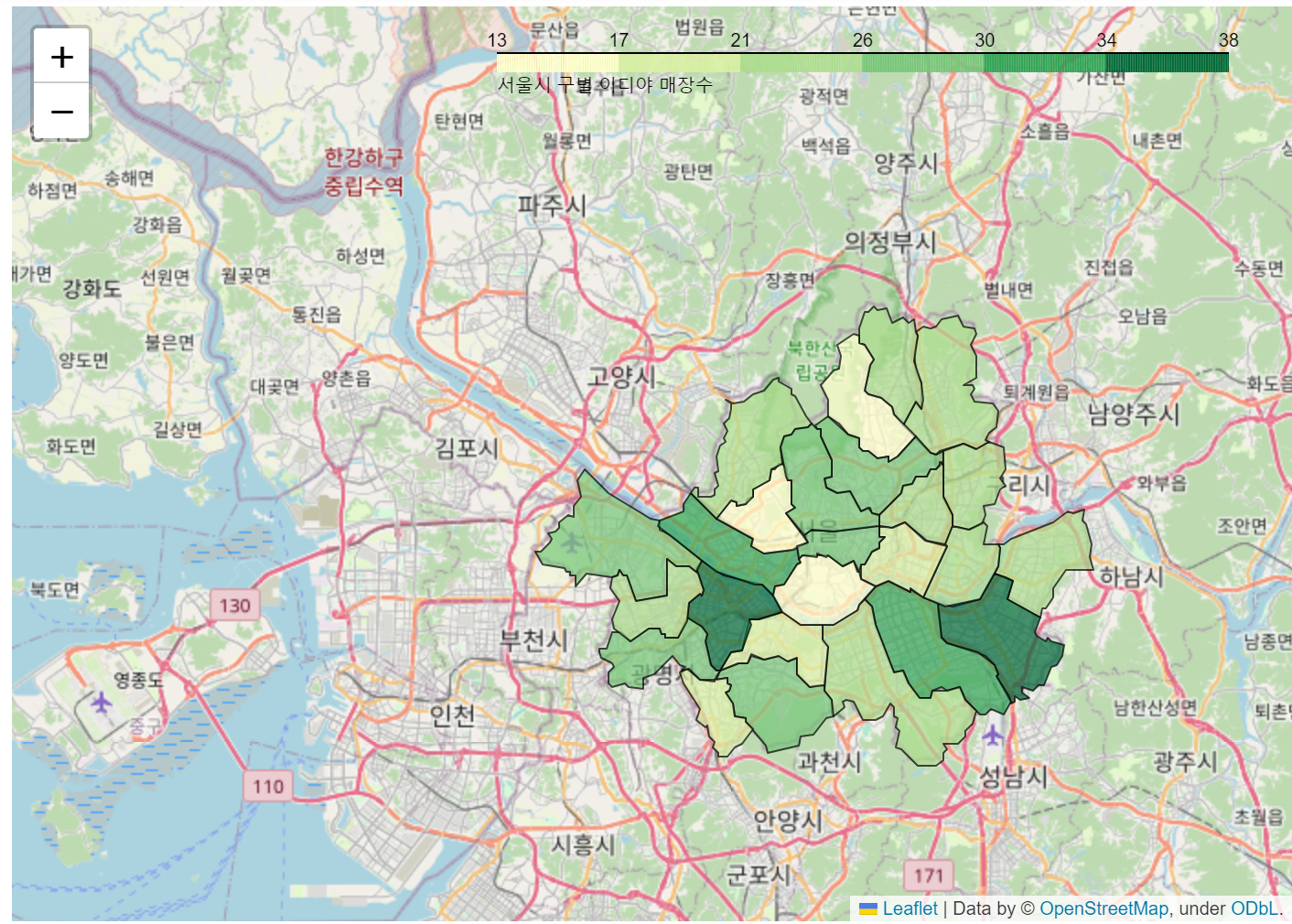
☞ 서울시 구별 투썸플레이스 매장수
f = folium.Figure(width=700, height=500)
m = folium.Map(location=[37.566535, 126.9779692], zoom_start=11).add_to(f)
folium.Choropleth(geo_data = geo_json
, data=twosome_count
, columns=['시군구명', 'count']
, key_on='properties.name'
, fill_color = 'BuPu'
, fill_opacity = 0.7
, line_opacity = 0.7
, legend_name = '서울시 구별 투썸플레이스 매장수').add_to(m)
m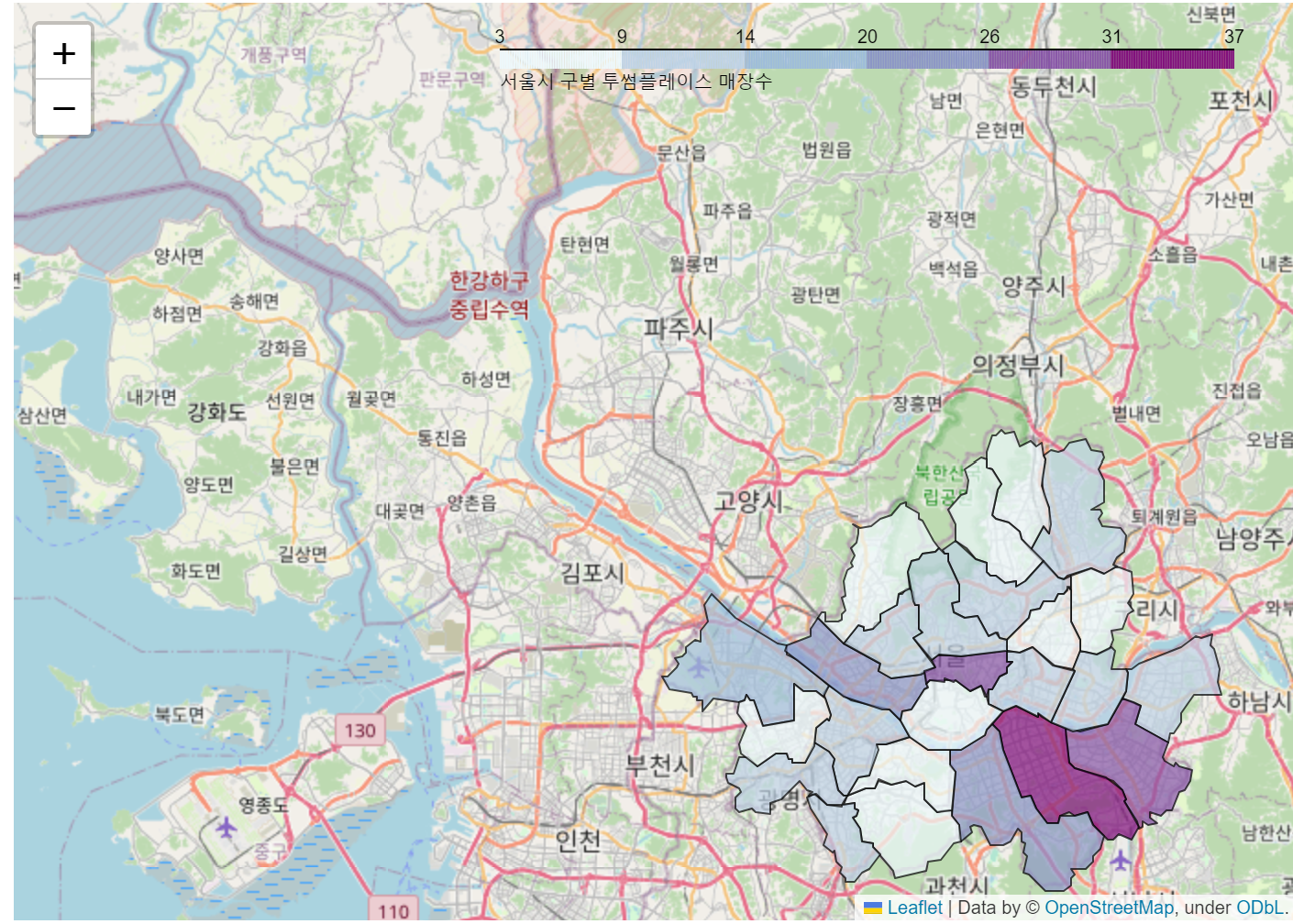
☞ 이디야와 투썸플레이스의 점포차이
ediya_twosome = ediya_count.merge(twosome_count, on='시군구명', suffixes=('_이디야','_투썸'))
ediya_twosome['이디야_ratio'] = ediya_twosome['count_이디야'] / ediya_twosome['count_이디야'].sum()
ediya_twosome['투썸_ratio'] = ediya_twosome['count_투썸'] / ediya_twosome['count_투썸'].sum()
ediya_twosome['투썸 상대적 비율'] = ediya_twosome['투썸_ratio'] / ediya_twosome['이디야_ratio']
ediya_twosome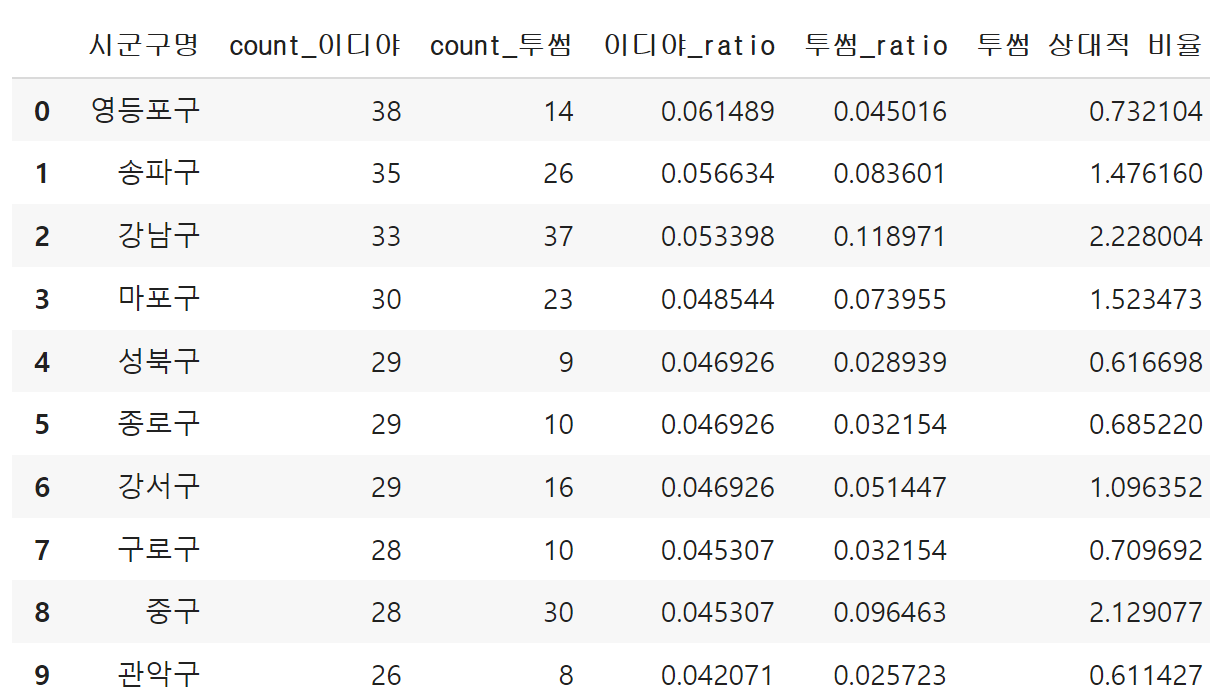
f = folium.Figure(width=700, height=500)
m = folium.Map(location=[37.566535, 126.9779692], zoom_start=11).add_to(f)
folium.Choropleth(geo_data = geo_json
, data=ediya_twosome
, columns=['시군구명', '투썸 상대적 비율']
, key_on='properties.name'
, fill_color = 'RdPu'
, fill_opacity = 0.7
, line_opacity = 0.7
, legend_name = '서울시 구별 투썸 상대적 비율').add_to(m)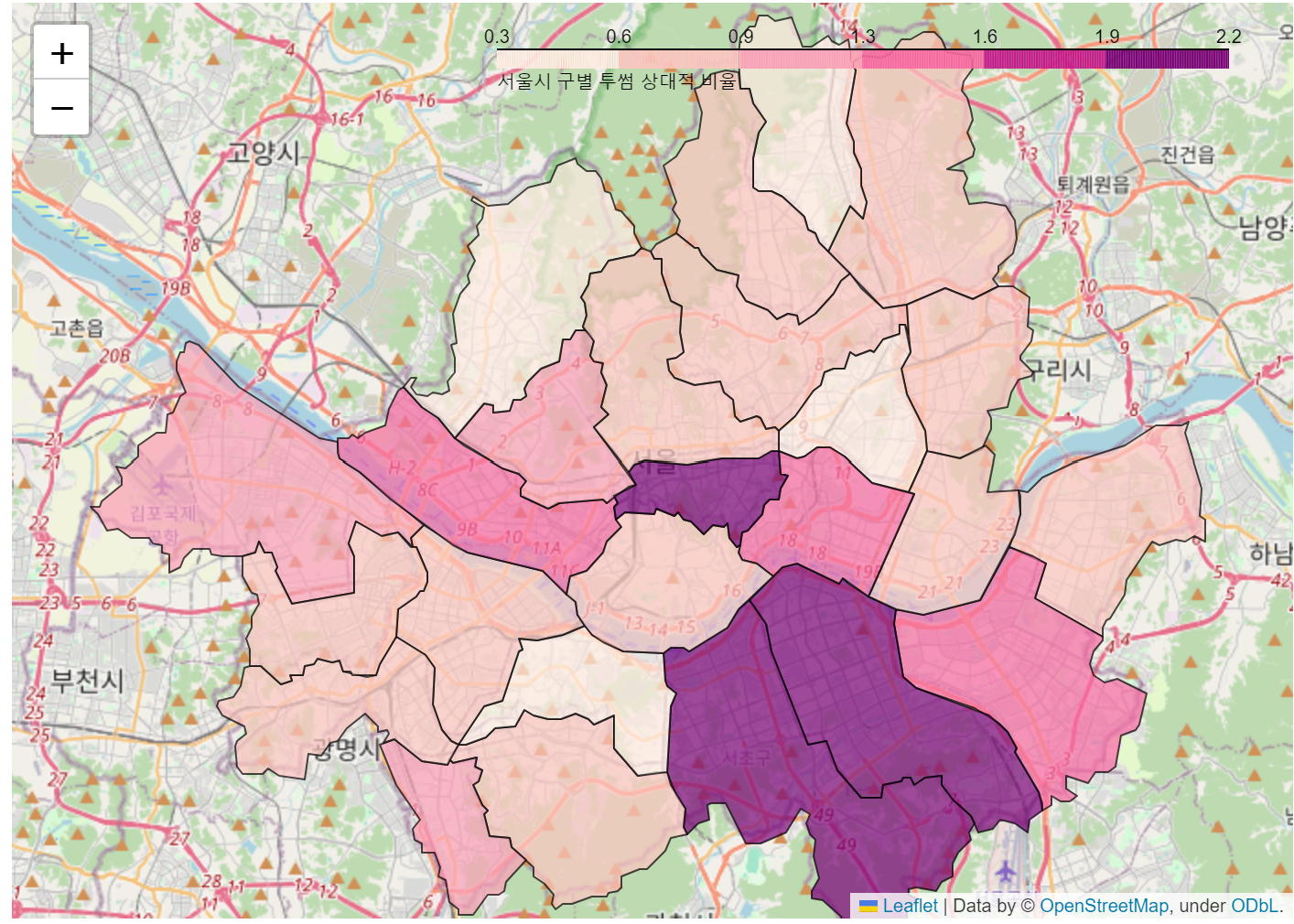
☞ 이디야와 투썸플레이스 지도 표시
ediya_df = ediya[['상호명','경도','위도']].copy()
ediya_df['kind'] = '이디야'
twosome_df = twosome[['상호명','경도','위도']].copy()
twosome_df['kind'] = '투썸'
dff = pd.concat([ediya_df, twosome_df])
dff.head()
from _plotly_utils.basevalidators import TitleValidator
f = folium.Figure(width=700, height=500)
m = folium.Map(location=[37.566535, 126.9779692], zoom_start=11).add_to(f)
for idx in dff.index:
lat = dff.loc[idx, '위도']
long = dff.loc[idx, '경도']
title = dff.loc[idx, '상호명']
if dff.loc[idx, 'kind'] == "이디야":
color = '#1d326c'
else:
color = '#D70035'
folium.CircleMarker([lat, long]
, radius=3
, color = color
, tooltip = title).add_to(m)
m
데이터분석 프로젝트 실습
1. 공개 데이터 플랫폼
◆ 공개 데이터 플랫폼
■ 국내
■ 해외
① kaggle
https://www.kaggle.com/datasets
Find Open Datasets and Machine Learning Projects | Kaggle
Download Open Datasets on 1000s of Projects + Share Projects on One Platform. Explore Popular Topics Like Government, Sports, Medicine, Fintech, Food, More. Flexible Data Ingestion.
www.kaggle.com
② awesomedata
https://github.com/awesomedata/awesome-public-datasets
GitHub - awesomedata/awesome-public-datasets: A topic-centric list of HQ open datasets.
A topic-centric list of HQ open datasets. Contribute to awesomedata/awesome-public-datasets development by creating an account on GitHub.
github.com
2. 웹 크롤링
◆ Pandas 활용
■ 기업실적분석표 가져오기 실습
☞ 가져올 데이터가 있는 url 넣기
url = 'https://finance.naver.com/item/main.nhn?code=035720'
table_df_list = pd.read_html(url, encoding='euc-kr')
table_df = table_df_list[3]
☞ finance-datareader 라이브러리를 사용하여 종목코드 불러오기
!pip install finance-datareader
☞ KOSPI에 해당하는 주식 종목을 가져오기
import FinanceDataReader
kospi = FinanceDataReader.StockListing("KOSPI")
kospi
☞ 리스트에 kospi에 해당하는 코드 10개까지 4번째 정보로 넣기
# 리스트 안에 4번째 정보를 넣기
kospi_info_list = []
for code in kospi['Code'][:10]:
url = f'https://finance.naver.com/item/main.nhn?code={code}'
table_df_list = pd.read_html(url, encoding='euc-kr')
table_df = table_df_list[3]
kospi_info_dic = {} # 아래 정보들을 담기위해 빈 딕셔너리 만들기
kospi_info_dic['code'] = code #for문으로 담고 있는 code 넣기
kospi_info_dic['table'] = table_df #크롤링해온 정보
kospi_info_list.append(kospi_info_dic)
☞ 리스트 안에 1번째 정보 불러오기
print(kospi_info_list[0]['code'])
display(kospi_info_list[0]['table'])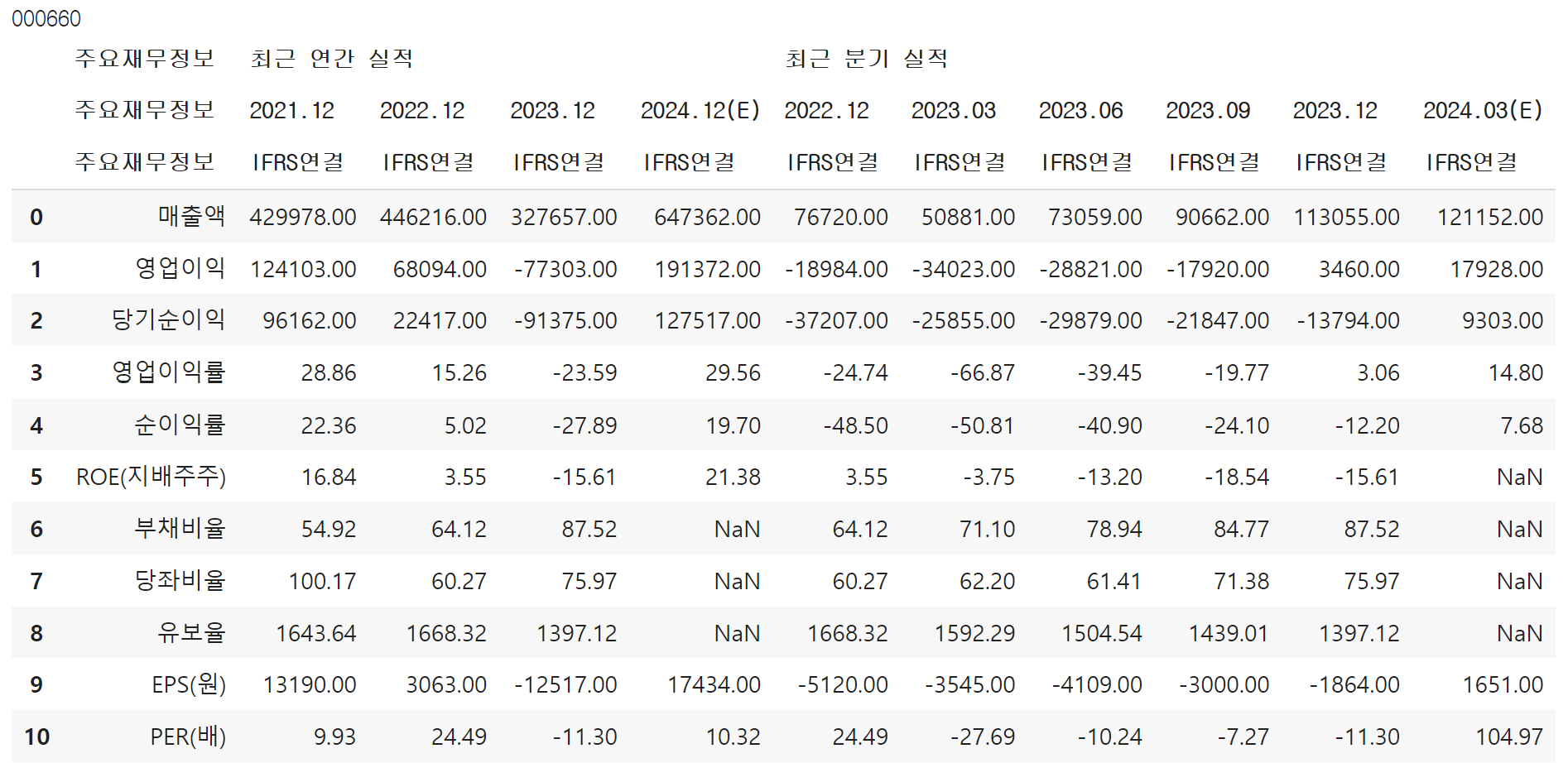
◆ BeautifulSoup 활용
■ 크롤링의 과정
- 파이썬으로 웹서버에 정보 요청하고 HTML 데이터 가져오기
- 데이터 파싱
- 원하는 정보 저장
# 라이브러리 사용
import requests #파이썬으로 웹서버에 정보를 요청
from bs4 import BeautifulSoup as bs # 데이터를 파싱하는데 사용
☞ 네이버에 제주도 정보 크롤링해 보기
① 검색하여 나온 url ctrl+c(복사)해서 url에 수정해 주기
keyword = '제주도'
# url 복사해보면 https://search.naver.com/search.naver?ssc=tab.blog.all&sm=tab_jum&query=%EC%A0%9C%EC%A3%BC%EB%8F%84
# %EC%A0%9C%EC%A3%BC%EB%8F%84 이부분이 제주도인것
url = f'https://search.naver.com/search.naver?ssc=tab.blog.all&sm=tab_jum&query={keyword}'
res = requests.get(url) #url을 함수에 넣어 가져오기
soup = bs(res.text, 'html.parser') #res의 text을 파싱하기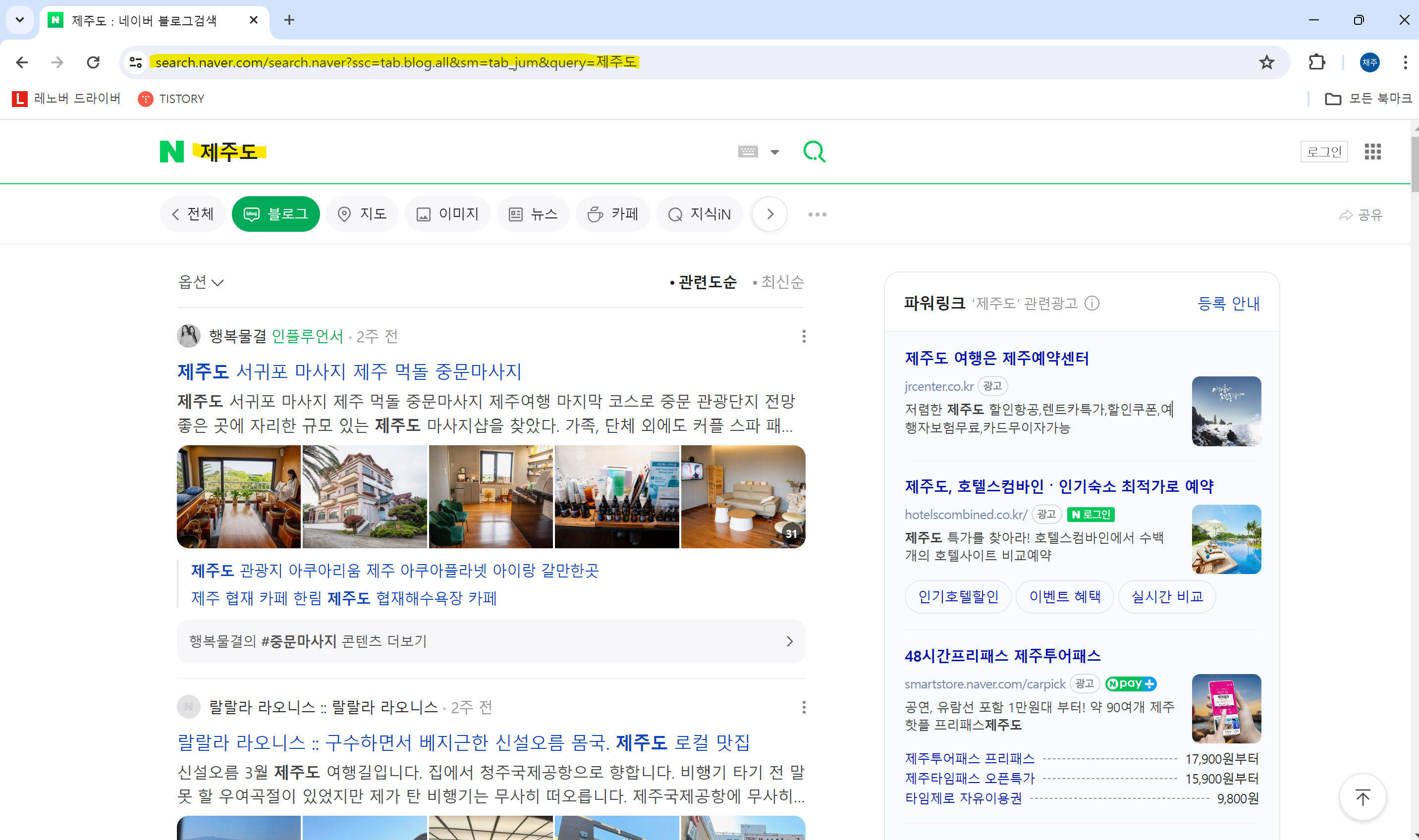
② 크롤링 확인
soup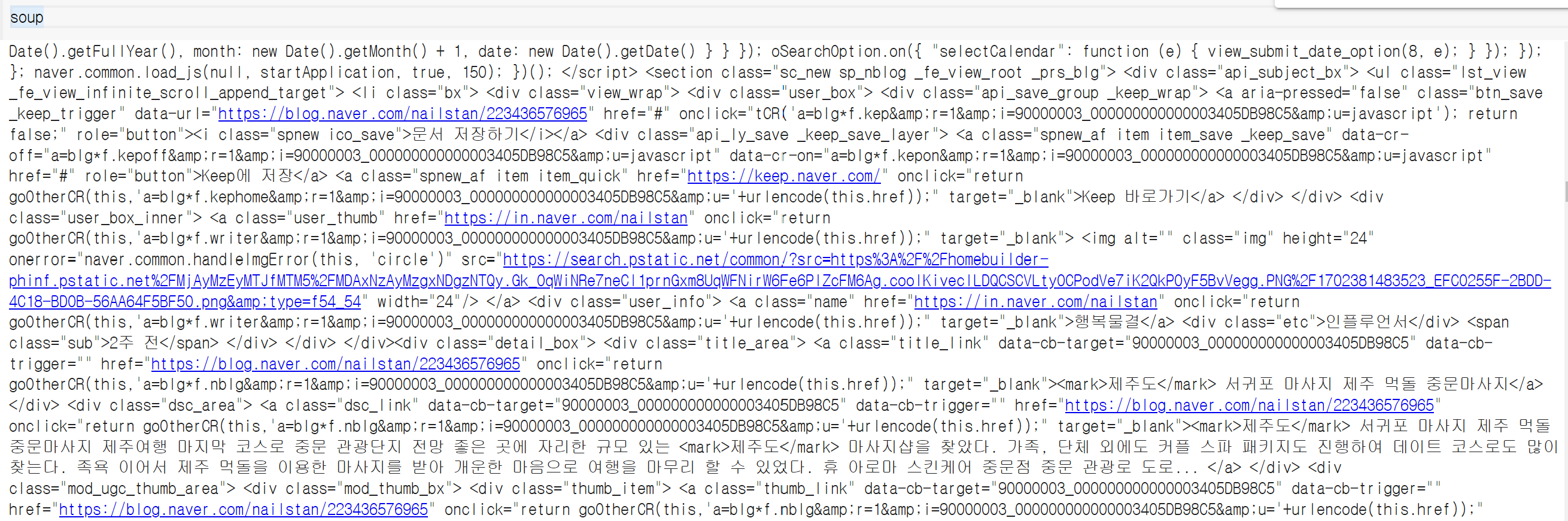
③ 첫 번째 블로그 데이터 가져오기
find_all 함수를 사용하여 title_link 이름의 데이터 전부 가져오기
soup.find_all('a', class_='title_link')[0]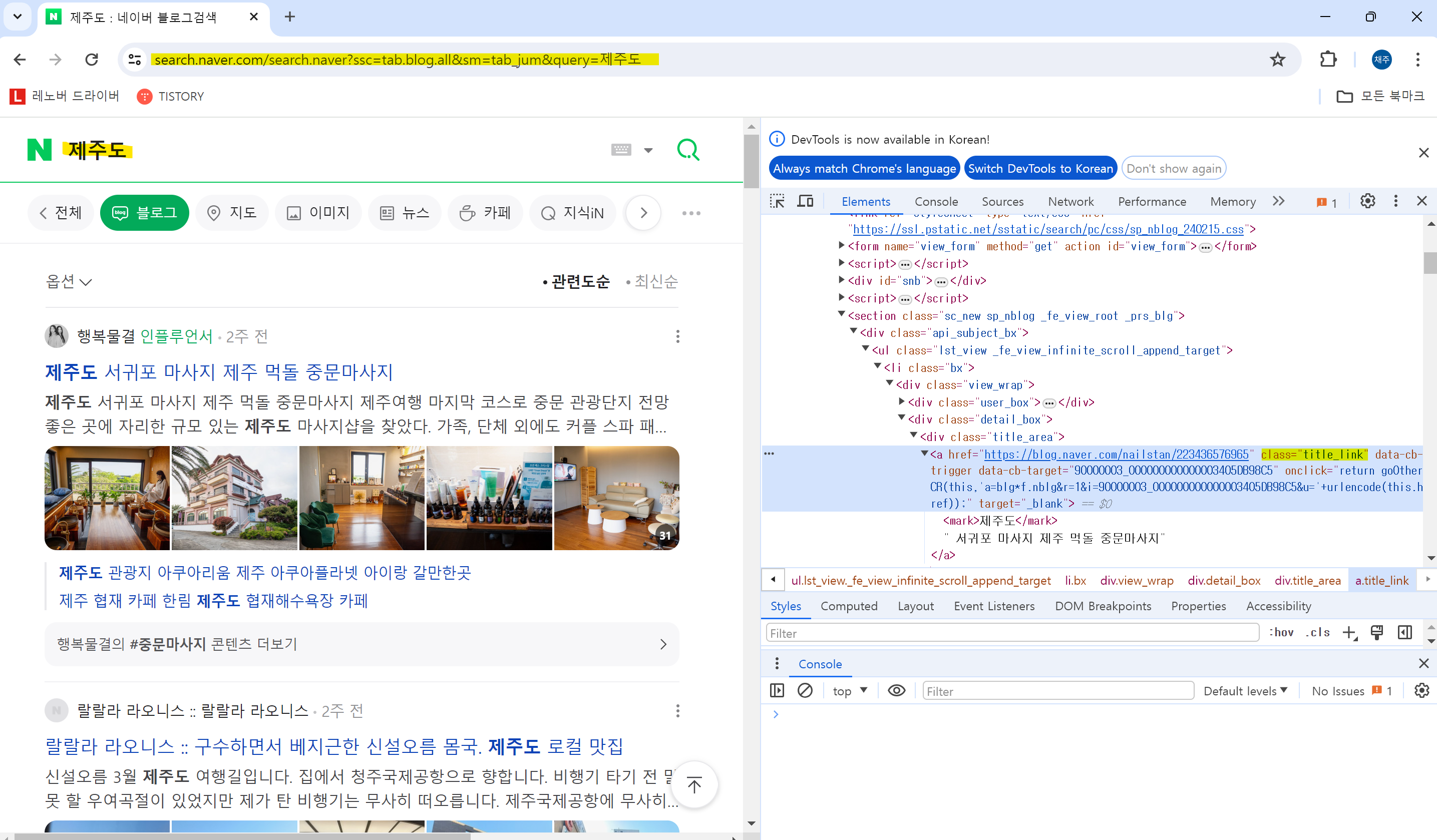

④ 제목만 가져오기
[i.text for i in soup.find_all('a', class_='title_link')]
⑤ 링크만 가져오기
[i['href']for i in soup.find_all('a', class_='title_link')]
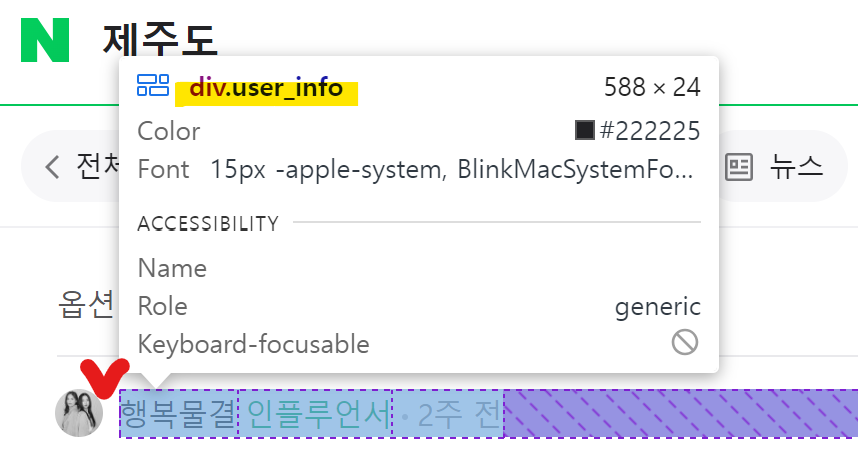
⑥ 데이터프레임 만들기
title = [i.text for i in soup.find_all('a', class_='title_link')]
date = [i.find('span').text for i in soup.find_all('div', class_='user_info')]
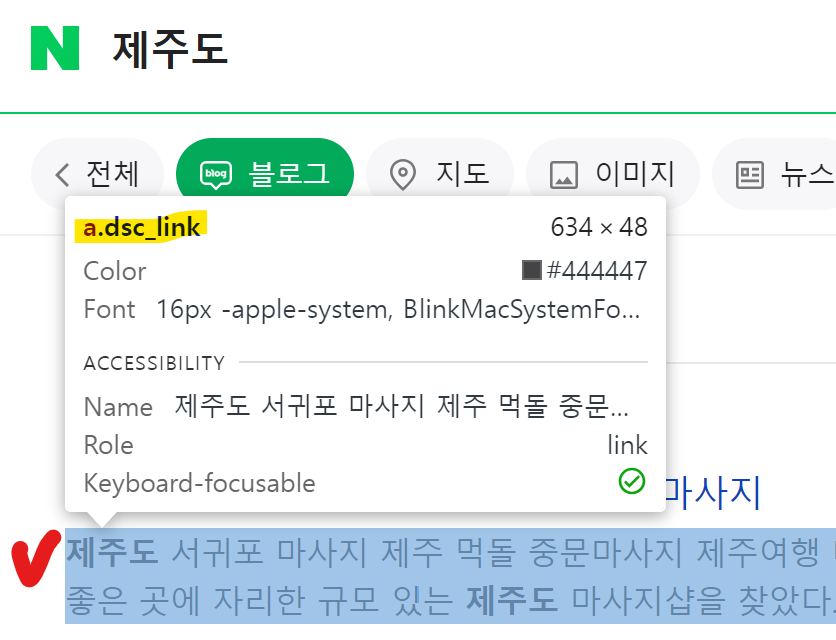
content = [i.text for i in soup.find_all('a', class_='dsc_link')]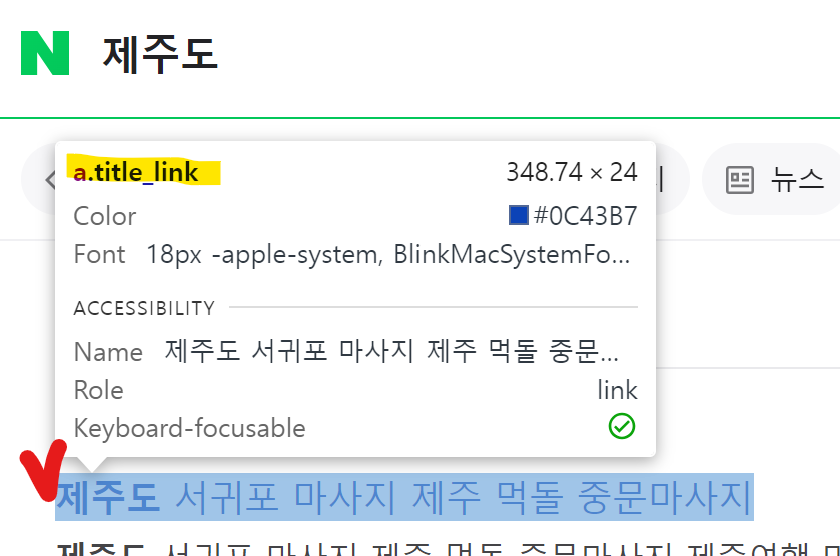
df = pd.DataFrame({'title':title, 'date':date, 'content':content})
df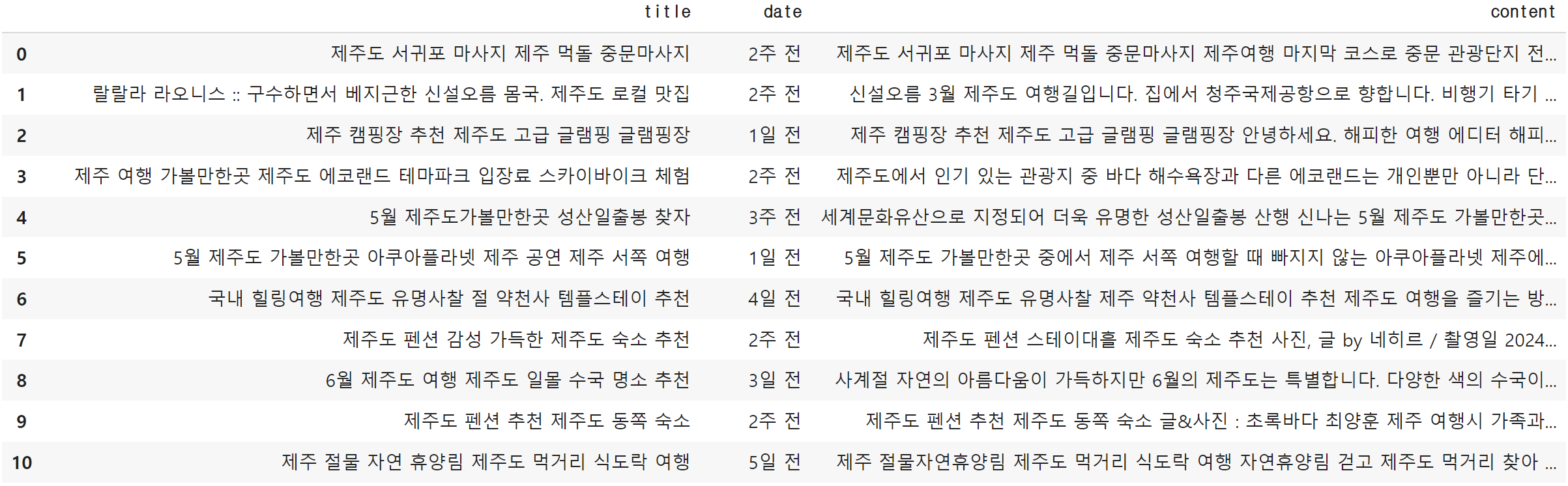
2. 영화데이터를 활용한 영화 흥행 요인 분석
◆ 영화 데이터 - 영화 흥행 요인 분석
① 데이터 살펴보기
② 어떤 데이터를 사용할 것인지 질문 만들기
③ 데이터 전처리
④ 데이터 분석
■ 데이터 살펴보기
# 데이터 사용을 위한 라이브러리 사용
import pandas as pd☞ 예시 데이터 경로 넣기
# 경로를 pd.read_csv 함수에 넣고 함수안에 데이터를 변수에 담기
movies = pd.read_csv('/content/drive/MyDrive/Python/Part3) 파이썬을 데이터 분석 프로젝트/Data/실습2_ 영화 데이터를 활용한 영화 흥행 요인 분석/tmdb_5000_movies.csv')
movies.head()
credits = pd.read_csv('/content/drive/MyDrive/Python/Part3) 파이썬을 데이터 분석 프로젝트/Data/실습2_ 영화 데이터를 활용한 영화 흥행 요인 분석/tmdb_5000_credits.csv')
credits.head()→ 두 가지 csv 경로 불러오기
■ 질문 만들기
- 연도별 흥행 수익은?
- 가장 흥행한 영화 TOP 10?
- 흥행에 가장 성공한 감독과 배우는?
- 장르와 흥행 수익
- 흥행 수익이 좋은 장르는?
- 시간의 흐름에 따라 유행하는 장르가 바뀌는지?
- 월별로 흥행하는 장르가 있는가?
- 수익과 예산, 투표수, 평점과의 상관관계는?
- ROI(예산 대비 수익)가 높으면서 흥행에 성공한 영화의 특징은?
☞ movies 데이터
- budget : 영화 예산(단위:달러)
- genres : 모든 장르
- homepage : 공식 홈페이지
- id : 각 영화당 unique id
- original_language : 원 언어
- original_title : 원 제목
- overview : 간략한 설명
- popularity : TMDB에서 제공하는 인기도
- production_companies : 모든 제작사
- production_countries : 모든 제각국가
- release_date : 개봉일
- revenue : 흥행 수익(단위:달러)
- runtime : 상영 시간
- spoken_language : 사용된 모든 언어
- status : 개봉 여부
- title : 영문 제목
- vote_avearage : TMDB에서 받은 평점 평균
- vote_count : TMDB에서 받은 투표수
☞ credits 데이터
- movie_id : 각 영화당 unique id
- title : 영문 제목
- cast : 모든 출연진
- crew : 모든 제작
■ 데이터 전처리
☞ 필요한 컬럼만 만들기
movies_df = movies[['id','budget','genres','title','release_date','revenue','vote_average','vote_count']]
credits_df = credits[['movie_id','crew','cast']]
☞ 데이터 결합(movies_df+credits_df)
# id와 movie_id 같기 때문에 id만 남기고 삭제
data = pd.merge(movies_df, credits_df, left_on = 'id', right_on = 'movie_id').drop('movie_id', axis=1)
data.head()
☞ roi 컬럼 만들기
data['roi'] = data['revenue'] / data['budget']
data.head()
☞ 감독 컬럼 만들기
data['crew'][0]
→ 결과를 확인하면 문자열이지만 리스트 형태로 되어있고 딕셔너리가 여러 개 보여짐
☞ ast 라이브러리 : 문자열로 되었으면서 자료형으로 되어있는 것을 → 자료형으로 변환
import ast
print(ast.literal_eval(data['crew'][0]))
→ 리스트로 변환
☞ 요소 한 개만 뽑아보기
ast.literal_eval(data['crew'][0])[0]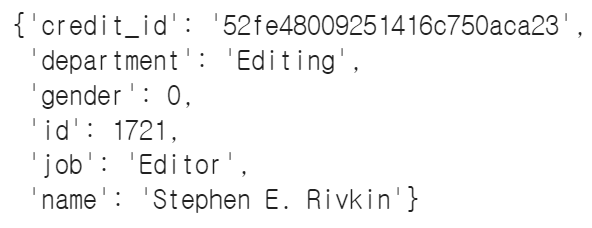
# 모든 문자열을 리스트로 변환
data['crew'] = data['crew'].apply(ast.literal_eval)
☞ key : job, value : director일 때 name이라는 key를 가진 value를 retrun
def get_director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
☞ drirector 정보가 나오는지 확인
get_director(data['crew'][0])
☞ director 컬럼 만들기
data['director'] = data['crew'].apply(get_director)
☞ cast 컬럼 만들기
data['cast'][0]data['cast_name'] = data['cast'].apply(lambda x: [i['name'] for i in ast.literal_eval(x)])
data.head()
☞ genres 컬럼 만들기
data['genres'][0]
→ 문자열이기 때문에 apply를 적용
data['genres'] = data['genres'].apply(ast.literal_eval)
→ 조건에 따라 genre을 main_genre에 뽑아 넣기
def get_genres(x):
if len(x) > 0:
return x[0]['name']
data['main_genre'] = data['genres'].apply(get_genres)
data.head()
☞ 데이터 타입 변경
data.info()
→pd.to_datetime 함수를 사용하여 날짜형식으로 변환, id는 astype(str) 문자형으로 변환
data['release_date'] = pd.to_datetime(data['release_date'], format='%Y-%m-%d')
data['id'] = data['id'].astype(str)
data.info()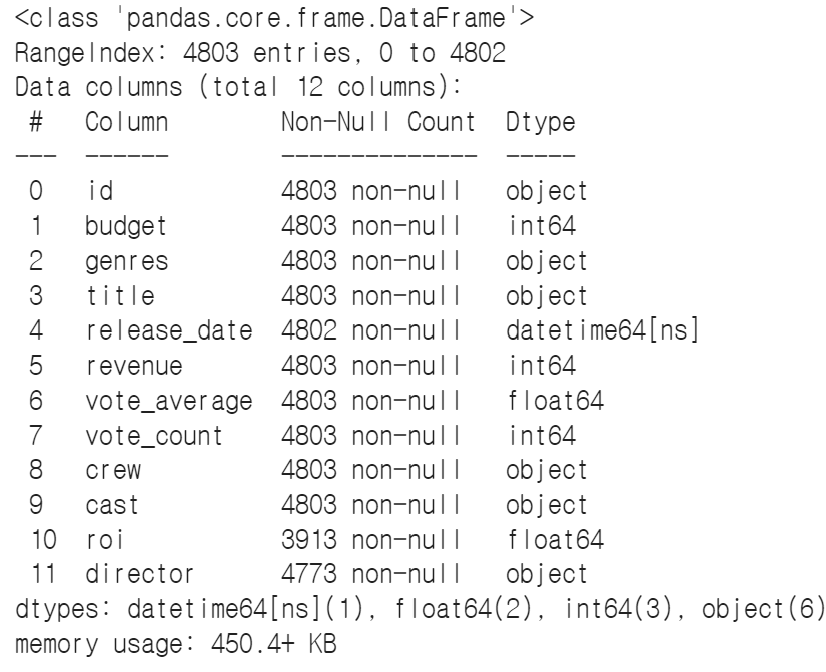
☞ 연도, 월 컬럼 만들기
- dt.year(연도), dt.month(월)
data['year'] = data['release_date'].dt.year
data['month'] = data['release_date'].dt.month
data.head()
☞ 결측치 제거
data.info()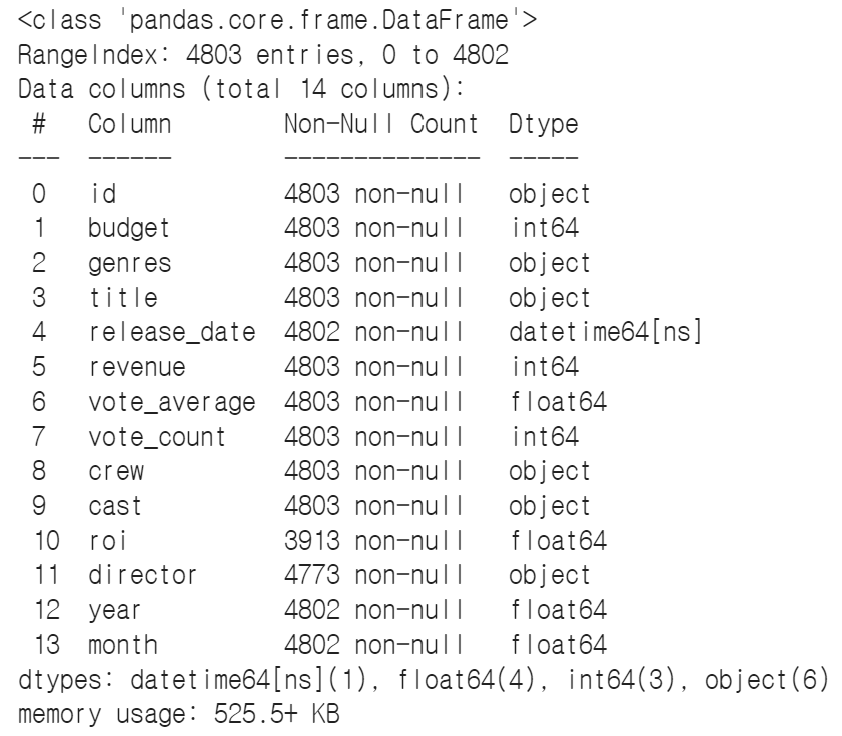
→ 결측치가 있는 것을 제거
data.dropna(inplace=True)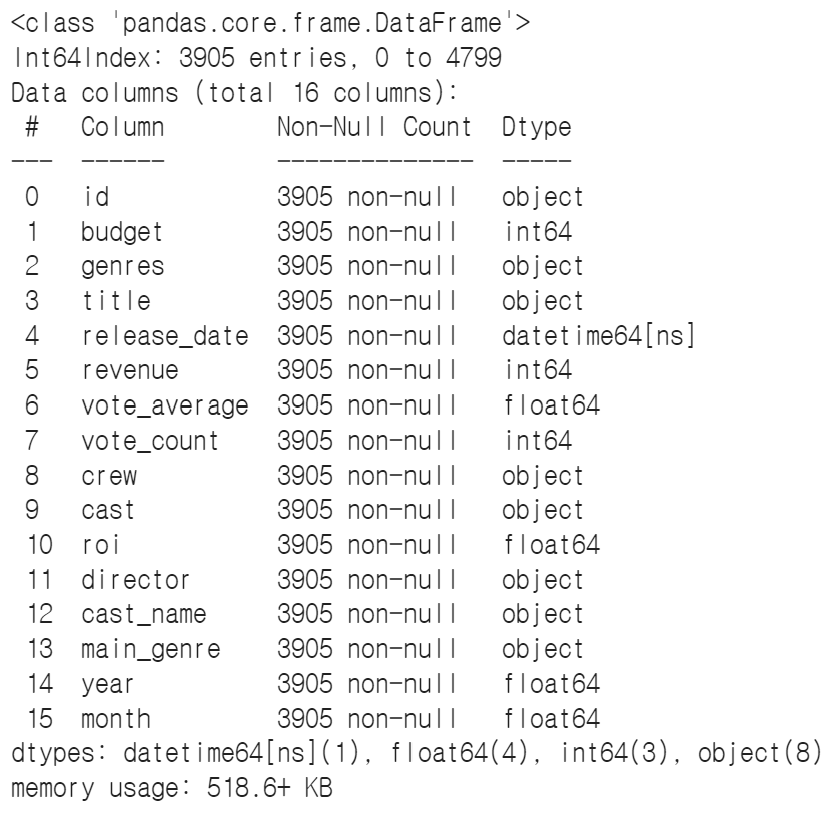
■ EDA, 시각화, 분석
# 시각화 라이브러리 중 plotly 사용
import plotly.express as px
☞ 연도별 흥행 수익
# revenue = 흥행 수익
revenue_by_year = data.groupby('year')[['revenue']].sum().reset_index()# line 함수 사용
fig = px.line(data_frame=revenue_by_year, x="year", y="revenue")
fig.show()
☞ 가장 흥행한 영화 TOP10은?
# title별로 groupby해서 흥행 수익의 합을 구함
# sort_values 함수를 사용하여 revenue을 내림차순하여 흥행 top10 구함
top = data.groupby('title')['revenue'].sum().reset_index().sort_values('revenue', ascending=False).head(10)
fig = px.bar(data_frame=top, x='title', y='revenue', title=f"흥행 수익 TOP 10 영화") # bar 그래프 사용
fig.show()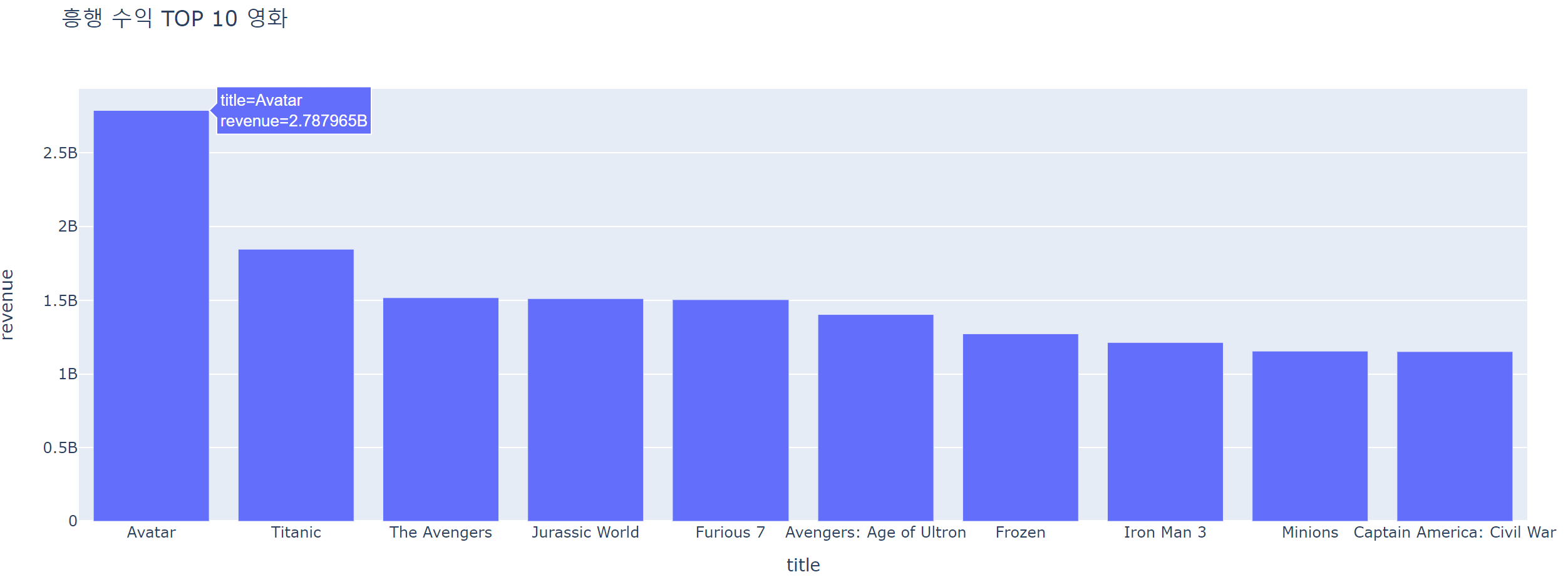
☞ 예산 TOP10, 투표수 TOP10 영화
# for문을 사용하여 예산과 투표수에 따른 top10 구하기
title_dic = {'budget':'예산', 'vote_count':'투표수'}
for y in ['budget','vote_count']:
top = data.groupby('title')[[y]].sum().reset_index().sort_values(y, ascending=False).head(10)
fig = px.bar(data_frame=top, x='title', y=y, title=f"{title_dic[y]} TOP 10 영화")
fig.show()
☞ 흥행 수익 TOP10 감독
top_director = data.groupby(['director'])['revenue'].sum().reset_index().sort_values('revenue', ascending=False).head(10)
fig = px.bar(data_frame=top_director, x='director', y='revenue', title=f"흥행 수익 TOP 10 감독")
fig.show()# revenue값에 있는 cast_name를 각각 따로 표기
revenue_cast = data[['revenue', 'cast_name']].explode('cast_name')top_cast = revenue_cast.groupby('cast_name')[['revenue']].sum().reset_index().sort_values('revenue', ascending=False).head(10)
fig = px.bar(data_frame=top_cast, x='cast_name', y='revenue', title=f"흥행 수익 TOP 10 배우")
fig.show()→ 그래프를 확인하면 유명 감독과 배우 일부가 많은 흥행 수익을 차지
☞ 장르와 흥행 수익
main_genre별 흥행 수익 분표를 확인해 보기
fig = px.box(data_frame = data, y = 'main_genre', x = 'revenue', hover_name = 'title')
fig.show()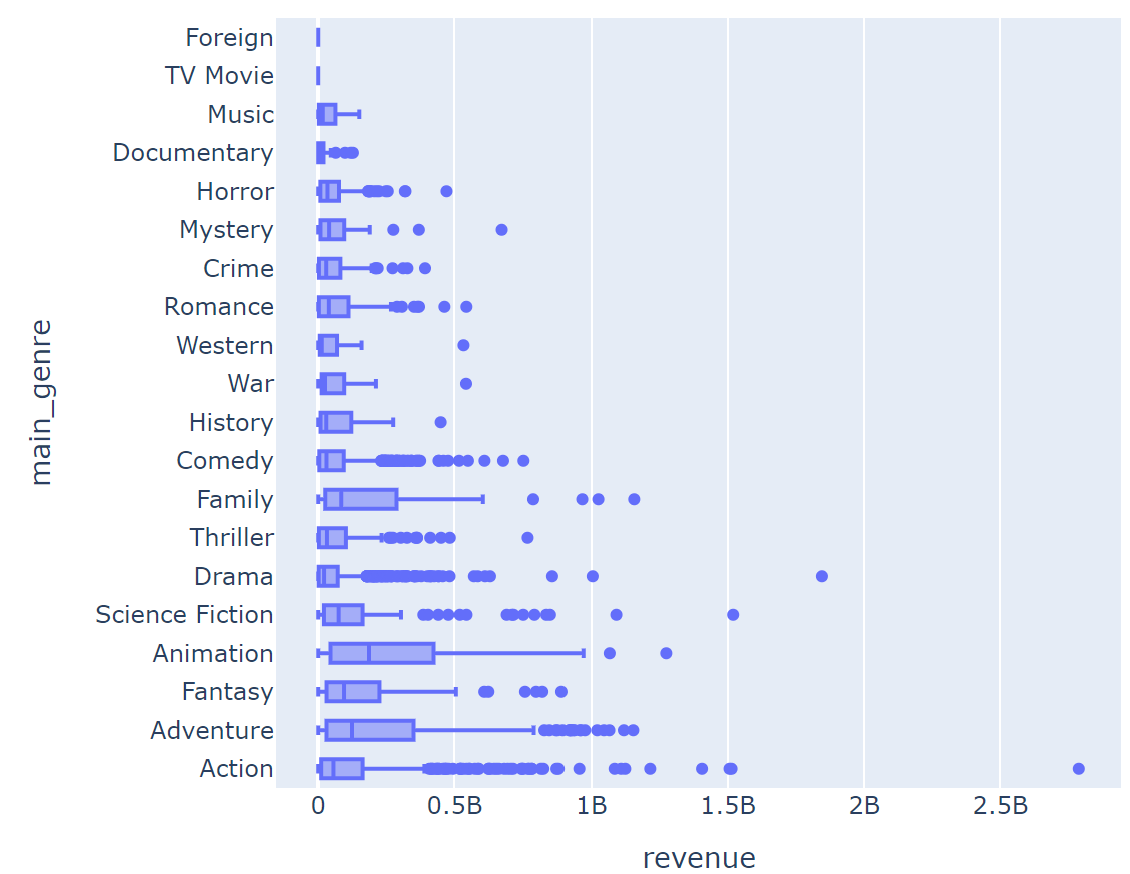
→ 그래프 확인해 보면 액션과 드라마 장르에 흥행 수익이 높음
→ 중앙값으로 확인해 보면 높은 편이 x
→ 장르별 흥행 수익 평균을 비교

☞ 장르별 흥행 수익 합계
genre_sum_revenue = data.groupby('main_genre')[['revenue']].sum().reset_index()
fig = px.bar(data_frame = genre_sum_revenue, x = 'main_genre', y = 'revenue', title = '장르별 흥행 수익 합계')
fig.show()
☞ 연도별 장르별 수익
#year와 main_genre을 기준으로 구하기
revenue_by_year_genre = data.query('year >= 1990').groupby(['year','main_genre'])[['revenue']].sum().reset_index()fig = px.bar(data_frame=revenue_by_year_genre, x="year", y="revenue", color='main_genre', color_discrete_sequence=px.colors.qualitative.Light24_r)
fig.show()revenue_by_year_genre_pct = pd.pivot_table(data=data.query('year >= 1990'), index='year', columns='main_genre', values='revenue', aggfunc=sum, fill_value=0, margins=True)
# revenue_by_year_genre_pct.iloc[:,-1] : 연도별 합
revenue_by_year_genre_pct = 100 * revenue_by_year_genre_pct.div(revenue_by_year_genre_pct.iloc[:,-1], axis=0).drop('All').drop('All', axis=1)
revenue_by_year_genre_pct = pd.melt(revenue_by_year_genre_pct.reset_index(), id_vars='year', value_name='pct')
revenue_by_year_genre_pct
3. 유통 데이터를 활용한 리텐션과 RFM 분석
◆ 유통 데이터 - 리텐션과 RFM 분석
■ 데이터 살펴보기
# pandas : 데이터 불러오고 전처리하기 위해 사용
# plotly : 시각화하기 위한
import pandas as pd
import plotly.express as pxdata = pd.read_csv('path(경로).csv(파일)')
data.head()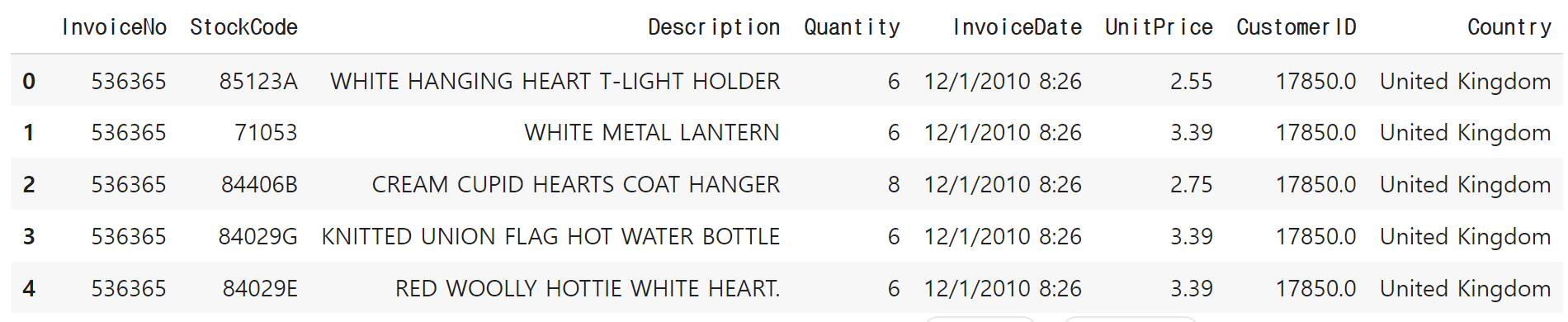
■ 질문 만들기
- 시간의 흐름에 따라 매출, 주문고객수, 주문단가의 추이는 어떻게 달라지는가?
- 리텐션 분석 : 시간의 흐름에 따라 고객들은 얼마나 남고 얼마나 이탈했는가?
- RFM 분석 : 고객의 행동에 따라 고객을 유형화하자
☞ 리텐션 분석
- 유저가 제품을 사용한 이후 일정 기간이 지난 시점에 제품을 계속 사용하고 있는지 유저의 잔존과 이탈을 트래킹 하는 분석
- Day0에 앱에 방문한 유저 중 Day1에 다시 재방문한 유저의 비율이 리텐션
- 일반적으로 리텐션이 높으면 유저가 서비스를 주기적으로 사용한다는 뜻으로 해석, 유저의 참여와 충성도 같은 지표를 높이기 위한 제품 방향성을 정하는데 중요한 지표로 활용
☞ RFM 분석
- Recency, Frequency, Monetary를 기반으로 고객을 유형화하는 방법
- Recency(최근성) : 고객이 얼마나 최근에 구매를 했는지
- Frequency(빈도) : 고객이 얼마나 자주 구매를 하는지
- Monetary(금액) : 고객이 구매한 총금액
→ 즉, 고객유형을 세분화하여 맞춤형 전략을 구성 가능하다
(총 구매금액은 낮지만 자주 방문 / 최근에 큰 금액을 구매했지만 자주 방문하지는 않았던 유저)
■ 데이터 전처리
# 데이터 확인
data.info()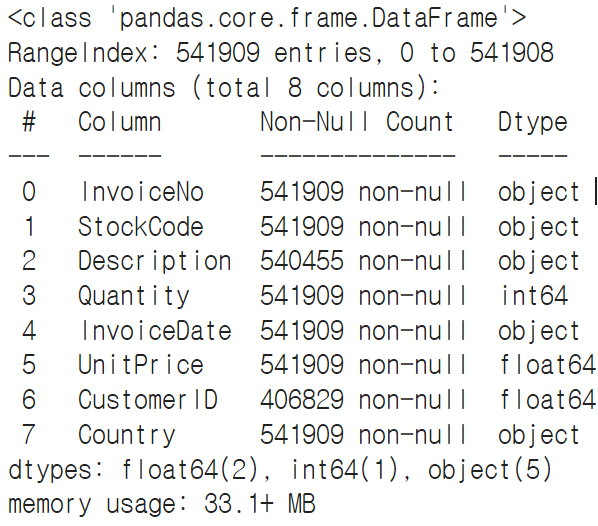
#고객 분석을 할 것이므로 CustomerID가 없는 행은 제거.\
#dropna를 사용하여 제거
data.dropna(subset=['CustomerID'], inplace=True)
data.info()
☞ 데이터 타입 변경
#InvoiceDate 문자열-> 시간형
data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate'], format='%m/%d/%Y %H:%M')
#CustomerID 숫가형-> 문자형
data['CustomerID'] = data['CustomerID'].astype(int).astype(str)
data.info()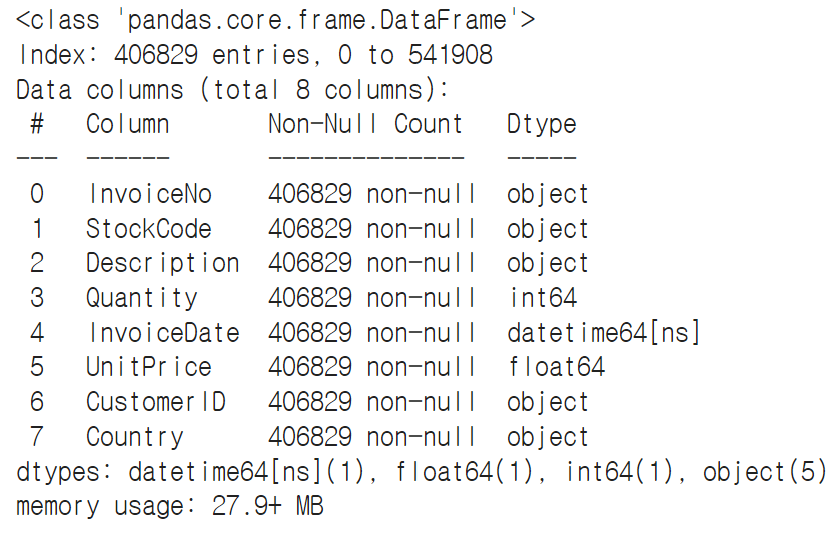
☞ 데이터 다시 확인
data.head()
☞ 날짜 컬럼 추가
#data['InvoiceDate'].dt.date 한다면 문자타입으로 나오기 때문에 타입 변경 같이 진행
data['date_ymd'] = data['InvoiceDate'].dt.date.astype('datetime64[ns]')
data['year'] = data['InvoiceDate'].dt.year
data.head()
☞ 매출 컬럼 추가
data['amount'] = data['Quantity'] * data['UnitPrice'] #매출 = 수량 * 개당 가격
data.head()
☞ 추가된 데이터까지 확인
data.info()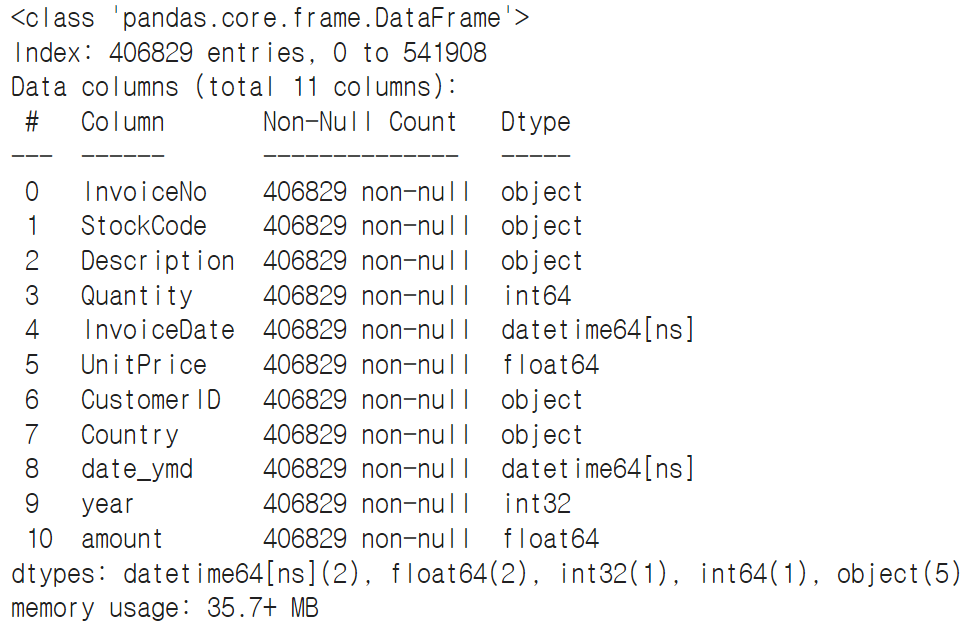
☞ 취소된 주문 건 삭제 → 취소는 Quantity -값이기 때문에 음수 제거
data = data.query('Quantity > 0')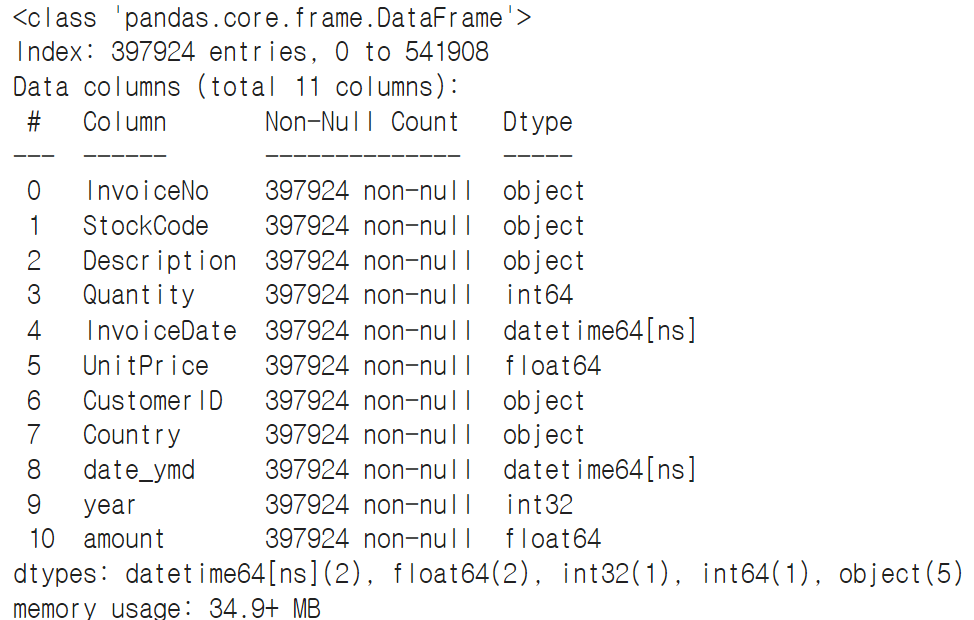
→ 값이 400000대에서 390000대로 줄어듦
■ EDA, 시각화, 분석
■ EDA
① 시간의 흐름에 따라 매출, 주문고객수, 주문단가의 추이는 어떻게 달라지는가?
- 매출
# 일자로 groupby 해주고 총매출을 합하여 계산
amount_by_date = data.groupby('date_ymd')[['amount']].sum().reset_index()
fig = px.line(data_frame=amount_by_date, x='date_ymd', y='amount')
fig.show()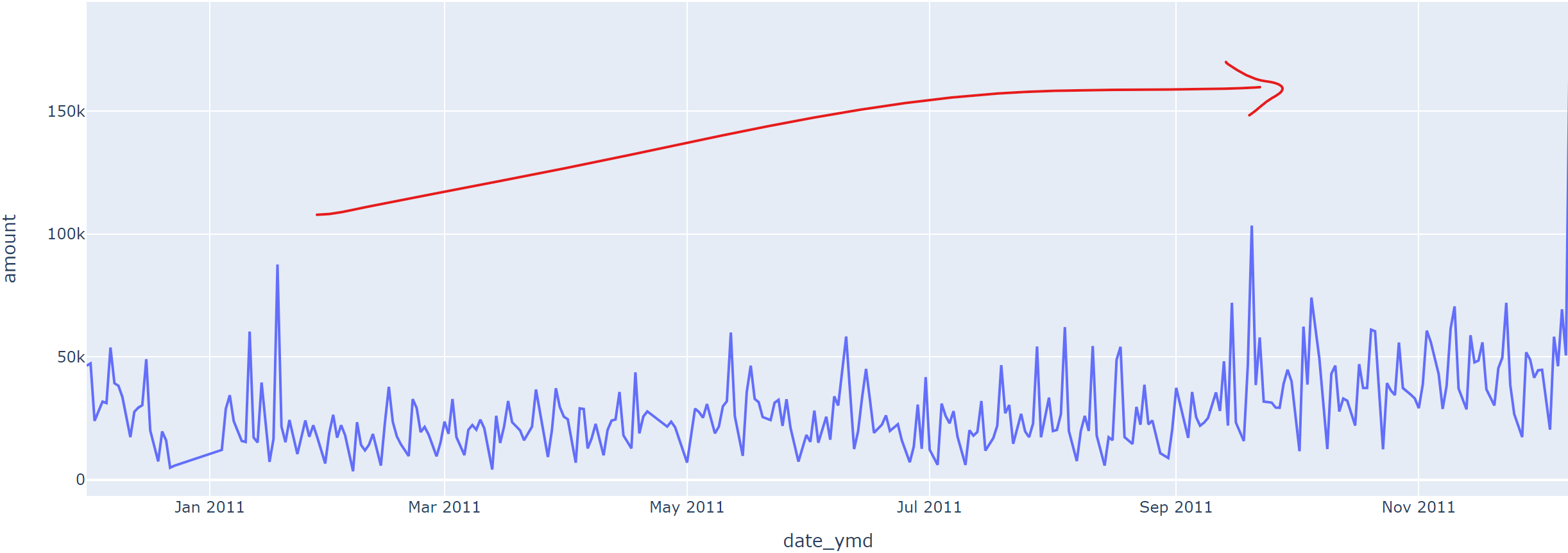
- 주문고객수
#일자별로 CustomerID의 nunique값을 나타내고 인덱스 해줌/CustomerID-> customer_count 변경
customer_count_by_date = data.groupby('date_ymd')[['CustomerID']].nunique().reset_index().rename({'CustomerID':'customer_count'}, axis=1)
fig = px.line(data_frame=customer_count_by_date, x='date_ymd', y='customer_count')
fig.show()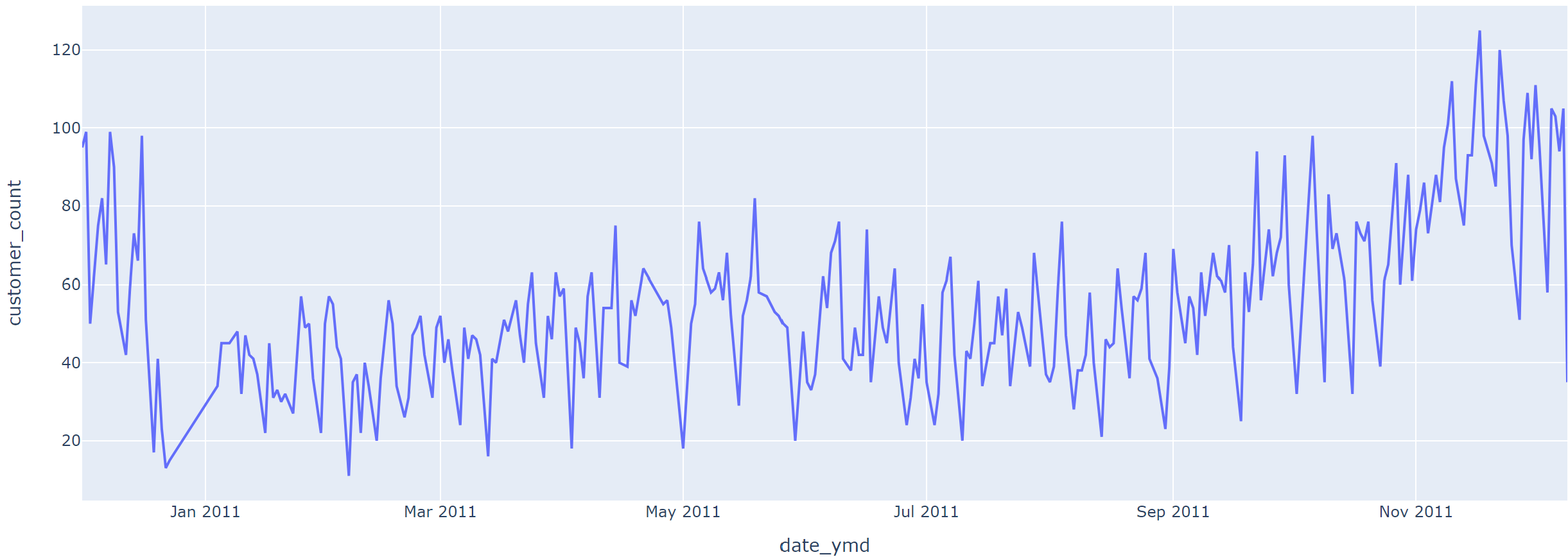
- 주문단가
amount_by_date.head()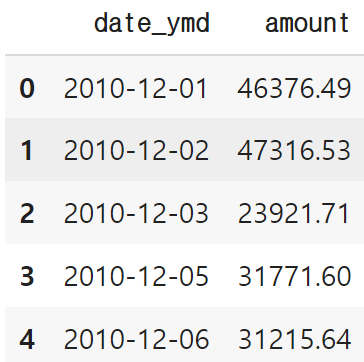
invoice_count_by_date = data.groupby('date_ymd')[['InvoiceNo']].nunique().reset_index().rename({'InvoiceNo':'invoice_count'}, axis=1)
invoice_count_by_date.head()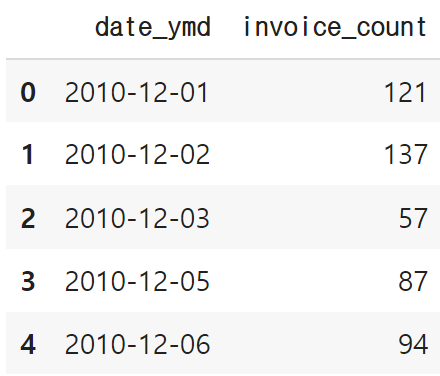
#merge함수를 사용하여 테이블 합치기
invoice_amount = pd.merge(amount_by_date, invoice_count_by_date, on='date_ymd')
invoice_amount['amount_per_invoice'] = invoice_amount['amount'] / invoice_amount['invoice_count']
invoice_amount.head()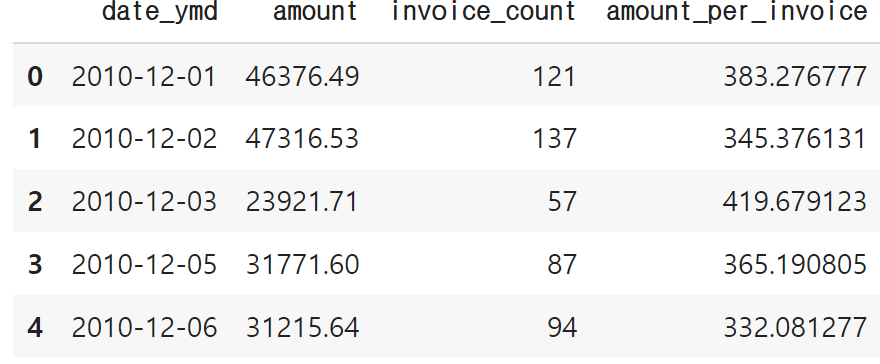
fig = px.line(data_frame=invoice_amount, x='date_ymd', y='amount_per_invoice')
fig.show()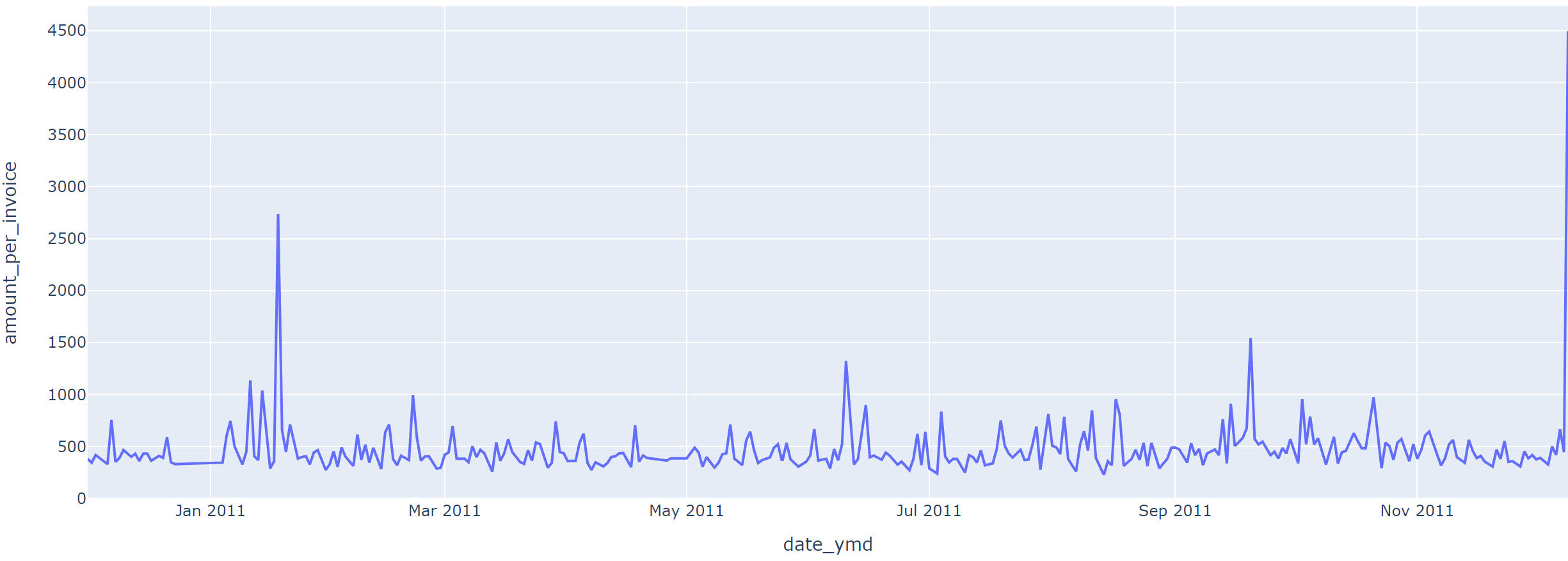
② 리텐션 분석 : 시간의 흐름에 따라 고객들은 얼마나 남고 얼마나 이탈했는가?
- 연월 단위로 고객번호, 영수증번호 전처리
retention_base = data[["CustomerID", "InvoiceNo", "date_ymd"]].drop_duplicates()
retention_base['date_ym'] = retention_base['date_ymd'].dt.to_period('M')
retention_base.head()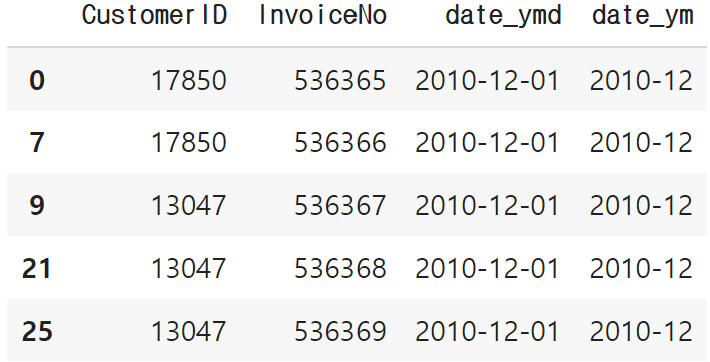
☞ 날짜 범위 수정
print(min(data['date_ymd'].unique()))
print(max(data['date_ymd'].unique()))
#12월 데이터를 포함하면 2011년 12월 데이터는 리텐션이 낮을 수 밖에 없으므로 12월 데이터 제외
retention_base = retention_base.query('date_ymd <= "2011-11-30"')
☞ 리텐션 계산
date_ym_list = sorted(list(retention_base['date_ym'].unique()))from tqdm.notebook import tqdmretention = pd.DataFrame()
for s in tqdm(date_ym_list):
for t in date_ym_list:
period_start = s
period_target = t
if period_start <= period_target:
period_start_users = set(retention_base.query('date_ym == @period_start')['CustomerID'])
period_target_users = set(retention_base.query('date_ym == @period_target')['CustomerID'])
#intersection(교집합)함수를 이용하여 합쳐진 값을 구하기
retained_users = period_start_users.intersection(period_target_users)
retention_rate = len(retained_users) / len(period_start_users)
temp = pd.DataFrame({'cohort':[period_start], 'date_ym':[period_target], 'retention_rate':[retention_rate]})
retention = pd.concat([retention, temp])retention['cohort_size(month)'] = retention.apply(lambda x: (x['date_ym'] - x['cohort']).n, axis=1)
retention.head()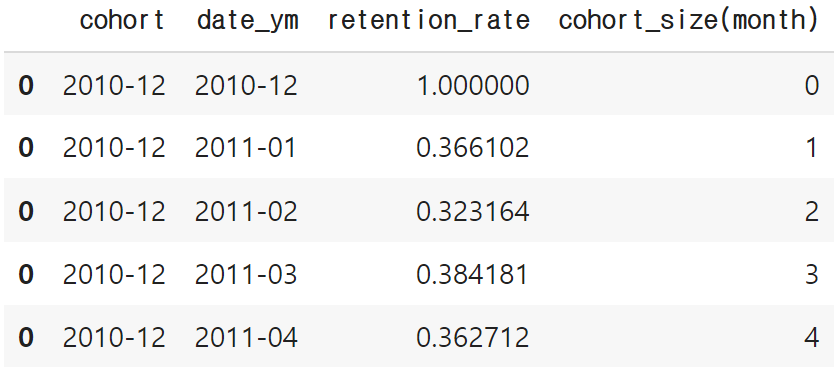
retention['cohort'] = retention['cohort'].astype(str)
retention['date_ym'] = retention['date_ym'].astype(str)retention_final = pd.pivot_table(data=retention, index='cohort', columns='cohort_size(month)', values='retention_rate')
retention_final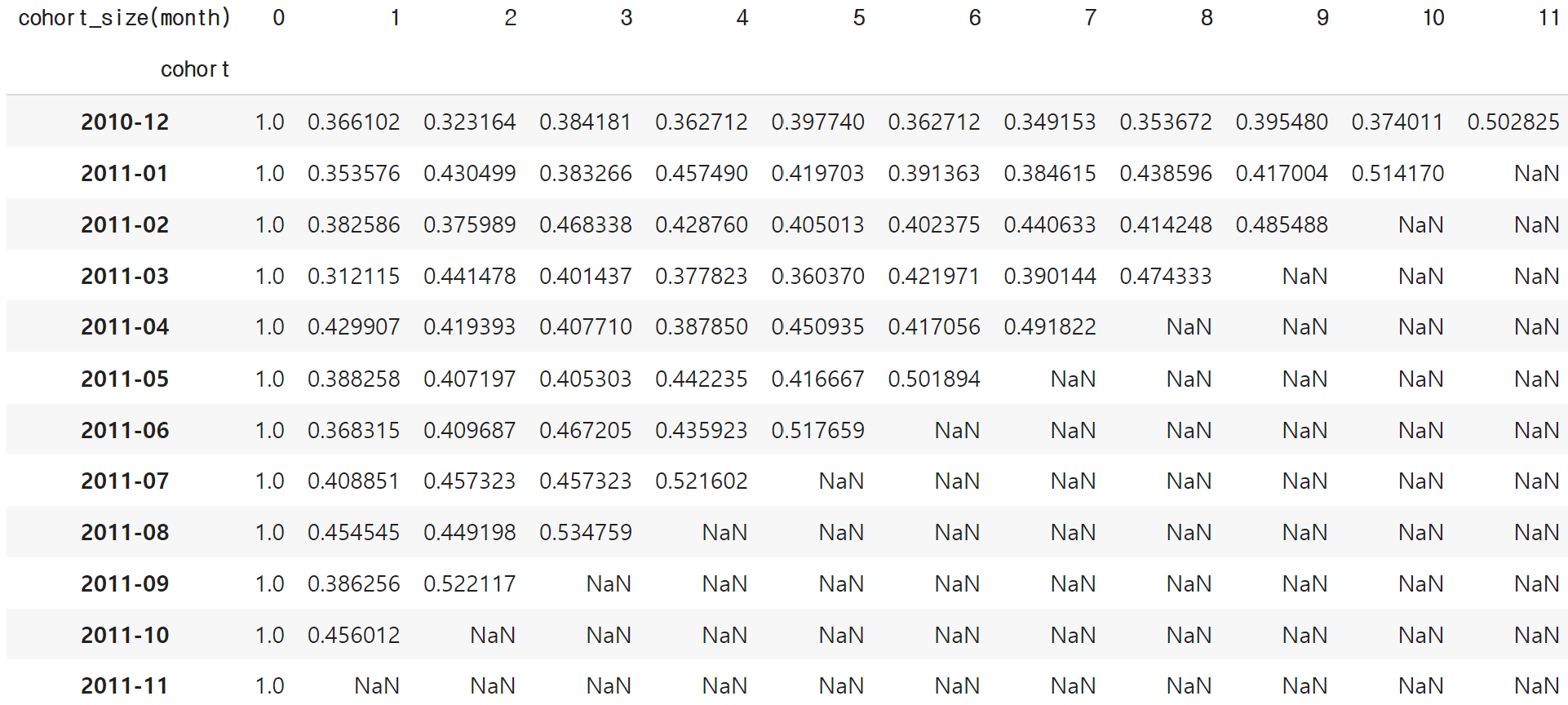
■ 시각화
fig = px.imshow(retention_final, text_auto='.2%', color_continuous_scale='Burg')
fig.show()
☞ 리텐션 커브
retention_curve = retention.groupby('cohort_size(month)')[['retention_rate']].mean().reset_index()
retention_curve
#cohort_size에 따른 retention_rate 평균을 나타냄
fig = px.line(data_frame = retention_curve, x='cohort_size(month)', y='retention_rate', title='리텐션 커브')
fig.update_yaxes(tickformat='.2%')
fig.show()
③ RFM 분석 : 고객의 행동에 따라 고객을 유형화하자
- 여기에서는 Recency(최근성)와 Monetary(금액) 두 요소를 가지고 RM 분석해 보기
data.head()
☞ RM계산
today_date = max(data['date_ymd'])
rfm = data.groupby('CustomerID').agg({'InvoiceDate': lambda x: (today_date - x.max()).days, #오늘로부터 며칠이 지났는지
'amount': lambda x: x.sum()}) #주문금액
rfm.columns = ['recency', 'monetary']
rfm.head()

☞ 각 팩터를 3등급으로 나눠서 등급을 매김
- pd.qcut(컬럼, 등급개수, 라벨)
pd.qcut(rfm["recency"], 5, labels=[5, 4, 3, 2, 1])
rfm['recency_score'] = pd.qcut(rfm["recency"], 3, labels=[3, 2, 1])
rfm['monetary_score'] = pd.qcut(rfm["monetary"], 3, labels=[1, 2, 3])
rfm['rm_score'] = rfm['recency_score'].astype(str) + rfm['monetary_score'].astype(str)
rfm.reset_index(inplace=True)
rfm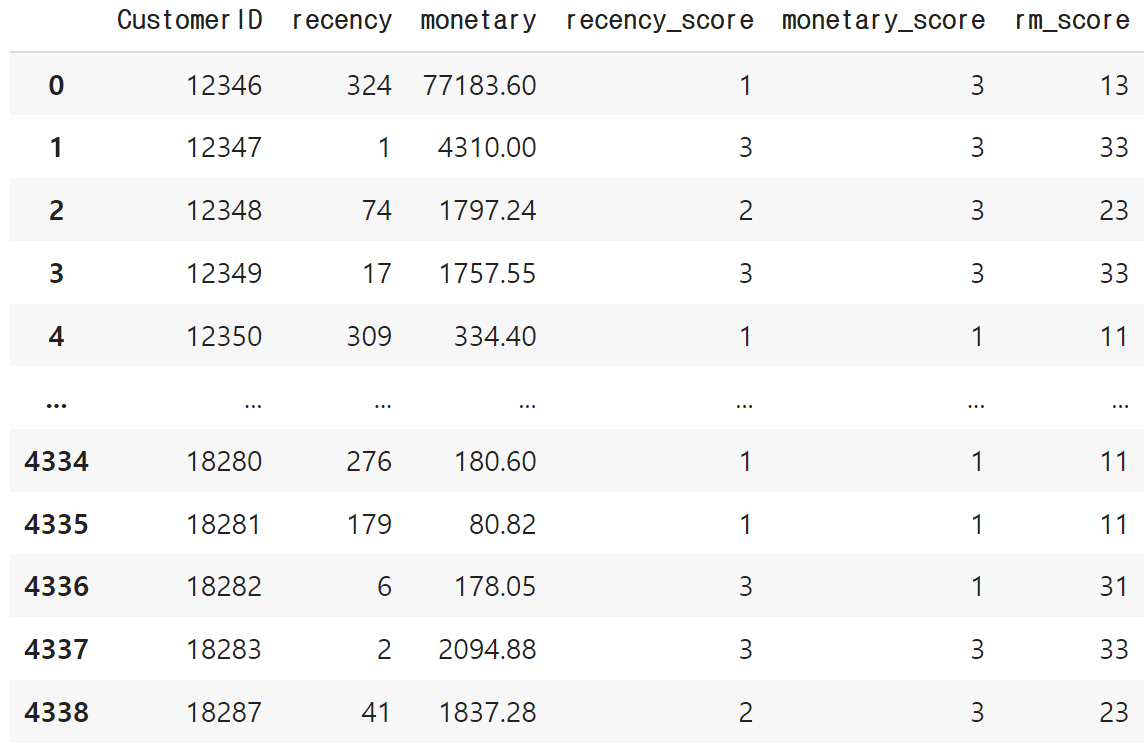
rm_score = rfm.groupby('rm_score')[['CustomerID']].nunique().reset_index().rename({'CustomerID':'customer_count'}, axis=1)
rm_score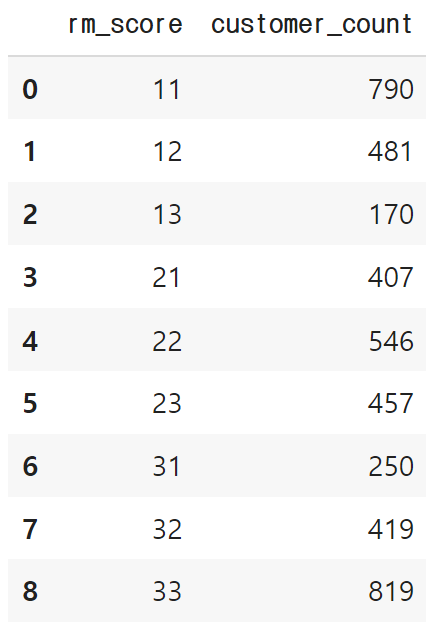
def categorize_customer(score):
if score == '33':
return '최우수' #최신성, 구매 모두 상당히 높음
elif score in ['32','23','22']:
return '우수' #최신성, 구매 모두 높음
elif score =='11':
return '휴면' #최신성, 구매 모두 낮음
elif score in ['12','13']:
return '이탈 방지' #구매는 높으나 최신성은 낮음 -> 다시 불러들어야 함
elif score in ['31','21']:
return '구매 유도' #최신성은 높으나 구매는 낮음 -> 구매를 유도해야 함
rm_score['category'] = rm_score['rm_score'].apply(categorize_customer)fig = px.treemap(data_frame = rm_score, path=['category'], values='customer_count', color_discrete_sequence=px.colors.qualitative.Pastel1)
fig.show()
☞ 결론
- 1) 시간의 흐름에 따라 매출, 주문고객수, 주문단가의 추이는 어떻게 달라지는가?
- 매출과 주문고객수는 우상향(점점 상향), 주문단가는 유지
- 2)리텐션 분석 : 시간의 흐름에 따라 고객들은 얼마나 남고 얼마나 이탈했는가?
- Month1 리텐션이 최근으로 오며 상승 중이고
- 2011-11월에 고객 재방문이 늘었음!!
- 3) RFM 분석
- 최우수 : 최신성, 구매 모두 상당히 높음
- 우수 : 최신성, 구매 모두 높음
- 휴면 : 최신성, 구매 모두 낮음
- 이탈방지 : 구매는 높으나 최신성은 낮음 → 다시 오도록 해야 함
- 구매 유도 : 최신성은 높으나 구매는 낮음 → 구매를 유도해야
4. 사용자 행동 로그 데이터를 활용한 퍼널 분석
◆ 사용자 행동 로그 데이터 - 퍼널 분석
■ 데이터 살펴보기
import pandas as pd
import plotly.express as px
= pd.read_csv('path/ecommerce_behavior.csv')datadata.head()
→ Unnamed:0이 인덱스와 중복으로 삭제처리
data.drop('Unnamed: 0', axis=1, inplace=True)data.head()
■ 질문 만들기
- DAU(일간 활성 사용자수) 추이는?
- 어느 요일에 가장 많이 방문하는가?
- 사이트 체류시간 평균은?
- 조회만 한 유저, 카드에 담은 유저, 구매까지 한 유저별로 체류시간이 어떻게 다른지?
- 퍼널 분석
- 어느 단계에서 유저들이 가장 많이 이탈하는지?
EX) 퍼널 분석
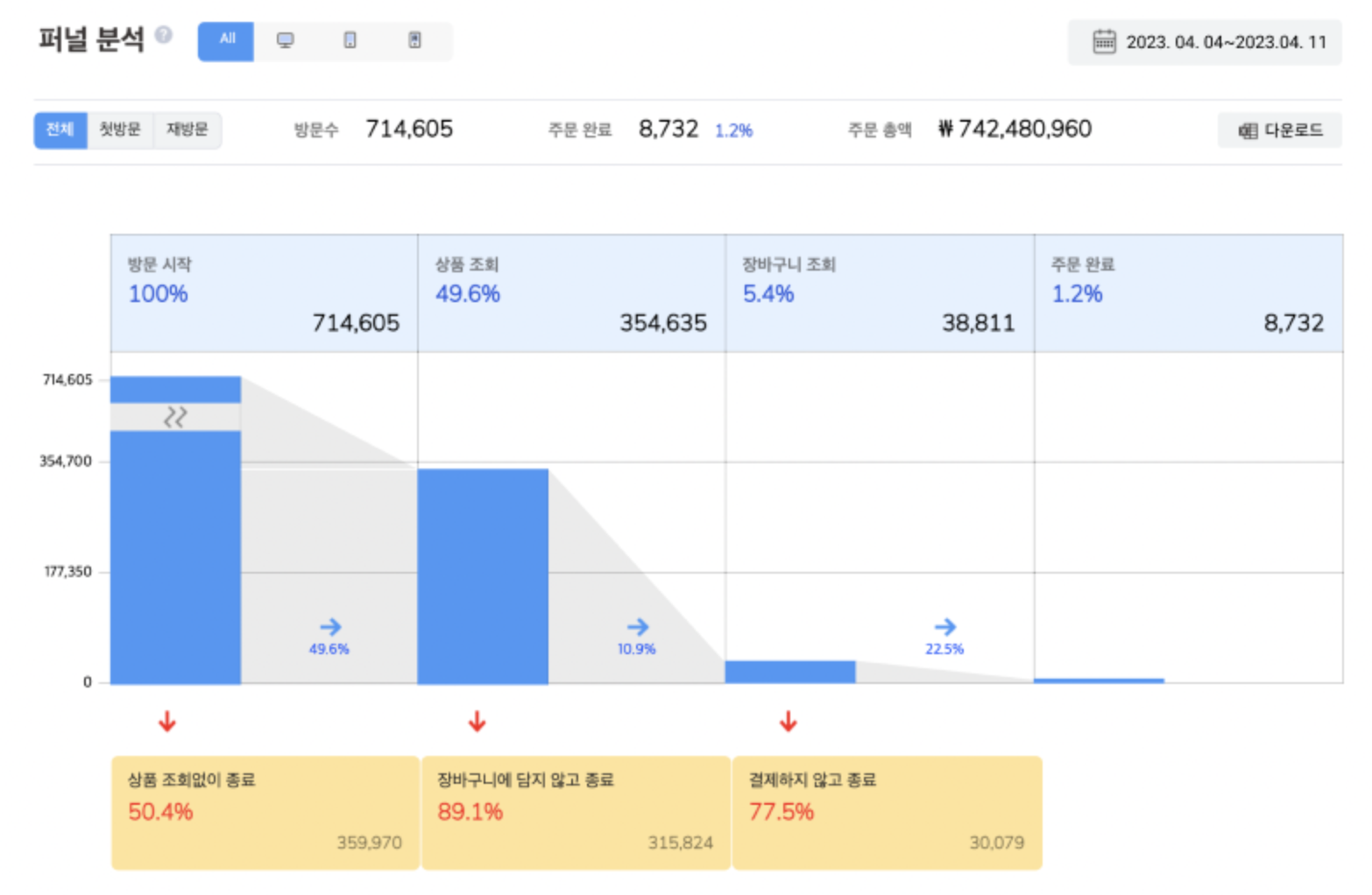
■ 데이터 전처리
data.info()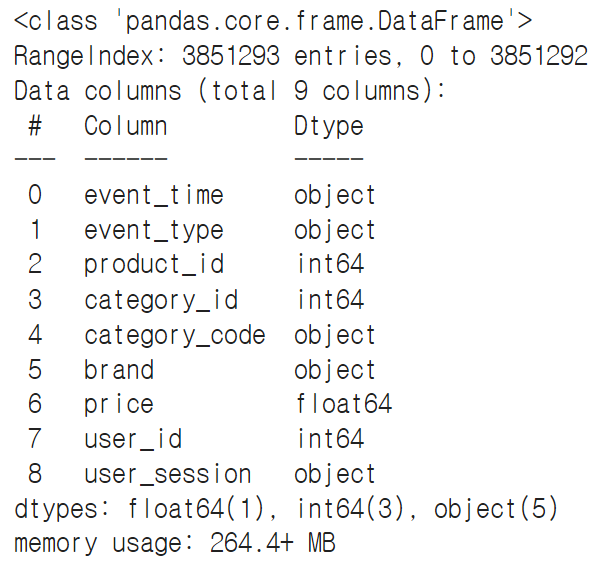
☞ 데이터 타입 변경
#event_time 문자형식 -> date 타입으로 변경
data['event_time'] = pd.to_datetime(data['event_time'], format='%Y-%m-%d %H:%M:%S UTC')data.head()
data.info()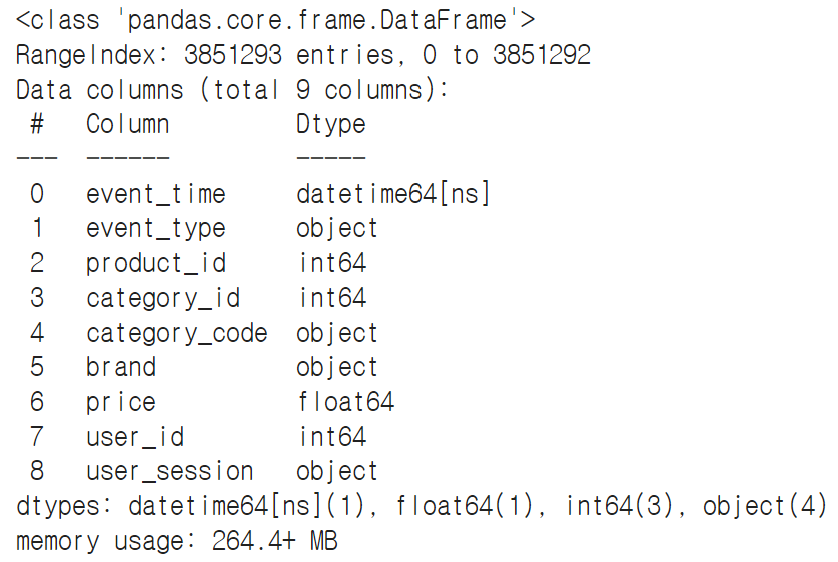
☞ 결측치 제거
data.isna().sum()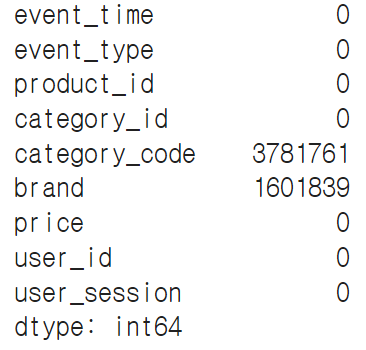
#category_code, brand에 너무 많은 컬럼이 비어있고, 카테고리나 브랜드별로 분석할 계획이 없으므로 해당 컬럼을 제거
data.drop(['category_code','brand'], axis=1, inplace=True)
data.head()
☞ 날씨 컬럼 추가
data['date_ymd'] = data['event_time'].dt.date
data.head()
data.info()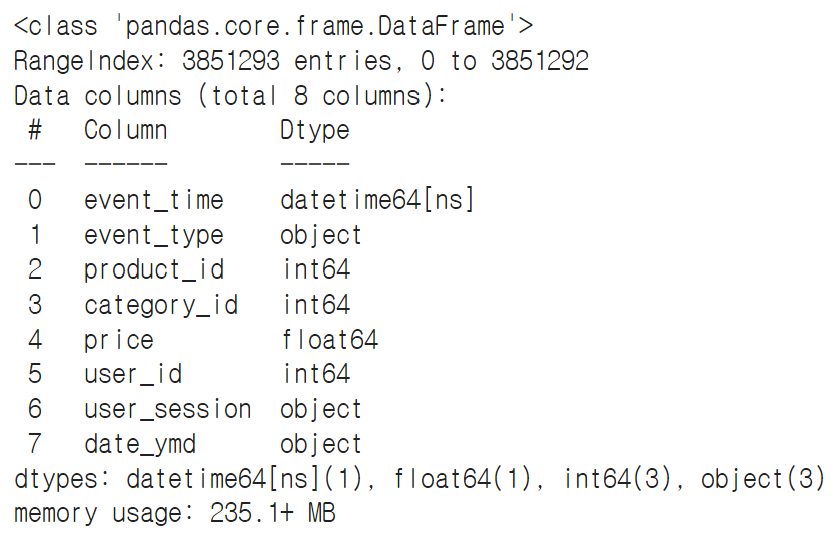
→ date_ymd가 생성되었지만 문자형식에서 date 타입으로 변경
data['date_ymd'] = pd.to_datetime(data['date_ymd'], format='%Y-%m-%d')data.info()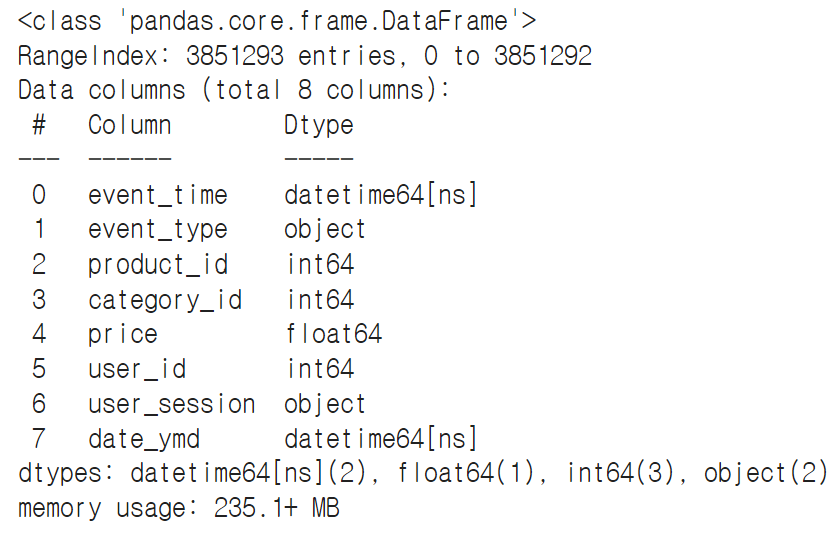
■ EDA, 시각화, 분석
■ EDA
① DAU(일간 활성 사용자수) 추이는?
- 어느 요일에 가장 많이 방문하는지?
#rename 함수 사용하여 컬럼명 변경
dau = data.groupby('date_ymd')[['user_id']].nunique().reset_index().rename({'user_id':'dau'}, axis=1)
dau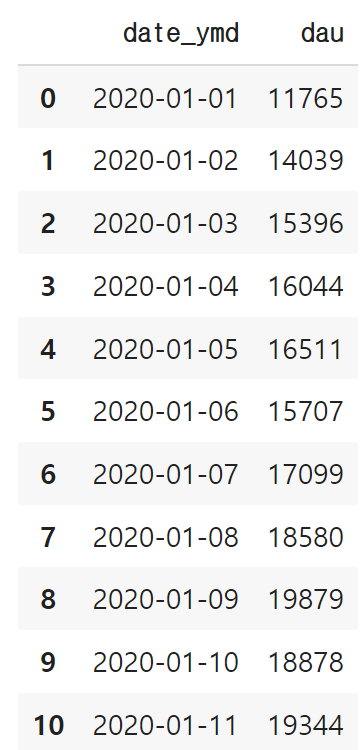
fig = px.line(data_frame = dau, x='date_ymd', y='dau', title='DAU 추이')
fig.show()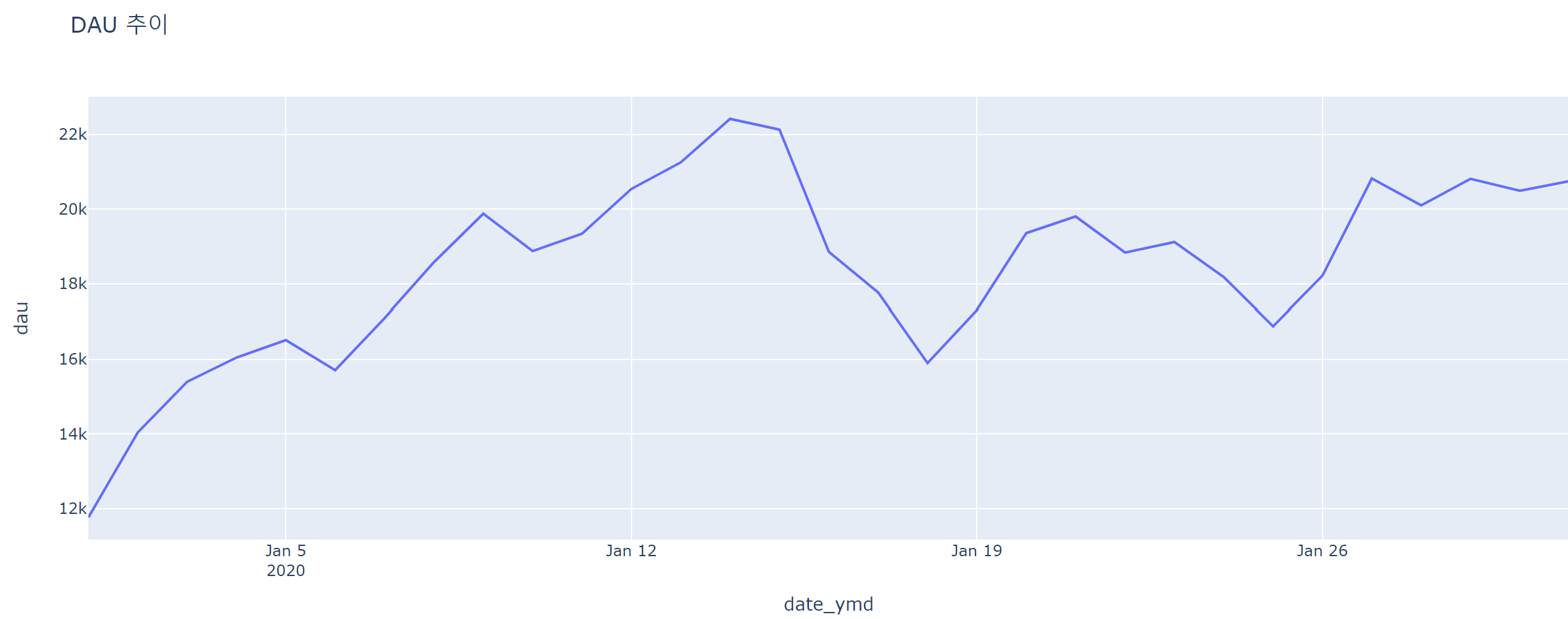
dau['day_of_week'] = dau['date_ymd'].dt.day_name()
dau['day_of_week1'] = dau['date_ymd'].dt.day_of_week
dau.head()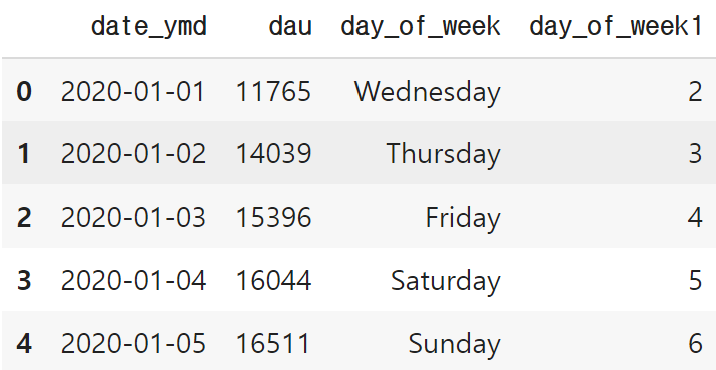
avg_dau_by_dow = dau.groupby(['day_of_week','day_of_week1'])[['dau']].mean().reset_index()
avg_dau_by_dow.sort_values('day_of_week1', inplace=True)
avg_dau_by_dow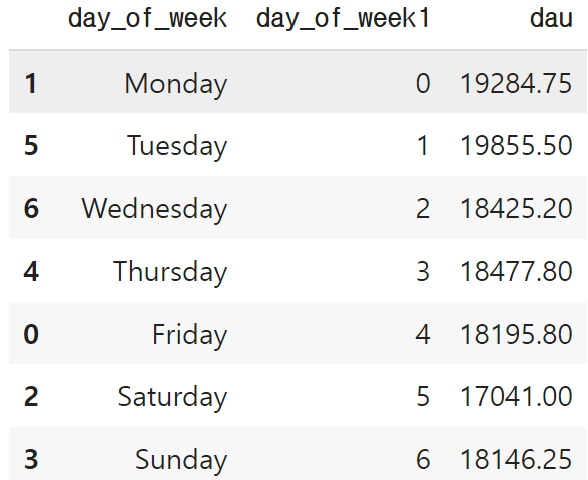
fig = px.bar(data_frame = avg_dau_by_dow, x='day_of_week', y='dau', title='요일별 DAU 평균', width=700, height=500)
fig.show()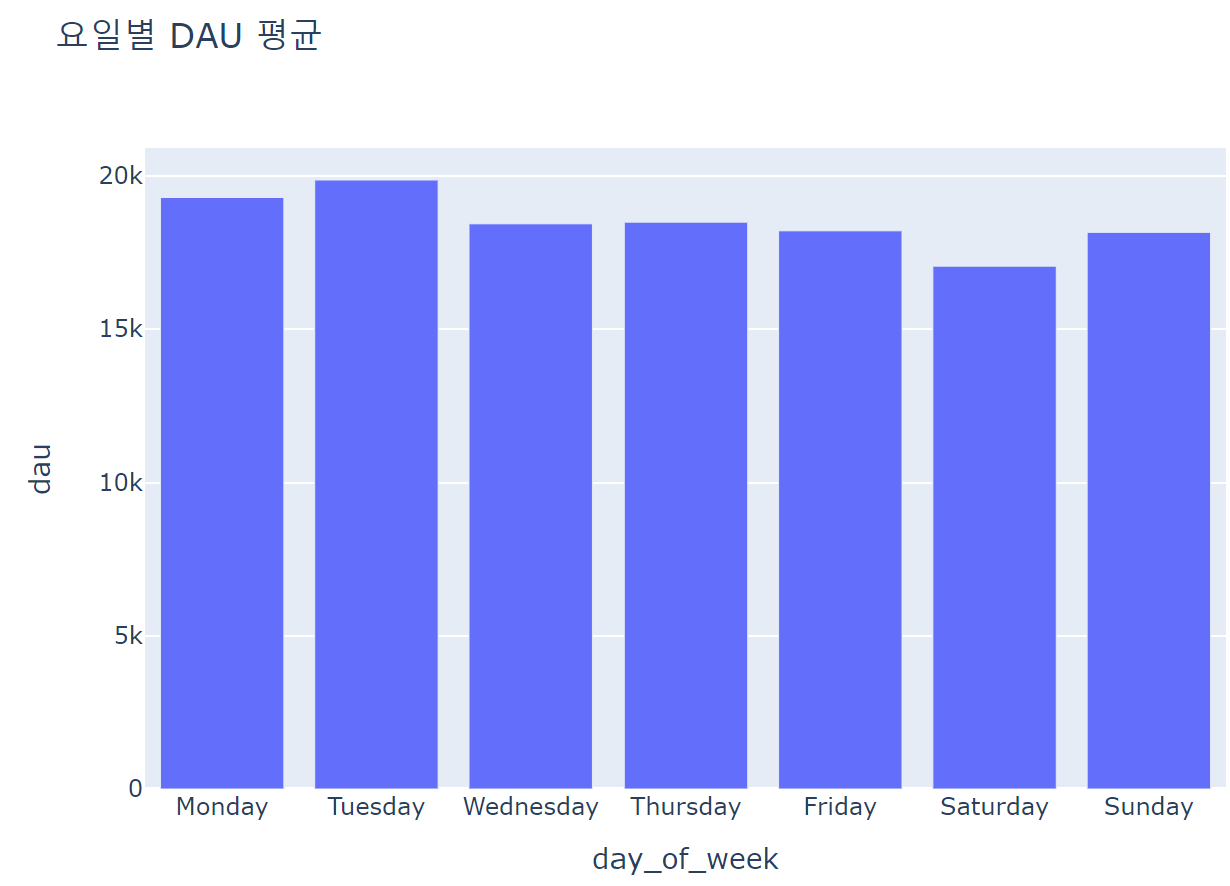
② 사이트 체류시간 평균은?
- 한 세션의 끝에서 시작 시간을 뺀 값을 체류시간으로 정의
data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"').sort_values('event_time')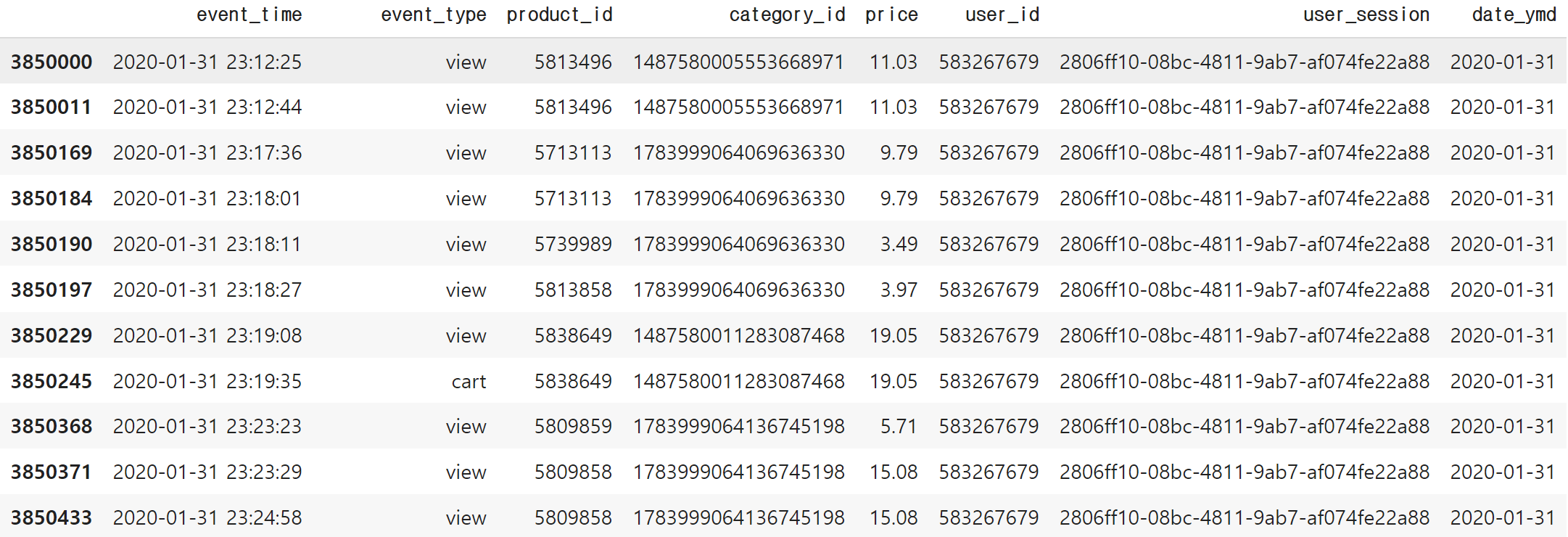
print(data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"')['event_time'].max())
print(data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"')['event_time'].min())
print(data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"')['event_time'].max() - data.query('user_session == "2806ff10-08bc-4811-9ab7-af074fe22a88"')['event_time'].min())
duration = data.groupby('user_session')[['event_time']].agg(['max','min']).reset_index()
duration['duration'] = duration['event_time']['max'] - duration['event_time']['min']duration.columns = ['user_session', 'max', 'min', 'duration']
duration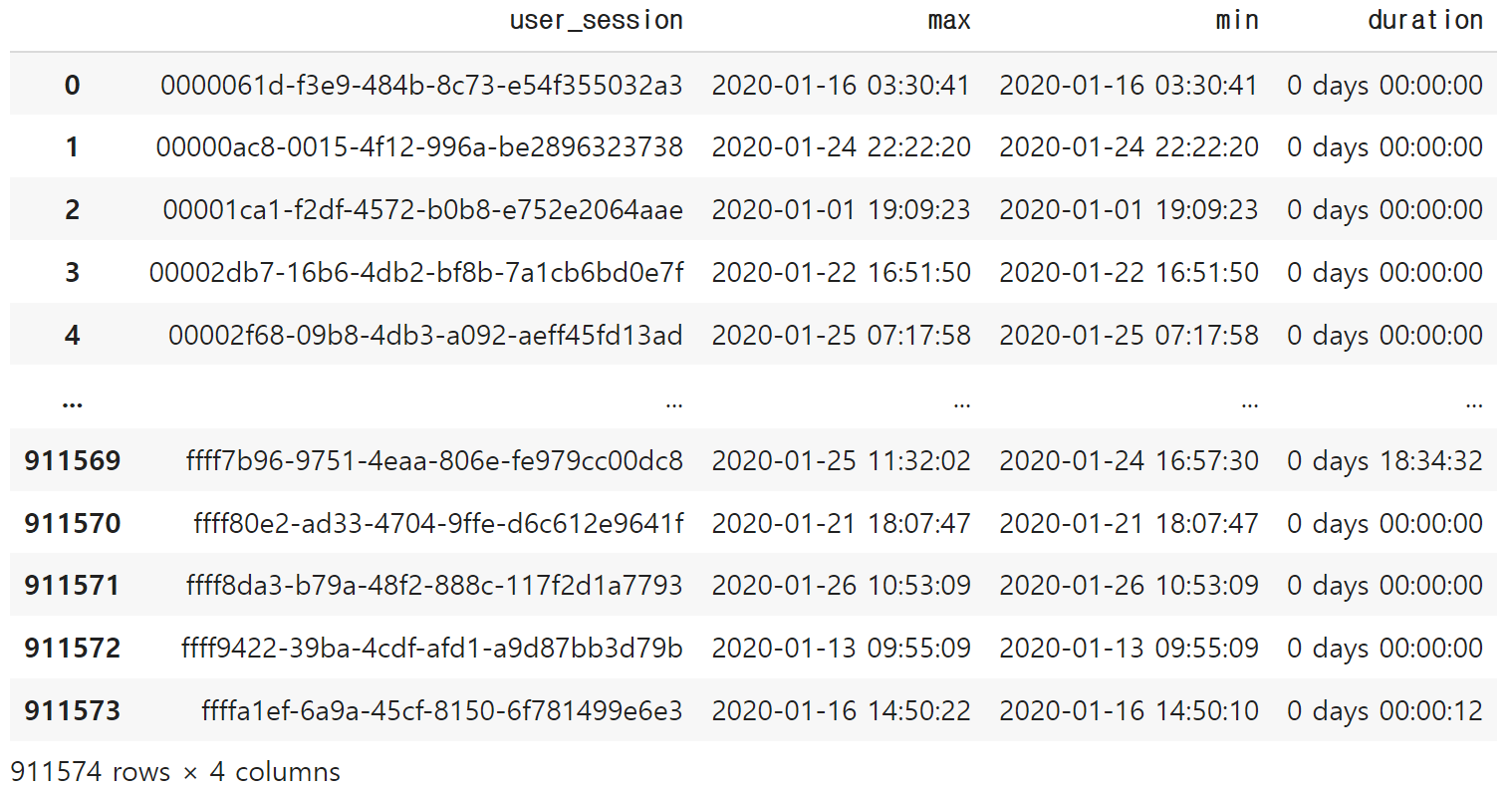
☞ 체류시간 평균 구하기
duration['duration'].mean()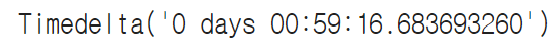
- 조회만 한 유저, 카트에 담은 유저, 구매까지 한 유저별로 체류시간이 어떻게 다른지?
session_pivot = pd.pivot_table(data=data, index='user_session', columns='event_type', values='event_time', aggfunc='count').reset_index().fillna(0)
session_pivot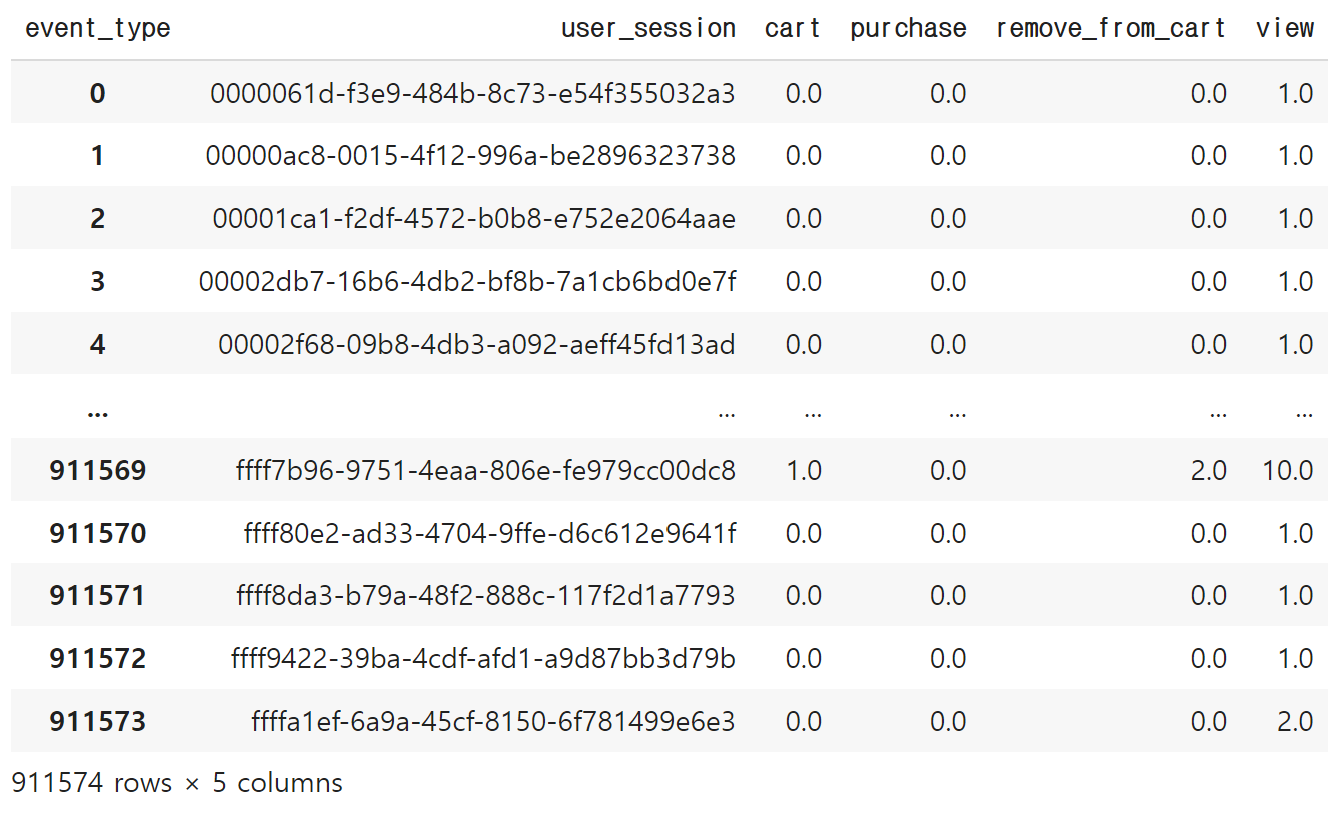
cart_session = list(session_pivot.query('cart > 0')['user_session'])
purchase_session = list(session_pivot.query('purchase > 0')['user_session'])view_session_avg_duration = duration.query('user_session not in @cart_session and user_session not in @purchase_session')['duration'].mean()
cart_session_avg_duration = duration.query('user_session in @cart_session')['duration'].mean()
purchase_session_avg_duration = duration.query('user_session in @purchase_session')['duration'].mean()
print(f'조회만 한 유저의 평균 체류시간: {view_session_avg_duration}')
print(f'카트에 담은 유저의 평균 체류시간: {cart_session_avg_duration}')
print(f'구매까지 한 유저의 평균 체류시간: {purchase_session_avg_duration}')
③ 퍼널 분석 : 어느 단계에서 유저들이 가장 많이 이탈하는가?
funnel = session_pivot[['view','cart','remove_from_cart','purchase']].sum().to_frame().reset_index()
funnel.columns = ['event_type','count']
funnel = funnel.query('event_type != "remove_from_cart"')
funnel
fig = px.funnel(data_frame=funnel, x='event_type', y='count')
fig.update_traces(texttemplate="%{value:,.0f}")
fig.show()
view_to_cart_rate = list(funnel['count'])[1] / list(funnel['count'])[0]
view_to_purchase_rate = list(funnel['count'])[2] / list(funnel['count'])[0]funnel['retain_rate'] = [1, view_to_cart_rate, view_to_purchase_rate]
funnel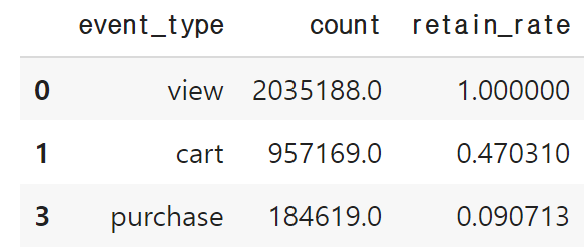
fig = px.funnel(data_frame=funnel, x='event_type', y='retain_rate')
fig.update_traces(texttemplate="%{value:,.2%}")
fig.show()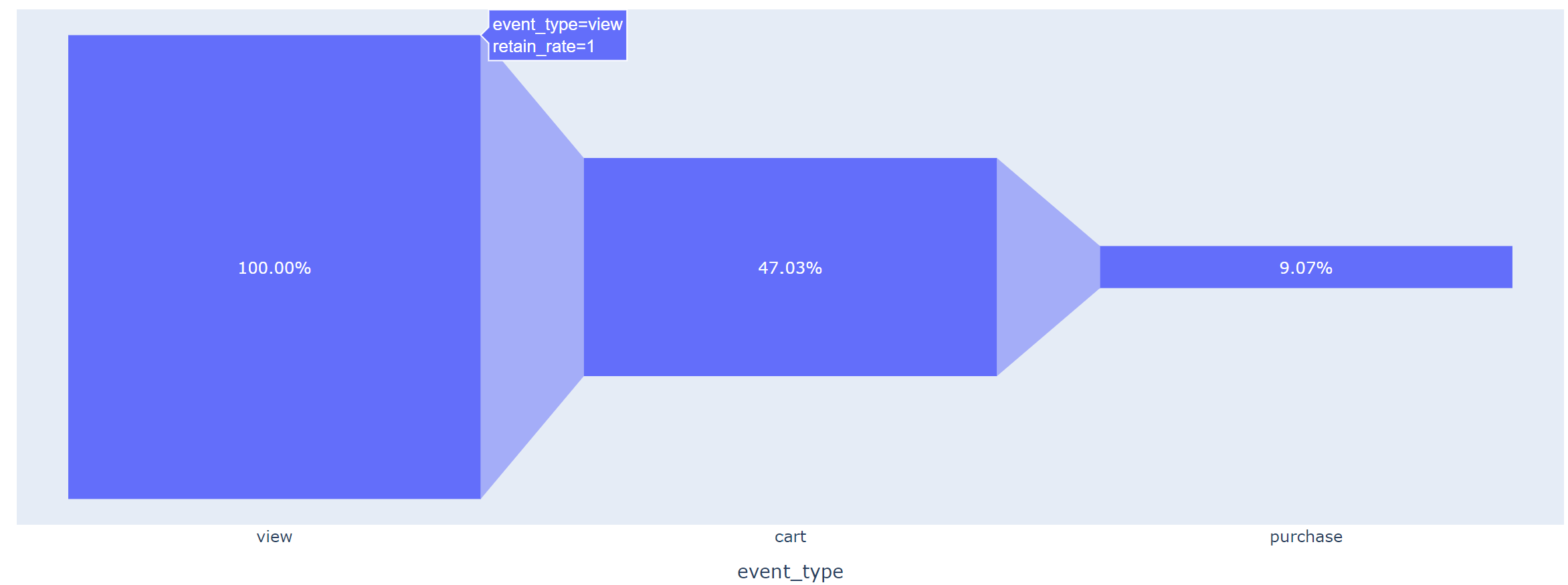
☞ 결론
- DAU(일간 활성 사용자수) 추이는?
- 월 초에서 중순까지 DAU가 증가하다가 이후 유지
- 화요일에 가장 많이 방문, 주말에 사용자수가 줄어듬
- 사이트 체류시간 평균은?
- 체류시간 평균은 약 1시간
- 조회만 한 유저는 약 40분, 카트에 담은 유저는 약 2시간40분, 구매까지 한 유저는 약 6시40분을 체류
- 퍼널 분석
- 상품 조회를 한 후 카트를 담는 단계에서 약 47.3%만 남고, 카트를 담고 구매를 하는 단계에서 약 9% 남음
- 카트를 담고 구매를 하는 단계에서 이탈이 많이 일어남, 해당 단계에서 전환율을 높이기 위한 전략 필요
- 주문서나 혜택, 회원가입에서 문제가 없는지 드릴다운 해볼 수 있음
5. 교통 데이터를 활용한 지리 데이터 시각화
◆ 교통 데이터 - 지리 데이터 시각화 / 서울 열린 데이터 광장에서 데이터 사용
■ 데이터 살펴보기
import pandas as pd
import plotly.express as px
import warnings
warnings.filterwarnings("ignore")#encoding = 'cp949' 넣지 않으면 UTF8에러 발생/기본값이 utf8이 아니기 때문에 cp949 넣어주기
data = pd.read_csv('path/실습5_ 교통 데이터를 활용한 지리 데이터 시각화/서울시 지하철 호선별 역별 시간대별 승하차 인원 정보.csv', encoding = 'cp949')data.head()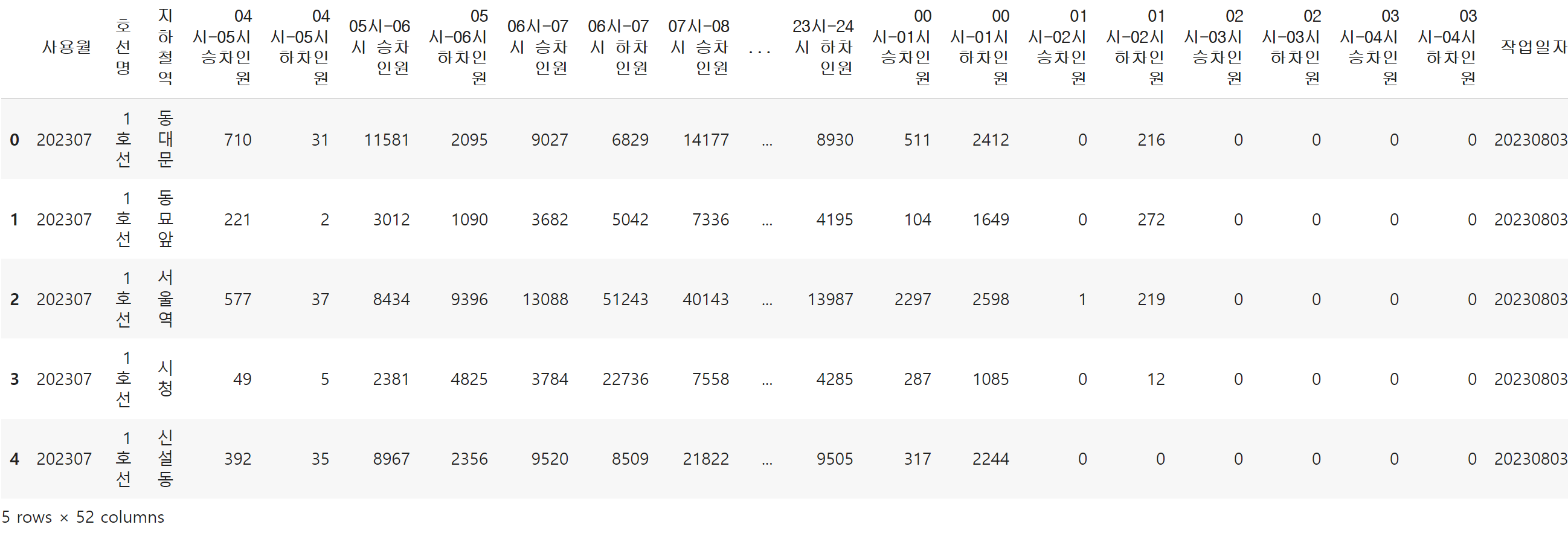
→ 서울시 지하철 승하차인원의 월별 합계
→ 2018년 이후, 2호선, 승차 인원만 분석 예정
■ 질문 만들기
- 승차 인원이 가장 많은 역은?
- 연도별로 혹은 월별로 승차 인원 추이에 차이가 있는가?
- 지하철역 시간대별 유형 군집화
- 지하철역 시간대별 인원 유형 군집화 -> 특정 요인별 확
- 지도에 분석 결과를 시각화하기
■ 데이터 전처리
☞ 날짜 컬럼 추가
data['연도'] = pd.to_datetime(data['사용월'], format='%Y%m').dt.year
data['월'] = pd.to_datetime(data['사용월'], format='%Y%m').dt.month
data.head()
☞ 2018년 이후, 2호선만 필터링 처리
data = data.query('호선명 == "2호선" and 연도 >= 2018')
☞ 지하철역명 통일
sorted(data['지하철역'].unique())
# '('을 기준으로 짜르기
data['지하철역'] = [i[0] for i in data['지하철역'].str.split('(')] #[i~]기분으로 리스트안에 0번째
sorted(data['지하철역'].unique())
☞ 승차 인원만 추출하기
# 이렇게 리스트로 만들어서 확인해보기
[i for i in data.columns if '승차' in i]
on_col = [i for i in data.columns if '승차' in i]
data = data[['사용월','연도','월','지하철역']+on_col]
data.head()
■ EDA, 시각화, 분석
① 승차 인원이 가장 많은 역은?
☞ 합계 컬럼 만들기
data['합계'] = data[on_col].sum(axis=1)
data.head()
☞ 지하철역별 월평균 승차 인원 구하기
data_mean = data.groupby('지하철역')[['합계']].mean().reset_index().rename({'합계':'월평균'}, axis=1).sort_values('월평균', ascending=False)
data_mean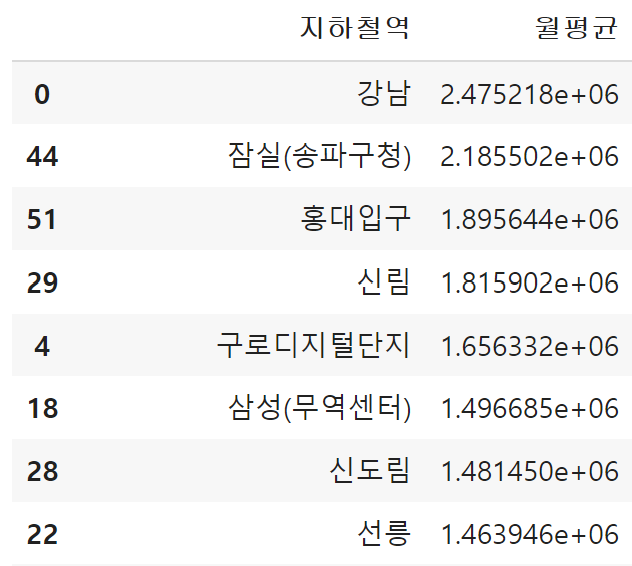
fig = px.bar(data_frame = data_mean, x='지하철역', y='월평균', title='지하철역별 월평균 승차인원')
fig.show()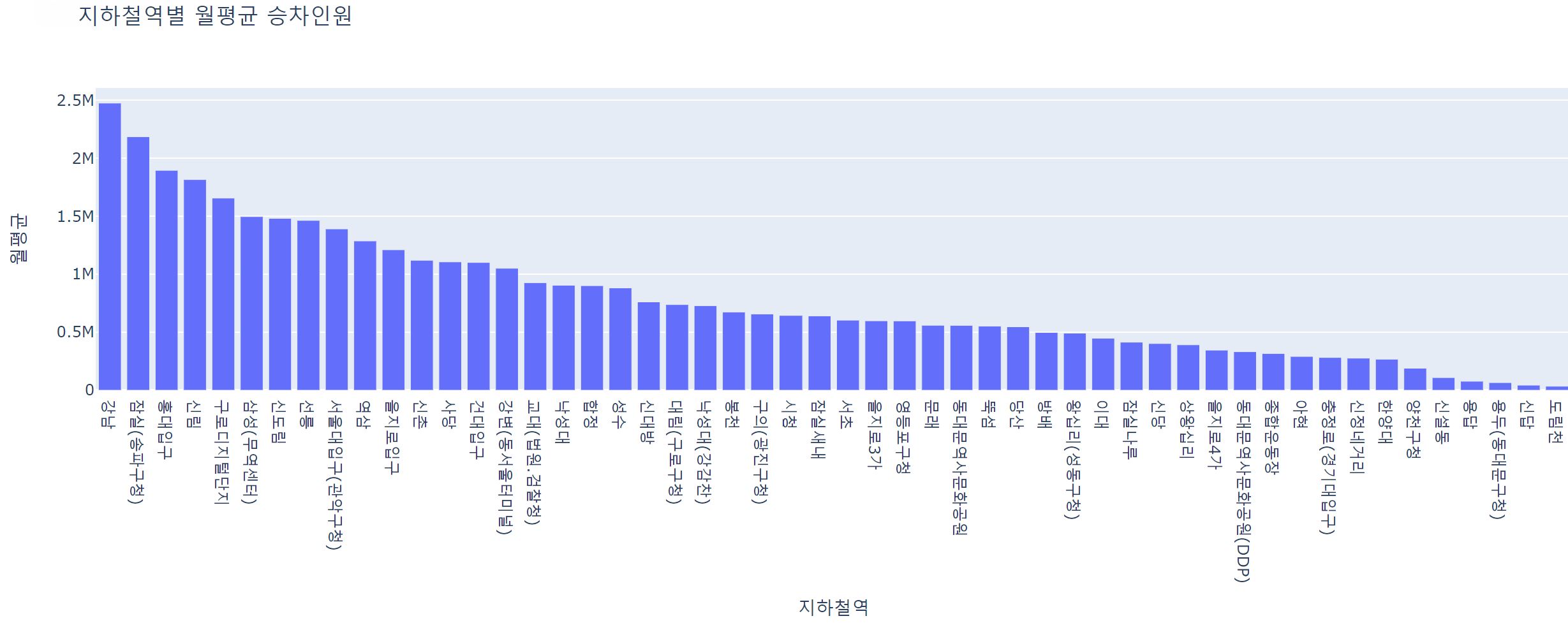
② 연도별로 혹은 월별로 승차 인원 추이에 차이가 있는가?
data.head()
year_sum = data.query('연도 <= 2022').groupby(['연도'])[['합계']].sum().reset_index()
year_sum['연도'] = year_sum['연도'].astype(str) #시각화를 위한 연도 데이터 타입을 문자형으로 변경
fig = px.line(data_frame=year_sum, x='연도', y='합계')
fig.show()
month_sum = data.query('연도 <= 2022').groupby(['월'])[['합계']].sum().reset_index()
month_sum['월'] = month_sum['월'].astype(str)
fig = px.line(data_frame=month_sum, x='월', y='합계')
fig.show()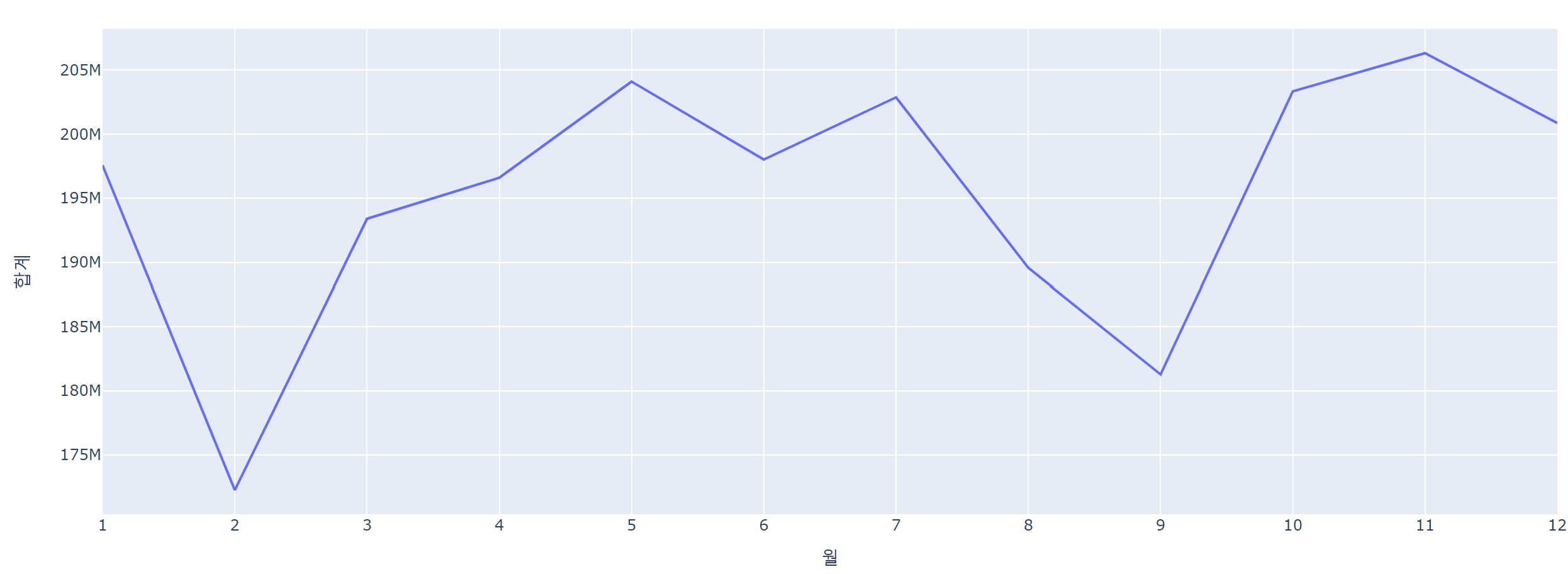
③ 시간대별로 가장 승차인원이 많은 역은?
top10 = data_mean.sort_values('월평균', ascending=False).head(10)['지하철역']
top10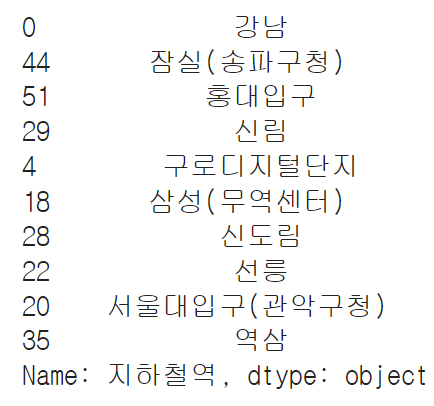
#주요 역 10개만 필터링하여 시간당 월평균 인원수 구하기
top10 = data_mean.sort_values('월평균', ascending=False).head(10)['지하철역']
top10_mean_hour = data.query('지하철역 in @top10').groupby('지하철역')[on_col].mean()
top10_mean_hour.columns = [i[:3] for i in top10_mean_hour.columns]#전체 기준 히트맵
top10_mean_hour.style.background_gradient(cmap='pink_r', axis=None).format('{:.0f}')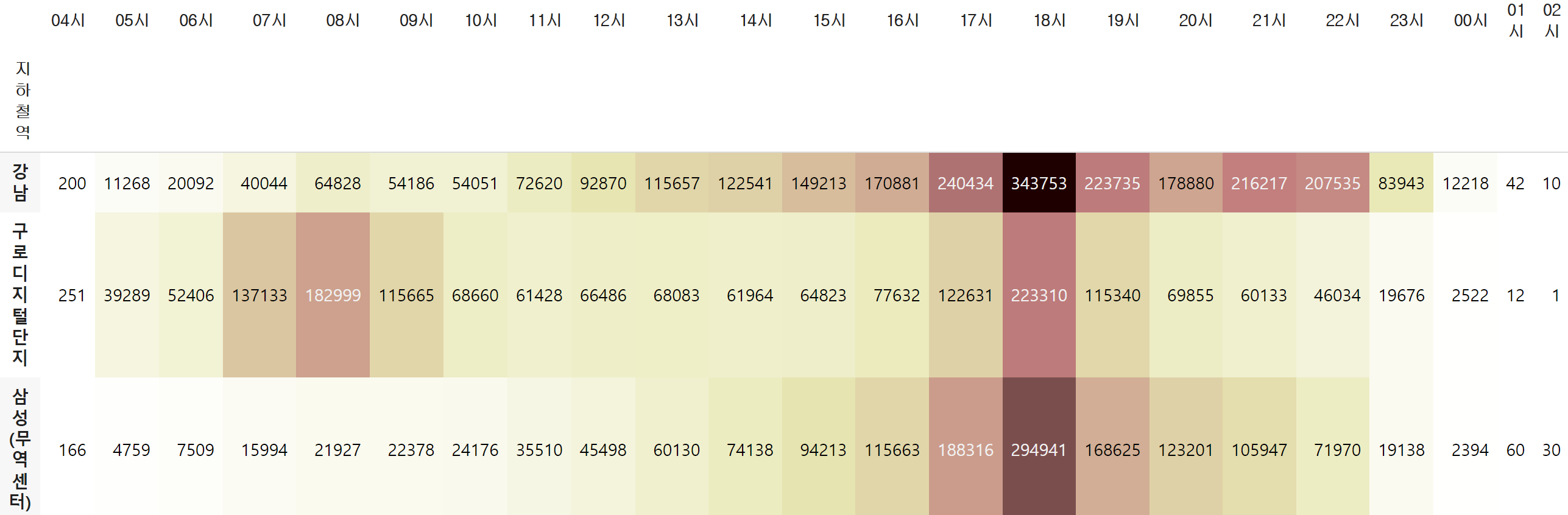
#행 기준 히트맵
top10_mean_hour.style.background_gradient(cmap='pink_r', axis=1).format('{:.0f}')
④ 지하철역 시간대별 인원 유형 군집화
☞ 승차 인원으로 유형 군집화
hour_mean = data.groupby('지하철역')[on_col].mean()
hour_mean.columns = [i[:3] for i in hour_mean.columns]
hour_mean_pct = hour_mean.div(hour_mean.sum(axis=1), axis=0)from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
model = KMeans()
visualizer = KElbowVisualizer(model, k=(1,10))
visualizer.fit(hour_mean_pct)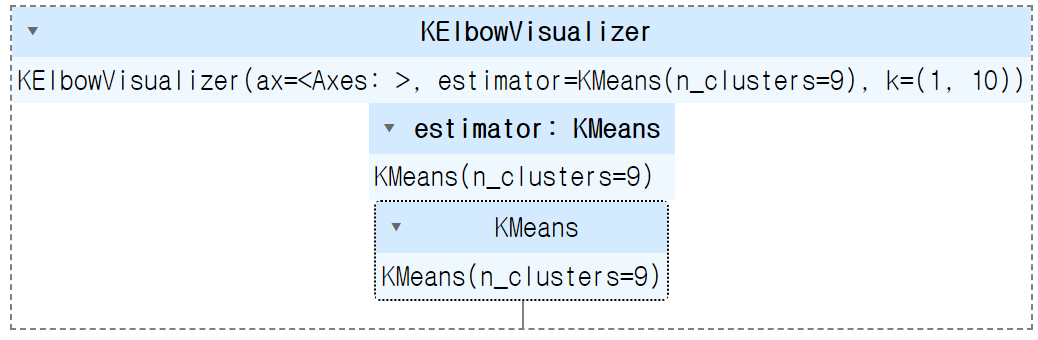
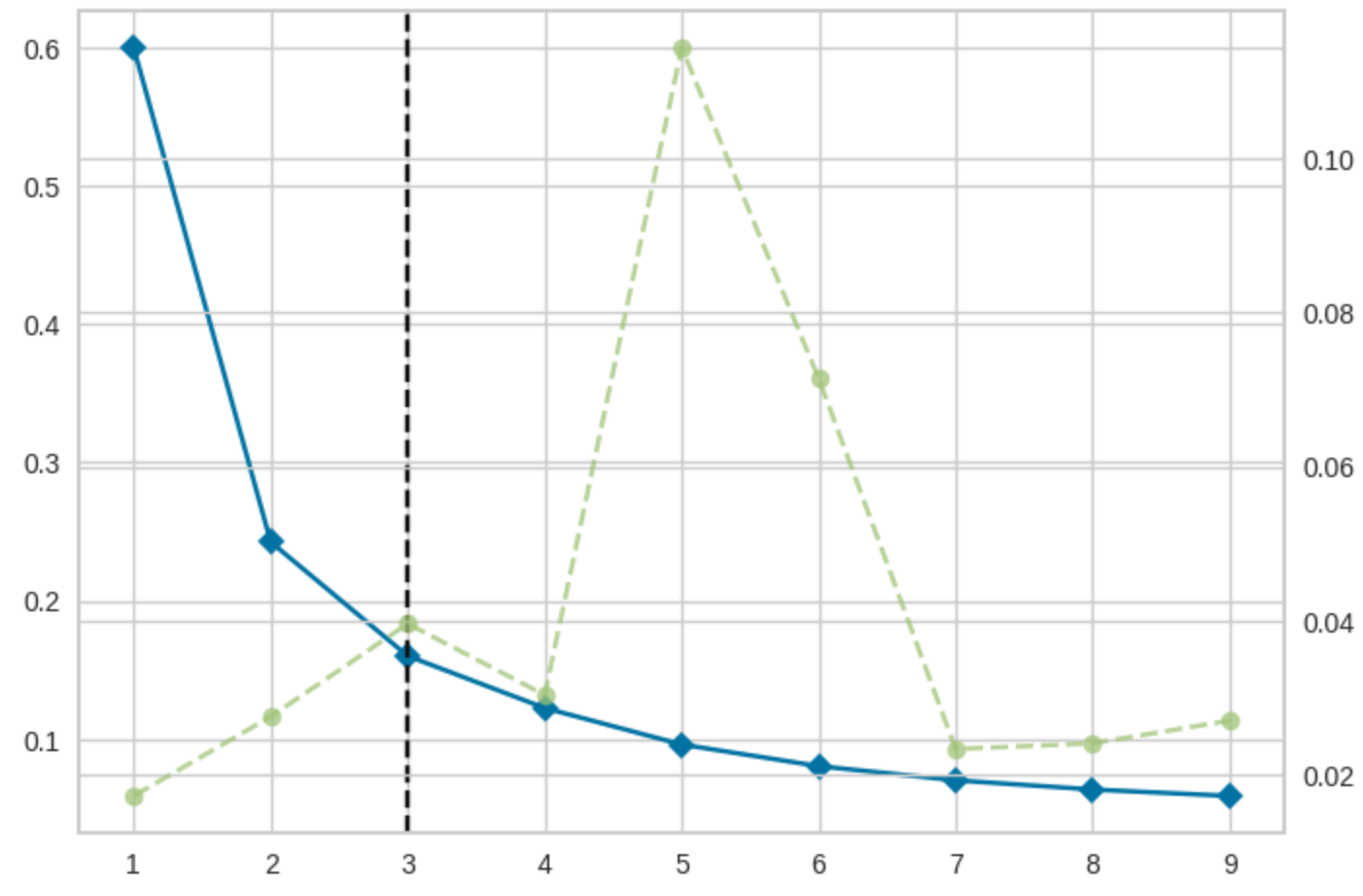
k = 3
model = KMeans(n_clusters = k, random_state = 10) #KMeans 모델을 정의
model.fit(hour_mean_pct) #학습
hour_mean_pct['cluster'] = model.fit_predict(hour_mean_pct).astype(str) #클러스터 열 만들기fig = px.scatter(data_frame = hour_mean_pct[['08시','18시','cluster']].reset_index(), x='08시', y='18시', color='cluster', width=700, height=600, title='시간대별 승차 인원 비중 군집화', hover_name='지하철역')
fig.show()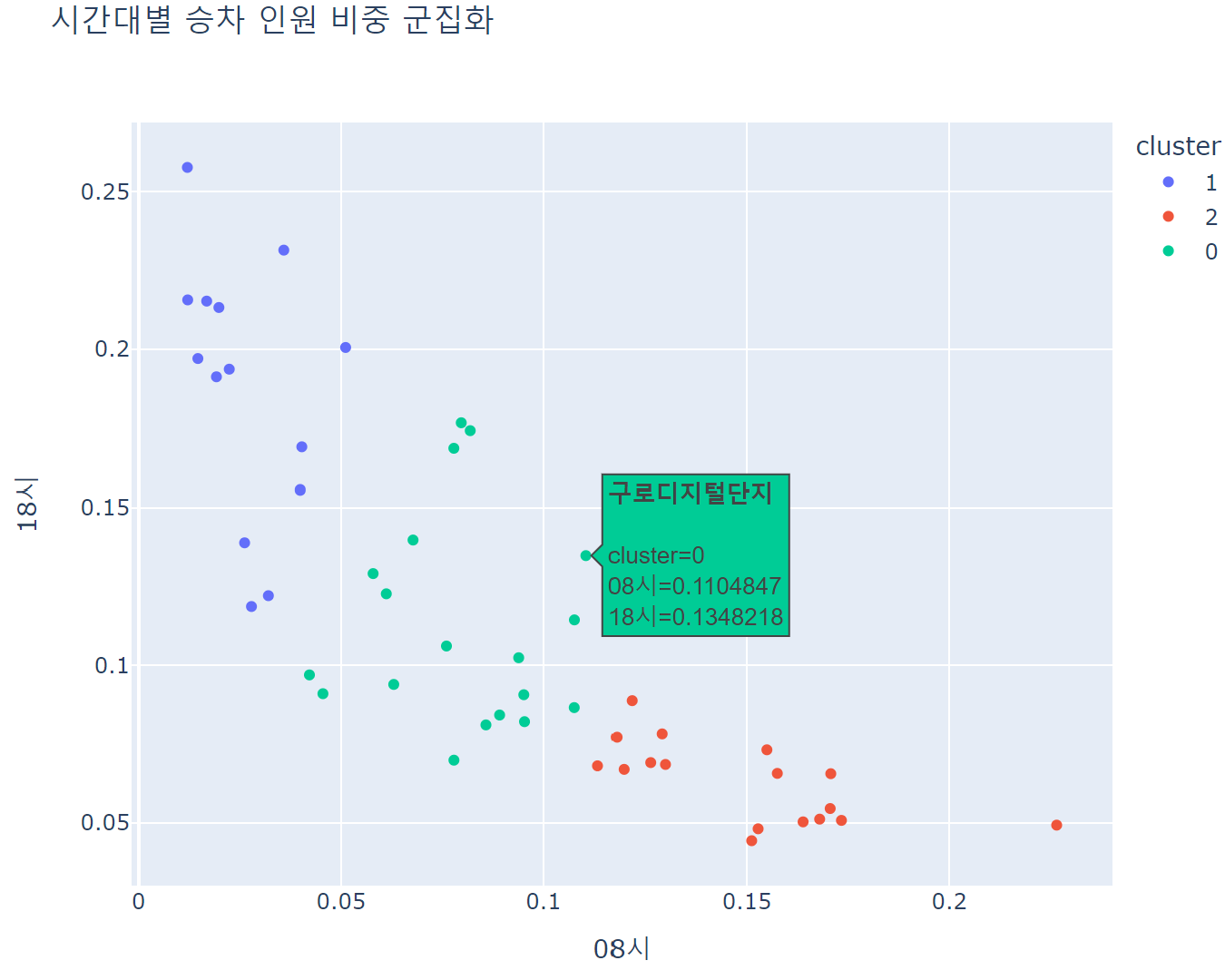
for i in range(k):
print(f'cluster {i}')
print(list(hour_mean_pct.query(f'cluster == "{i}"').index))
⑤ 지도에 분석 결과를 시각화
- 8시 승차 인원과 18시 승차 인원을 지도에 시각화해보자
- 지하철역별 위도 경도 데이터 전처리
coordinate = pd.read_csv('/content/drive/MyDrive/강의자료_황수현_Python/Part3) 파이썬 데이터 분석 프로젝트/data/실습5: 교통 데이터를 활용한 지리 데이터 시각화/서울시 역사마스터 정보.csv', encoding='cp949')
coordinate.head()
coordinate = coordinate.query('호선 == "2호선"')
coordinate['역사명'] = [i[0] for i in coordinate['역사명'].str.split('(')]
coordinate.rename({'역사명':'지하철역'}, axis=1, inplace=True)
coordinate
hour_mean_merge = hour_mean.reset_index()[['지하철역','08시','18시']]
coordinate_merge = coordinate[['지하철역','위도','경도']]
hour_mean_coor = pd.merge(hour_mean_merge, coordinate_merge, on='지하철역')hour_mean_coor['cluster'] = model.fit_predict(hour_mean_pct).astype(str)
hour_mean_coor.head()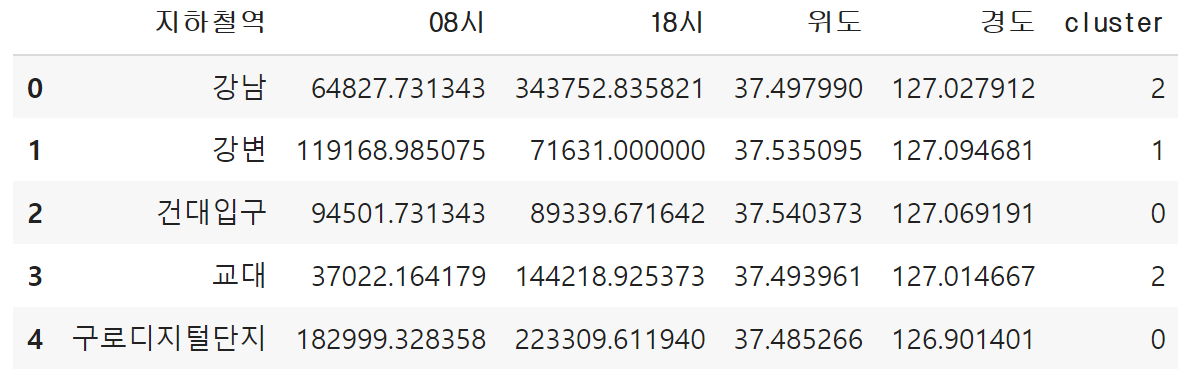
☞ 지도에 시각화
import folium
from folium import pluginscenter = [37.541, 126.986] #서울 중간
m = folium.Map(location=center, zoom_start=12)
m.add_child(plugins.HeatMap(zip(hour_mean_coor['위도'], hour_mean_coor['경도'], hour_mean_coor['08시'])))
m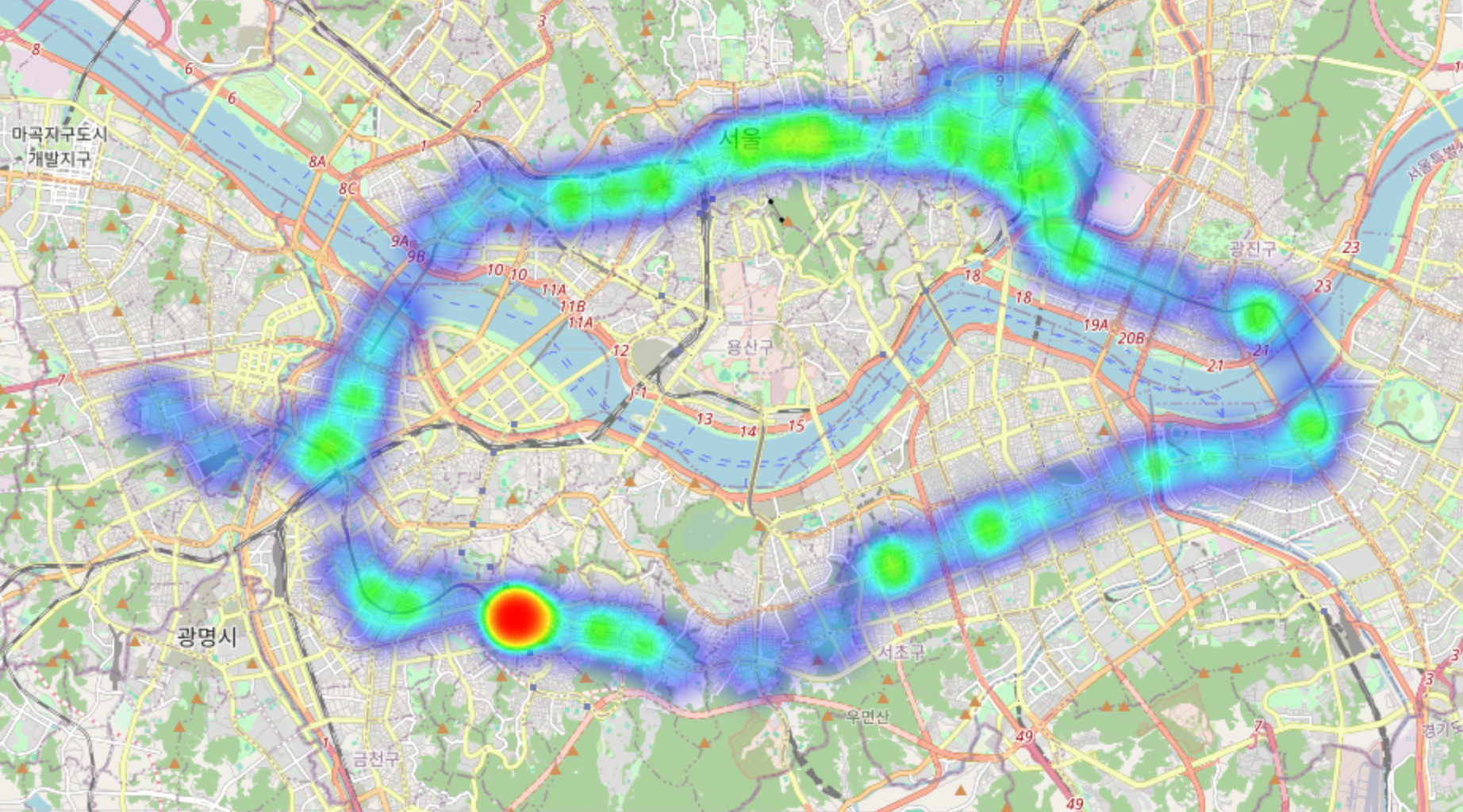
m = folium.Map(location=center, zoom_start=12)
m.add_child(plugins.HeatMap(zip(hour_mean_coor['위도'], hour_mean_coor['경도'], hour_mean_coor['18시'])))
m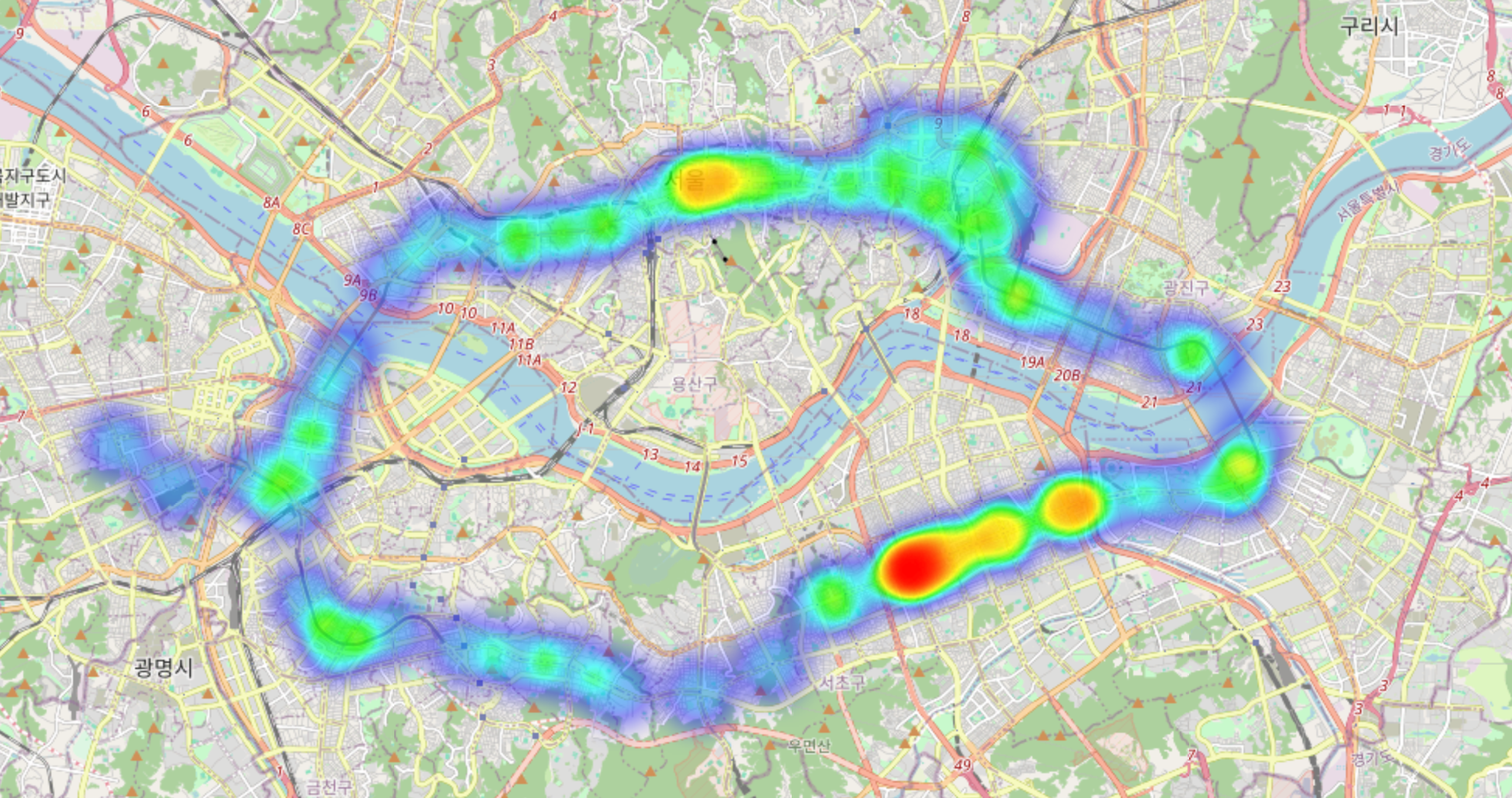
☞ 승차 인원 유형을 지도에 시각화
m = folium.Map(location=center, zoom_start=12)
for idx in hour_mean_coor.index:
lat = hour_mean_coor.loc[idx, '위도']
long = hour_mean_coor.loc[idx, '경도']
title = hour_mean_coor.loc[idx, '지하철역']
if hour_mean_coor.loc[idx, 'cluster'] == "0":
color = '#000000'
elif hour_mean_coor.loc[idx, 'cluster'] == "1":
color = '#3A01DF'
else:
color = '#DF0101'
folium.CircleMarker([lat, long]
, radius=18
, color = color
, fill = color
, tooltip = title).add_to(m)
m
☞ 정리
- 승하차 인원이 가장 많은 역은?
- 강남, 잠실, 홍대입구, 신림, 구로디지털단지 등등
- 연도별로 혹은 월별로 승차 인원 추이에 차이가 있는가?
- 코로나가 시작된 2020년, 2021년에 인원이 많이 줄었고 2022년도부터 다시 회복 중
- 시간대별로 가장 승차인원이 많은 역은?
- 아침에 비교적 승차 인원이 많은 역과 저녁에 비교적 승차 인원이 많은 역이 있음을 히트맵으로 파악
- 지하철역 시간대별 인원 유형 군집화
cluster 0: 아침과 저녁 승차인원 비율이 비교적 비슷
['건대입구', '구로디지털단지', '당산', '도림천', '문래', '방배', '사당', '신당', '신도림', '신설동', '신촌', '영등포구청', '왕십리', '이대', '잠실', '종합운동장', '충정로', '합정', '홍대입구']
cluster 1: 저녁 승차인원 비율이 높음
['강남', '교대', '동대문역사문화공원', '뚝섬', '삼성', '서초', '선릉', '성수', '시청', '역삼', '을지로3가', '을지로4가', '을지로입구', '한양대']
cluster 2: 아침 승차인원 비율이 높음
['강변', '구의', '낙성대', '대림', '봉천', '상왕십리', '서울대입구', '신답', '신대방', '신림', '신정네거리', '아현', '양천구청', '용답', '용두', '잠실나루', '잠실새내']
[5] 지도에 분석 결과를 시각화
5. 지도에 분석 결과를 시각화
- cluster 0 : 주거와 상업 시설, 회사가 비슷하게 분포한 지역
- cluster 1 : 회사가 많이 분포한 지역
- cluster 2 : 주거 지역이 많이 분포한 지역
크롤링(3주차 이어서)
◆ 구글 뉴스기사 크롤링
☞ 구글 뉴스기사 크롤링 실습
☞ jupyter note 먼저 실행하기
☞ 전체 제목 수집
from selenium import webdriver
from selenium.webdriver.common.by import By
# 브라우저 창
browser = webdriver.Chrome()
# 데이터를 수집하고자 하는 창으로 이동
url = 'https://www.google.com/search?q=%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D%EA%B0%80&newwindow=1&sca_esv=fc0f42412f6fa1c1&biw=1376&bih=797&tbm=nws&sxsrf=ADLYWIKePkO9g5j7w-Feo_DIls3UppJdrw%3A1715240419549&ei=4308ZruFIZKB2roP-eecgA0&ved=0ahUKEwj7gqW_iICGAxWSgFYBHfkzB9AQ4dUDCA0&uact=5&oq=%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D%EA%B0%80&gs_lp=Egxnd3Mtd2l6LW5ld3MiEuuNsOydtO2EsOu2hOyEneqwgDIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgARI5ChQkQRYoShwDngAkAEDmAGxAqAB-yKqAQgxLjIyLjIuMbgBA8gBAPgBAZgCEqAC3guoAgDCAgUQIRigAcICCxAAGIAEGLEDGIMBwgIEEAAYA8ICCBAAGIAEGLEDwgINEAAYgAQYsQMYgwEYDcICBhAAGAMYDcICCBAAGIAEGKIEwgIIEAAYogQYiQXCAgoQABiABBhDGIoFmAMAiAYBkgcIMTAuNy4wLjGgB6Ru&sclient=gws-wiz-news'
browser.get(url)# 제목
# find_element+'s' : 찾을 요소 전부(리스트가 된다)
#browser.find_elements(By.CLASS_NAME, 'n0jPhd')
#type(browser.find_elements(By.CLASS_NAME, 'n0jPhd')) / 찾을 타입
#len(browser.find_elements(By.CLASS_NAME, 'n0jPhd')) / 길이
titles = browser.find_elements(By.CLASS_NAME, 'n0jPhd')
for element in titles:
print(element.text) #문자데이터는 .text넣기
titles = ['element1', 'element2', 'element3']
for i in titles:
print(i)
☞ n개 링크 수집
# N개 링크 수집
links = browser.find_elements(By.CLASS_NAME, 'WlydOe')
num = 0
for i in links:
num += 1
link = i.get_attribute('href')
print(f'{num}번째 링크: {link}')
☞ 전체 링크 수
# 링크
browser.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
links = browser.find_elements(By.CLASS_NAME, 'WlydOe')
#browser.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')에서 get은 사용x
for i in links:
print(i.get_attribute('href')) # .get_attribute('href') 사용하여 링크로 가져온다
☞ 전체 링크 다른 방법
# 전체 링크
browser.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
links = browser.find_elements(By.CLASS_NAME, 'WlydOe')
num = 0
for i in links:
num += 1
link = i.get_attribute('href')
print(f'{num}번째 요소 : {i}, 링크: {link}')
→ 에러 : 코드에서 element를 보니 s를 붙이지 않아서 for문을 돌릴 수 없다는 에러

☞ 여러 요소 한 번에 가져오기 / 1 페이지만
# 내가 한것/이렇게하면 맨 아래만 실행...ㅠ
containers = browser.find_elements(By.CLASS_NAME, 'SoaBEf')
#len(containers)
for i in containers:
# 제목
title = i.find_element(By.CLASS_NAME, 'n0jPhd').text
# 내용
content = i.find_element(By.CLASS_NAME, 'GI74Re').text
# 언론사
press = i.find_element(By.CLASS_NAME, 'MgUUmf').text
# 작성시간
time = i.find_element(By.CLASS_NAME, 'LfVVr').text
# 링크
link = i.find_element(By.CLASS_NAME, 'WlydOe')
#print(title)
#print(link.get_attribute('href'))
☞ 여러 요소 한 번에 가져오기 / 1~5 페이지
# 강사님 풀이
containers = browser.find_elements(By.CLASS_NAME, 'SoaBEf')
# 여러 데이터를 실행하기 위해서 만들기
data_list = [] # 데이터 저장공간
for i in containers:
title = i.find_element(By.CLASS_NAME, 'n0jPhd').text
content = i.find_element(By.CLASS_NAME, 'GI74Re').text
press = i.find_element(By.CLASS_NAME, 'MgUUmf').text
time = i.find_element(By.CLASS_NAME, 'LfVVr').text
link = i.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
# dict 형태로 하기{'key':'value','key2','value2'}
data_list.append({
'제목' : title,
'내용' : content,
'언론사' : press,
'작성시간' : time,
'링크' : link
})
data_list # 딕셔너리 형태로 data_list에 저장
☞ 저장
import pandas as pd
pd.__version__
# DataFrame으로 만들어보기
pd.DataFrame(data_list)
→ 이렇게 저장을 했더니 엑셀에서 한글이 깨짐 발생
df = pd.DataFrame(data_list)
df.to_csv('google_news.csv')
# 한글깨짐 발생으로 encoding 해주기
df = pd.DataFrame(data_list)
df.to_csv('google_news.csv', encoding='euc-kr')
☞ 2페이지 넘어가기
# 2페이지 버튼
# XPATH: 고유한 경로를 의미
# //*[@id="botstuff"]/div/div[3]/table/tbody/tr/td[3]/a
browser.find_element(By.XPATH, '//*[@id="botstuff"]/div/div[3]/table/tbody/tr/td[3]/a').click()
→ 페이지 이동이 안된다면 페이지가 start=이 번호에 따라 바뀌는 걸 확인, for문으로 변경해 주기
#/search?q=데이터분석가&start=0
#/search?q=데이터분석가&start=10
#/search?q=데이터분석가&start=20
#/search?q=데이터분석가&start=30
for i in range(0, 50, 10):
url = f'/search?q=데이터분석가&start={i}'
print(url)
for i in range(0,30, 10):
url = f'https://www.google.com/search?q=%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D%EA%B0%80&newwindow=1&sca_esv=fc0f42412f6fa1c1&tbm=nws&sxsrf=ADLYWIJbzeIzdc0EnoffSz16nUrodx0Lxw:1715661460648&ei=lOpCZuiYJ4Sivr0Pv4ePwAs&start={i}&sa=N&ved=2ahUKEwjosqr_qIyGAxUEka8BHb_DA7g4MhDy0wN6BAgCEAQ&biw=749&bih=797&dpr=2.5'
print(url)
☞ 페이지 3초 간격으로 넘기
# time.sleep 사용시 벤을 피할 수 있음
# 1~3페이지까지 3초간격으로 이동
import time
for i in range(0,30, 10):
url = f'https://www.google.com/search?q=%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D%EA%B0%80&newwindow=1&sca_esv=fc0f42412f6fa1c1&tbm=nws&sxsrf=ADLYWIJbzeIzdc0EnoffSz16nUrodx0Lxw:1715661460648&ei=lOpCZuiYJ4Sivr0Pv4ePwAs&start={i}&sa=N&ved=2ahUKEwjosqr_qIyGAxUEka8BHb_DA7g4MhDy0wN6BAgCEAQ&biw=749&bih=797&dpr=2.5'
browser.get(url)
time.sleep(3)
☞ 페이지 3초 간격으로 넘기고 3페이지까지 데이터 저장
import time
data_list = [] # 데이터 저장공간
for i in range(0,30, 10):
url = f'https://www.google.com/search?q=%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D%EA%B0%80&newwindow=1&sca_esv=fc0f42412f6fa1c1&tbm=nws&sxsrf=ADLYWIJbzeIzdc0EnoffSz16nUrodx0Lxw:1715661460648&ei=lOpCZuiYJ4Sivr0Pv4ePwAs&start={i}&sa=N&ved=2ahUKEwjosqr_qIyGAxUEka8BHb_DA7g4MhDy0wN6BAgCEAQ&biw=749&bih=797&dpr=2.5'
browser.get(url)
time.sleep(3)
containers = browser.find_elements(By.CLASS_NAME, 'SoaBEf')
#data_list = [] # 데이터 저장공간
for i in containers:
title = i.find_element(By.CLASS_NAME, 'n0jPhd').text
content = i.find_element(By.CLASS_NAME, 'GI74Re').text
press = i.find_element(By.CLASS_NAME, 'MgUUmf').text
rtime = i.find_element(By.CLASS_NAME, 'LfVVr').text
link = i.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
#{'key':'value','key2','value2'}
data_list.append({
'제목' : title,
'내용' : content,
'언론사' : press,
'작성시간' : time,
'링크' : link
})
data_list
# encoding에서 문자에러가 떠 utf-8-sig에 sig 추가하여 에러 무시
df = pd.DataFrame(data_list)
df.to_csv('google_data_news1.csv', encoding='utf-8-sig')
☞ 첫 페이지 포함하여 크롤링하기
num = int(input("몇 페이지까지 크롤링할거야?"))
for i in range(num):
path = f'//*[@id="botstuff"]/div/div[3]/table/tbody/tr/td[{str(i+3)}]/a'
url = browser.find_element(By.XPATH, path)
☞ DBPIA 논문 데이터 크롤링 실습
☞ 내가 푼 것
1. 페이지의 링크 데이터만 모두 수집
# 브라우저 실행
browser = webdriver.Chrome()
keyword = input('검색하고자 하는 키워드를 입력해라잉~ : ')
url = f'https://www.dbpia.co.kr/search/topSearch?searchOption=all&query={keyword}'
print(url)
browser.get(url)
# 내가 작성한 for문 코드
# 1페이지의 링크 데이터만 모두 수집
containers = browser.find_elements(By.CLASS_NAME, 'thesisWrap')
data_list = [] # 데이터 저장공간
for i in containers:
link = i.find_element(By.CLASS_NAME, 'thesis__link').get_attribute('href')
#{'key':'value','key2','value2'}
data_list.append({
'링크' : link
})
data_list
# 강사님이 작성하신 코드
links = browser.find_elements(By.CLASS_NAME, 'thesis__link')
link_list = []
for i in links:
link = i.get_attribute('href')
link_list.append(link)link_list
2. 수집된 링크의 상세 페이지로 이동
# CLASS_NAME이 thesis__tit임
browser.find_element(By.CLASS_NAME, 'thesis__tit').click()# 내가 원하는 상세 페이지 url
browser.get(url = 'https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE02348298')
3. 논문 제목, 저자, 초록-키워드 수집
#3 논문 제목, 저자, 초록-키워드 수집
containers = browser.find_elements(By.CLASS_NAME, 'dpMain')
data_list = [] # 데이터 저장공간
for i in containers:
title = i.find_element(By.CLASS_NAME, 'thesisDetail__tit').text
humen = i.find_element(By.CLASS_NAME, 'authorList').text
keyword = i.find_element(By.CLASS_NAME, 'thesisDetail__abstract').text
#{'key':'value','key2','value2'}
data_list.append({
'제목' : title,
'저자' : humen,
'초록-키워드' : keyword
})
data_list
4. 수집한 데이터 저장
df = pd.DataFrame(data_list)
df.to_csv('dbpia_data.csv', encoding='utf-8-sig')
☞ 강사님 풀이
1. 페이지의 링크 데이터만 모두 수집
# 키워드 입력하여 이동하게함
keyword = input('검색하고자 하는 키워드를 입력하세요 : ')
url = f'https://www.dbpia.co.kr/search/topSearch?searchOption=all&query={keyword}'
print(url)
browser.get(url)
# 링크만 수집
links = browser.find_elements(By.CLASS_NAME, 'thesis__link') #.get_attribute('href')
link_list = []
for i in links:
link = i.get_attribute('href')
link_list.append(link)link_list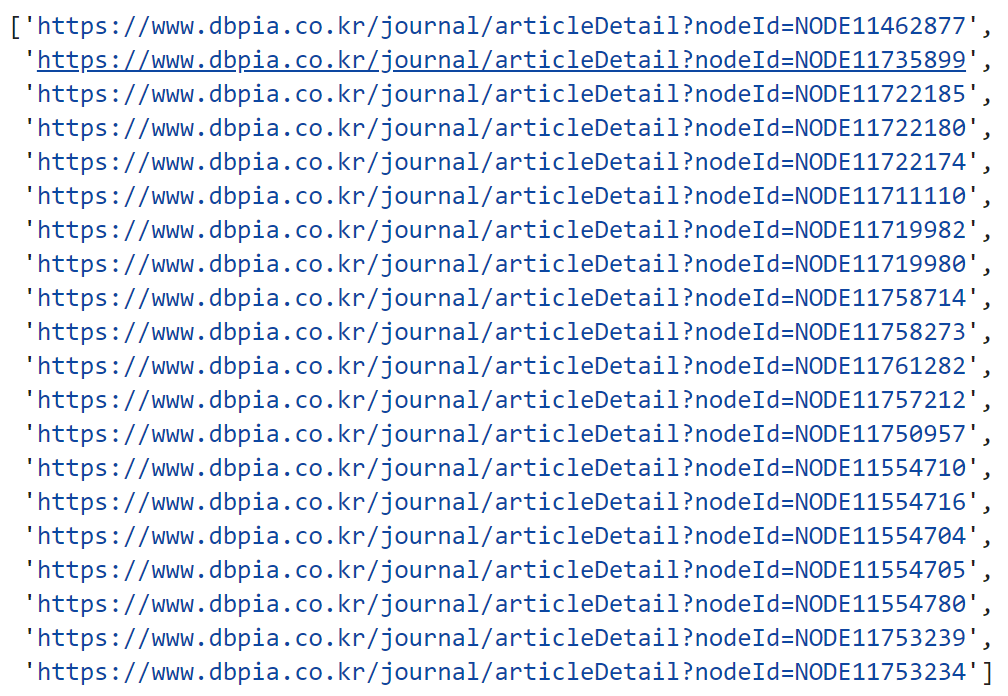
2. 수집된 링크의 상세 페이지(0.3초 간격)로 이동 / 3. 논문 제목, 저자, 초록-키워드 수집
import time
data_list = []
for link in link_list:
browser.get(link)
time.sleep(0.3)
title = browser.find_element(By.CLASS_NAME, 'thesisDetail__tit').text
authors = browser.find_element(By.CLASS_NAME, 'authorList').text
#except을 사용하여 예외처리
try:
abstract = browser.find_element(By.CLASS_NAME, 'abstractTxt').text # No such element exception
except:
abstract = ''
data_list.append({
'논문 제목': title,
'논문 저자': authors,
'초록-키워드': abstract
})data_list
4. 수집한 데이터 저장
df = pd.DataFrame(data_list)
df
☞ SRT 예매하기
☞ 비회원 예매
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()# 비회원으로 들어간 예매창 url
url = 'https://etk.srail.kr/hpg/hra/01/selectScheduleList.do?pageId=TK0101010000'
browser.get(url)# 도착지 변경
browser.find_element(By.ID,'arvRsStnCdNm').clear()# 도착역 입력창에 대전을 입력
browser.find_element(By.ID,'arvRsStnCdNm').send_keys('대전')# 조회하기 버튼 클릭
browser.find_element(By.XPATH,'//*[@id="search_top_tag"]/input').click()# 수서-대전, 18:30시간 매진일때 새로고침 조건문 만들기
import time
for i in range(30):
print(f'{i}번째 시도')
arrive_btn = browser.find_element(By.XPATH,'//*[@id="result-form"]/fieldset/div[6]/table/tbody/tr[3]/td[7]/a')
if arrive_btn.text == '매진':
browser.refresh() #새로고침
time.sleep(1)
else:
arrive_btn.click()
☞ 휴대폰번호로 로그인 / 예매
url = 'https://etk.srail.kr/cmc/01/selectLoginForm.do?pageId=TK0701000000'
browser.get(url)#휴대폰번호 클릭
browser.find_element(By.ID,'srchDvCd3').click()# 휴대번호 입력
browser.find_element(By.ID,'srchDvNm03').send_keys('01012341234')# 비밀번호 입력
browser.find_element(By.ID,'hmpgPwdCphd03').send_keys('password')# 확인 버튼
browser.find_element(By.XPATH,'//*[@id="login-form"]/fieldset/div[1]/div[1]/div[4]/div/div[2]/input').click()# 수서-대전, 18:30
import time
#browser.find_element(By.XPATH,'//*[@id="result-form"]/fieldset/div[6]/table/tbody/tr[3]/td[7]/a').text
for i in range(30):
print(f'{i}번째 시도')
arrive_btn = browser.find_element(By.XPATH,'//*[@id="result-form"]/fieldset/div[6]/table/tbody/tr[3]/td[7]/a')
if arrive_btn.text == '매진':
browser.refresh() #새로고침
time.sleep(1)
else:
arrive_btn.click()
☞ 구글 플레이스토어 데이터 크롤링
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()app_name = input('리뷰를 수집하고자 하는 앱 이름을 입력하시오 : ')
url = f'https://play.google.com/store/search?q={app_name}&c=apps&hl=ko&gl=US'
url
# 주소를 한번 찍어서 봐보는게 좋은 방법이다.app_url = browser.find_element(By.CLASS_NAME,'Qfxief').get_attribute('href')
app_url# 상세페이지 링크 이동
browser.get(app_url)# 리뷰 전체 보기 아이콘 클릭
browser.find_element(By.XPATH,'//*[@id=""]/c-wiz[2]/div/div/div[1]/div/div[2]/div/div[1]/div[1]/c-wiz[4]/section/header/div/div[2]/button').click()# 데이터 수집
# - 닉네임, 평점, 작성일, 리뷰 내용, 몇명이 이 리뷰가 유용하다고 하는지 숫자# 자바스크립트 코드를 이용하여 스크롤하기
modal = browser.find_element(By.CLASS_NAME,'fysCi')
js_code = 'arguments[0].scrollTo(0, arguments[0].scrollHeight);'
import time
for i in range(3):
browser.execute_script(js_code, modal)
time.sleep(3)# 데이터 수집
# - 닉네임, 평점, 작성일, 리뷰 내용, 몇명이 이 리뷰가 유용하다고 하는지 숫자
containers = browser.find_elements(By.CLASS_NAME, 'RHo1pe')
data_list = []
for elem in containers:
username = elem.find_element(By.CLASS_NAME, 'X5PpBb').text
rating = elem.find_element(By.CLASS_NAME, 'iXRFPc').get_attribute('aria-label')[10]
write_date = elem.find_element(By.CLASS_NAME, 'bp9Aid').text
content = elem.find_element(By.CLASS_NAME, 'h3YV2d').text
like = elem.find_element(By.CLASS_NAME, 'AJTPZc').text.split()[1][:-2]
data_list.append({
'유저네임':username,
'평점':rating,
'작성일':write_date,
'내용':content,
'좋아요':like
})
data_list
→ 좋아요가 없는 경우 스크롤을 하면 에러가 뜰 수 있음/ 예외처리
# 좋아요가 없는 경우때문에 예외처리
containers = browser.find_elements(By.CLASS_NAME, 'RHo1pe')
data_list = []
ㄴㄴ
for elem in containers:
username = elem.find_element(By.CLASS_NAME, 'X5PpBb').text
rating = elem.find_element(By.CLASS_NAME, 'iXRFPc').get_attribute('aria-label')[10]
write_date = elem.find_element(By.CLASS_NAME, 'bp9Aid').text
content = elem.find_element(By.CLASS_NAME, 'h3YV2d').text
try:
like = elem.find_element(By.CLASS_NAME, 'AJTPZc').text.split()[1][:-2]
except:
like = '0'
data_list.append({
'유저네임':username,
'평점':rating,
'작성일':write_date,
'내용':content,
'좋아요':like
})
data_listimport pandas as pd
df = pd.DataFrame(data_list)
df
df.info()
☞ 구글 플레이스토어 데이터 슬랙으로 보내기
① slack 새로운 워크스페이스 만들기(로그인필요)
Slack
nav.top { position: relative; } #page_contents > h1 { width: 920px; margin-right: auto; margin-left: auto; } h2, .align_margin { padding-left: 50px; } .card { width: 920px; margin: 0 auto; .card { width: 880px; } } .linux_col { display: none; } .platform_i
slack.com
② 슬랙봇 생성 및 설정
Slack API: Applications | Slack
Slack API: Applications | Slack
Your Apps Don't see an app you're looking for? Sign in to another workspace.
api.slack.com

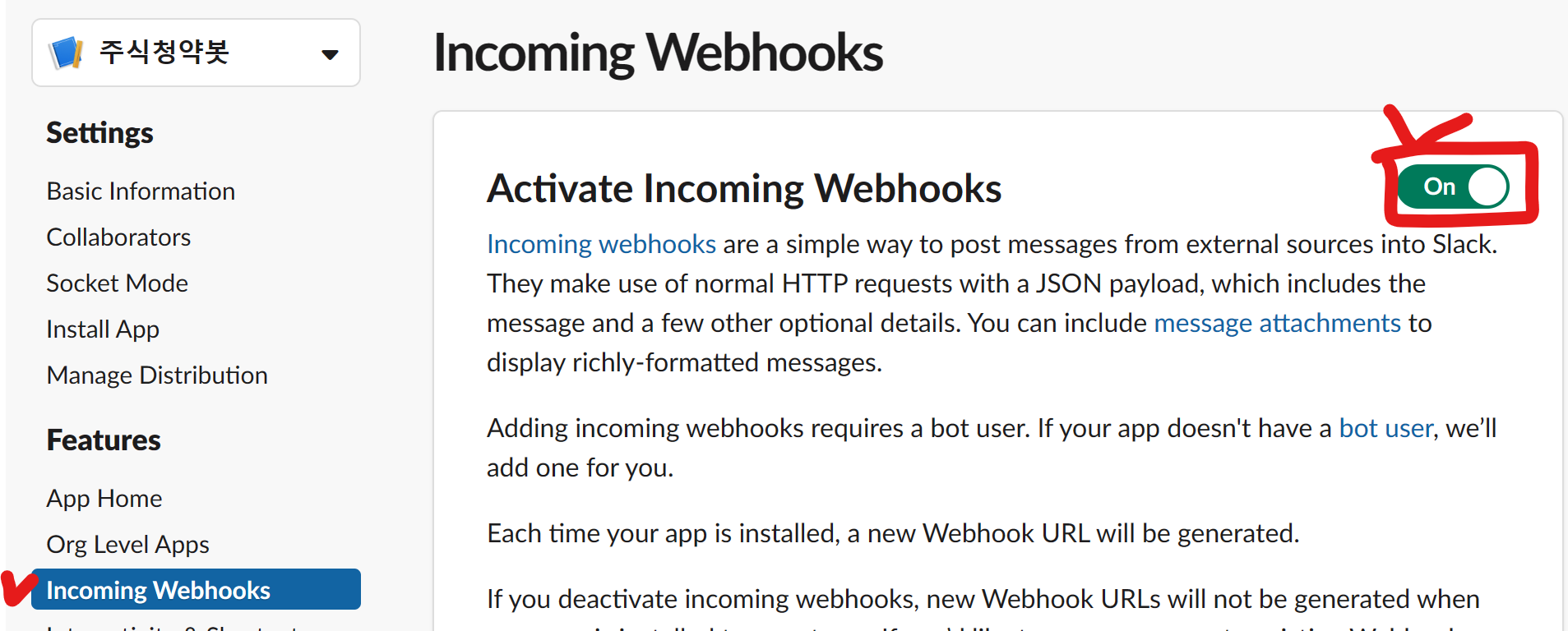
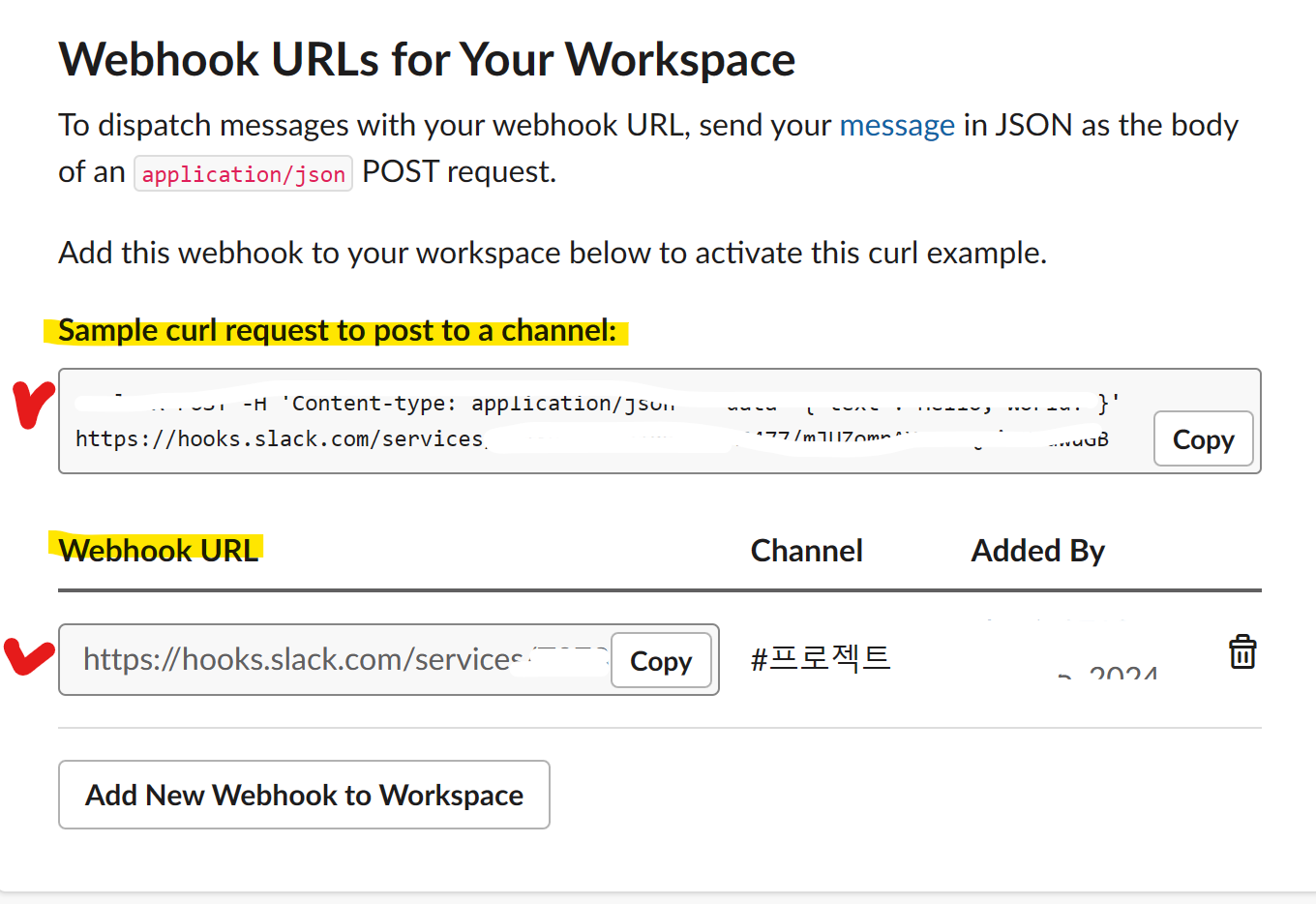
→ Add new Webhook to worksqace로 추가해 주기
→ Sample surl request to post to a channel에 작성된 것을 복사하여 cmd창에 입력
# Slack API로 메세지 보내기
import requests #url 요청
import json #dict -> json
# method : get, post, put, delete
msg = 'gg'
slack_url ='https://hooks.slack.com/services/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'
payload = {
'text':msg
}
response = requests.post(
slack_url,
data=json.dumps(payload),
headers={'Content-type': 'application/json'}
)
print(response)
☞ 표 데이터 수집
# 표 데이터 수집
import pandas as pd
url = 'https://finance.naver.com/'
df = pd.read_html(url, encoding='euc-kr')[0]
df
1. Numpy
■ Numpy
- 수학적 연산을 쉽게 할 수 있도록 도와주는 라이브러리
☞ 라이브러리 설치
!pip install numpyimport numpy as np
# 1차원 배열과 2차원 배열
array1 = np.array([1,2,3])
type(array1) # 1차원 배열
array2 = np.array([[1,2,3], [4,5,6]])
type(array2) # 2차원 배열
array2.shape # 2,3 => 2행 3열
array2.ndim # 2차원
array1.ndim # 1차원
array1
array2.dtype # dtype: data type# arr[2]는 3번째를 뜻한다
arr = np.array([1, 2, 3.3])
arr.dtype
arr[2]arr = np.arange(10) # range()
arr[0:5]
# boolean indexing : True되어있는 index 값만 표현
arr[arr > 5] # [6,7,8,9]
arr[arr < 3] # [0, 1, 2]
☞ 값을 list에 저장
arr = np.array([100, 30, 50, 80, 10])
# sorted 사용하여 내림차순
arr_sorted = np.sort(arr)[::-1] # pandas
arr_sorted
2. Pandas
■ Series
☞ 라이브러리
!pip install pandas
import pandas as pd
#series
# 1개의 컬럼으로 구성된 1차원 데이터셋
data = ['A','B','C','D','E']
se = pd.Series(data)
type(se)
se
# 1개의 컬럼으로 구성된 1차원 데이터셋
data = ['A', 'B', 'C', 'D', 'E']
se = pd.Series(data)
type(se)
print(se)
se.index
se.values
se[0:3] # 0<= se <3
se.name = 'alphabet'
se.index.name = "No."
print(se)
■ DataFrame
☞ DataFrame 만들기
data = {
'country': ['kor', 'usa', 'china', 'japan'],
'rank': [1,2,3,4],
'grade': ['A', 'B', 'C', 'D']
}
data # key:컬럼명, value:컬럼값
df = pd.DataFrame(data)
df.set_index(['rank', 'country']) # multi-index
df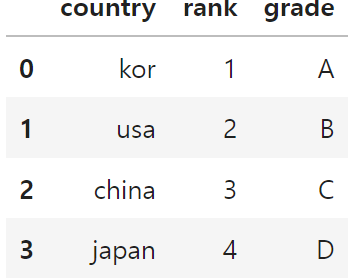
☞ CRUD(Create, Read, Update, Delete)
① Read
- df.컬럼명
- df['컬럼']
test_cols1 = ['country', 'rank']
test_cols2 = ['country', 'grade']
df[test_cols1]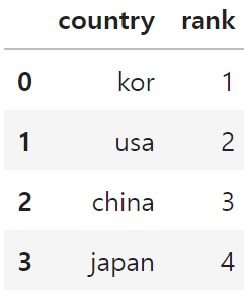
# df.loc[인덱스값, 컬럼명]
df.loc[0, ['country', 'rank']]
# df.loc[인덱스값, 컬럼명]
df.loc[0:3, ['country', 'rank']]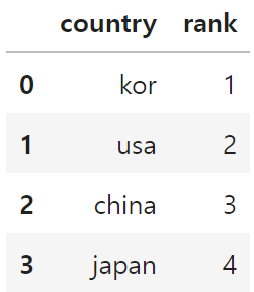
# 전체컬럼 가져오기
df.loc[:, ['country', 'rank']]# 전체컬럼 가져오기
df.loc[0:3, ['country', 'rank']]
df.loc[df['rank'] >= 2, ['country', 'grade']]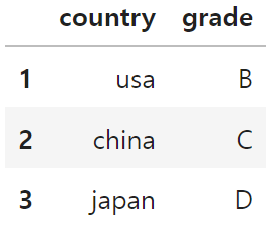
# df.iloc[인덱스값, 컬럼인덱스] : 위치(location) 기반
df.iloc[:, [0,1,2]]
df.iloc[0:2, [0,2]]
df.loc[:2, ['country','grade']]df.loc[0:2, ['country','grade']]
② Create
- 행 또는 열 데이터를 추가
- df['컬럼명'] = 컬럼 데이터
president = pd.Series(['yoon', 'biden', 'jinping', 'kishida'])
df['president'] = president# gdp컬럼, 컬럼값 추가
df['gdp'] = [1000, 2000, 3000, 4000]
df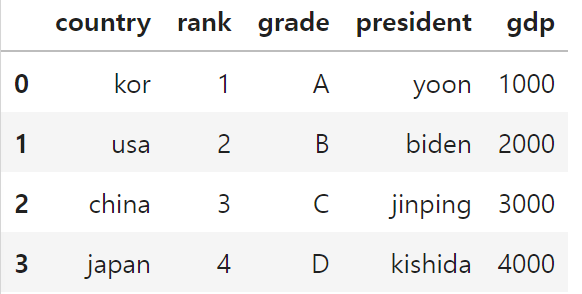
# 파생컬럼/ gdp값이 3000 이상
df['new_gdp'] = df['gdp'] >= 3000
df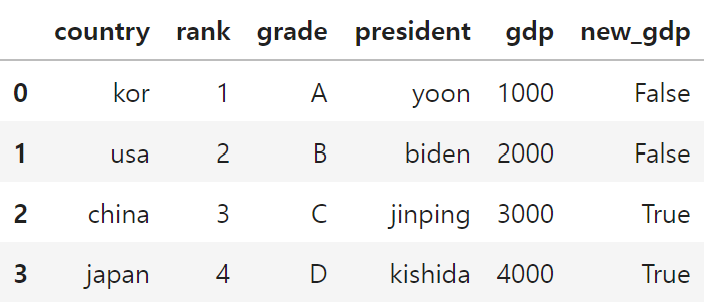
# 행 데이터 추가
df.loc[4] = ['singapore', 2, 'B', 'Tharman', 3500, True]
df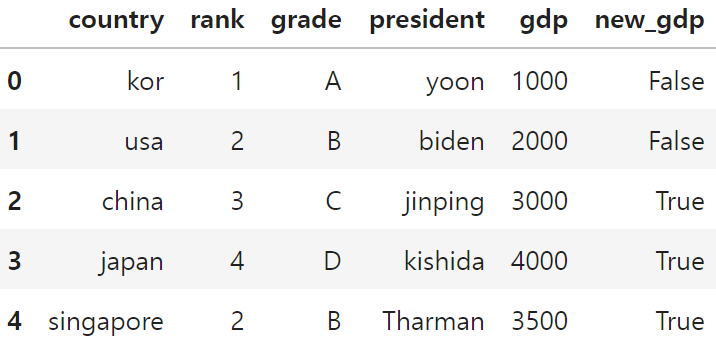
③ Delete → drop
df_drop_gdp = df.drop('rank', axis=1)
df_drop_gdp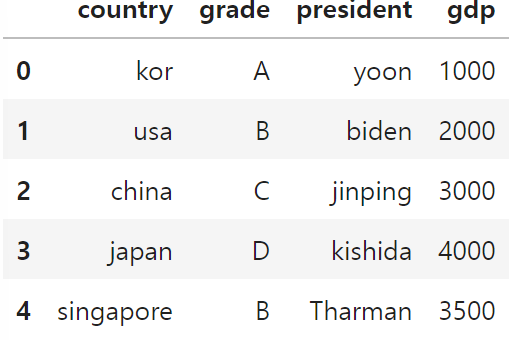
# index를 기준으로 제거하기
df.drop(4, axis=0)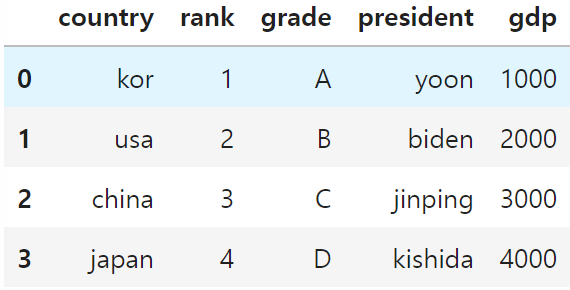
▶indo의 gdp를 None으로 변경
df.loc[3, 'gdp'] = None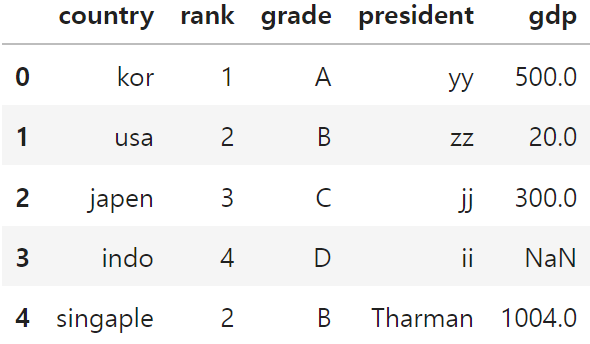
④ Update
# 3번째 gdp값을 None으로 변경
df.loc[2, 'gdp'] = None
df
# axis: 축- 0:인덱스 기준, 1:컬럼명 기준
df.drop([0,1])
# 집합함수(aggregation): 기술통계 데이터
df.sum() #총합계
df.mean(numeric_only=True) #평균값
df.max() #최대값
df.min() #최소값
df.describe()
df.info()
# 정렬하기
df.sort_values(by=['rank', 'president'], ascending=[False, True])
☞ NaN 데이터 처리
df.dropna(how='all')
# gdp에 NaN값 1개
df.isna().sum()
df.dropna()
# gdp 평균
gdp_mean = df['gdp'].mean()
df.fillna(value=gdp_mean)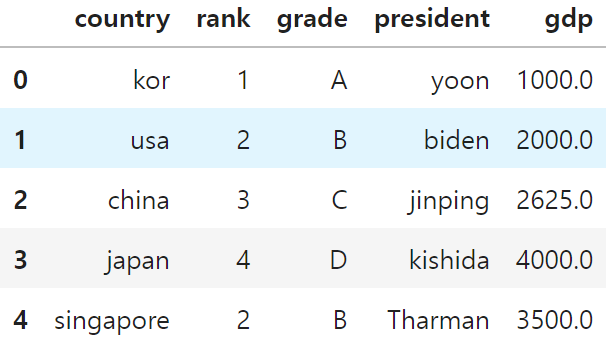
☞ 연습문제
import pandas as pd
data = {
'영화' : ['명량', '극한직업', '신과함께-죄와 벌', '국제시장', '괴물', '도둑들', '7번방의 선물', '암살'],
'개봉 연도' : [2014, 2019, 2017, 2014, 2006, 2012, 2013, 2015],
'관객 수' : [1761, 1626, 1441, 1426, 1301, 1298, 1281, 1270], # (단위 : 만 명)
'평점' : [8.88, 9.20, 8.73, 9.16, 8.62, 7.64, 8.83, 9.10]
}
df = pd.DataFrame(data)
df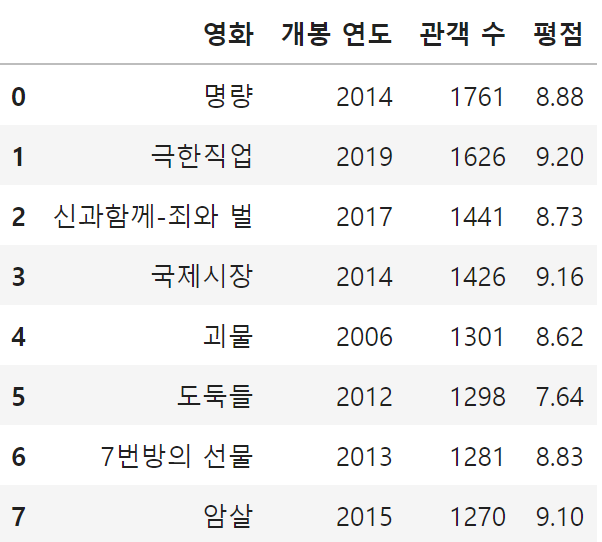
☞ 1~5 문제
1) 전체 데이터 중에서 '영화' 정보만 출력하시오.
2) 전체 데이터 중에서 '영화','평점' 정보를 출력하시오.
3) 2015년 이후에 개봉한 영화 데이터 중에서 '영화','개봉연도' 정보를 출력하시오.
- (0) 개봉 연도
- (1) 2015년 이후에 개봉한 영화
- (2) 추출한 데이터에서 컬럼값이 '영화', '개봉연도' 인 데이터를 출력한다.
4) 주어진 계산식을 참고하여 '추천 점수' Column을 추가하시오.
- 추천 점수 = (관객수 * 평점) // 100
5) 전체 데이터를 '개봉연도' 기준 내림차순으로 출력하시오.
#1) 전체 데이터 중에서 '영화' 정보만 출력하시오.
df.loc[0:, ['영화']]
# 2) 전체 데이터 중에서 '영화','평점' 정보를 출력하시오.
df.loc[0:, ['영화','평점']]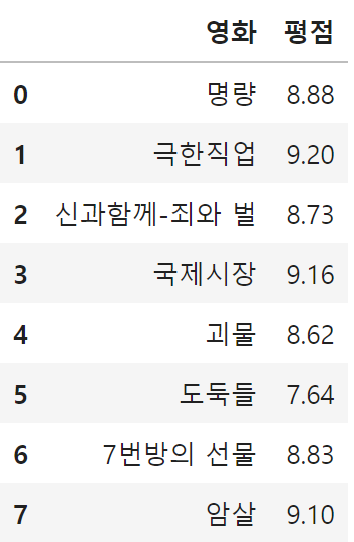
# 3) 2015년 이후에 개봉한 영화 데이터 중에서 '영화','개봉연도' 정보를 출력하시오.
# - (0) 개봉 연도
# - (1) 2015년 이후에 개봉한 영화
# - (2) 추출한 데이터에서 컬럼값이 '영화', '개봉연도' 인 데이터를 출력한다.
df[df['개봉 연도'] > 2015][['영화','개봉 연도']]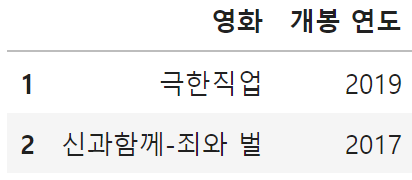
# 4) 주어진 계산식을 참고하여 '추천 점수' Column을 추가하시오.
# - 추천 점수 = (관객수 * 평점) // 100
df['추천 점수'] = df['관객 수'] * df['평점']//100
# 5) 전체 데이터를 '개봉연도' 기준 내림차순으로 출력하시오.
df.sort_values(by='추천 점수', ascending=False)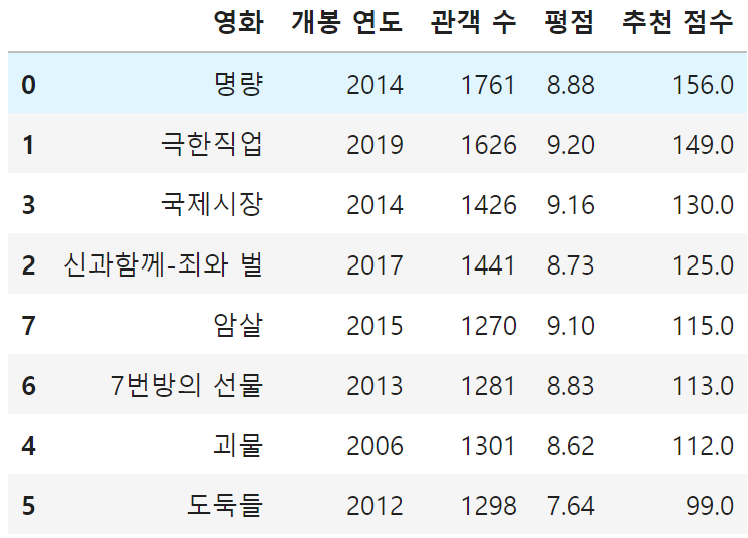
'데이터분석 부트캠프' 카테고리의 다른 글
| Python 프로젝트 (0) | 2024.06.05 |
|---|---|
| 데이터분석 부프캠프 14기 - 5주차 (0) | 2024.05.24 |
| 데이터분석 부프캠프 14기 - 3주차 (0) | 2024.05.08 |
| Python 주피터 설치 방법 & 가상환경 설정 (0) | 2024.05.03 |
| 커리어 성장 컨퍼런스_데이터분석 전문 데프콘 강의 후기 (1) | 2024.04.30 |


