◆ 목차
- Python
- 데이터 분석
- 크롤링
☞ Python 수업이 드디어 3주째에 시작했습니다!!!
첫 수업의 시작은 Python을 잘 모르는 분들이 많을거라 생각하시고 설명을 해주셨는데 듣고 보니 "아.. 열심히 들어야겠다 이 수업 아파도 빠지면 안될 것 같다!!!ㅠㅠ"라고 생각을 들게 해주는 시간이었습니다.
1. Python
■ Python을 사용하는 이유?
☞ 객체지향 프로그래밍을 지원하고, 이런 일들이 가능하다고 합니다.
① 업무자동화 : 엑셀(openpyxl, API), 파워포인트(경영 직군)
② 크롤링(Crawling) + 인터넷을 통한 자동화
③ 서비스 구현 : 백엔드, 서버
④ 데이터분석 : pandas
- R, Python
⑤ 머신러닝
→ 게임 개발, 웹 or 앱 개발은 불가능
■ 가우시안 프로세스
■ Colab으로 문법 실습
Python 문법
1. 자료형
■ 숫자형 (Number)
# 1. 숫자형 (Number)
## (1) int(정수형)
a = 1
b = 2
# 사칙연산이 가능
a + b
a - b
a * b
a / b
# 제일 마지막 결과만 출력
# 출력하고 싶은것이 있으면 print 함수 사용하면 가능
type(a+b) #int
# 다른 연산
x = 3
y = 5
print(x ** y) # x를 y번 곱한 값
print(x // y) # x를 y번 나눈 몫
print(x // y) # x를 y번 나눈 몫
■ 문자형 (String)
## (2) 실수형(float)
a = 0.3 # 부동소수점
b = 3
print(a*b)
type(a*b)
round(a*b, 2)
word = 'The best things\nin life are free' # \n = 새로운 line
print(word)
word2 = "The best things in life are free"
# 문장 안에서의 작은 따음표는 문자열로 인식하게 만들어줌 \사용하면 인식
word2 = 'It\'s kind of fun to do the impossible'
word2 = '''It's kind of fun to do the impossible '''
print(word2)
☞ 연습문제
# "Failure is simply the opportunity to begin again." he says."
# 3가지 방법으로 표현
#(1) """
#(2) ''
#(3) \
(1) """
""" "Failure is simply the opportunity to begin again." he says." """
#(2) ''
'"Failure is simply the opportunity to begin again." he says."'
#(3) \
"\"Failure is simply the opportunity to begin again.\" he says.\""
#len 사용
a = 'L'
b = 'i'
c = 'f'
d = 'e'
(a+b+c+d) * 10
len(a+b+c+d) # len : 문자열의 길이# 문자열 indexing & slicing
a = 'Hello Python!'
# indexing : 하나의 문자열을 포지션, 인덱스 값을 통해 가져오는 방
a[4]
a[-1]
# slicing : 문자열 쪼개기
a[0:4] # 0 <= a < 4 라는 뜻
a[6:-1] # 'Python'
# slicing 예제
a = '10kg상자'
data = a[0:2]
weight = a[2:4]
unit = a[4:]
# 각각 파생컬럼을 만들어 주는것(전처리)
data, weight, unit # ('10', 'kg', '상자')
☞ 연습문제
# Q. "TitanicJames" 변수를 영화제목(title)과 감독(director)으로 슬라이싱 해보세요.
a = "TitanicJames" # ex) 공공데이터 API
titie = "Titanic"
director = "James"
#풀이
title = a[:7]
director = a[7:]
print(title, director) # Titanic James
a[:] # TitanicJames
# 문자열 포맷팅(formatting)
# 문자열을 출력하는 방법 : print()
#(1) format
name = 'nanamu'
age = 15
intro = "반가워 나는 {}이고 나이는 {}야".format(name, age)
intro # 반가워 나는 nanamu이고 나이는 15야
# f-string
name = 'nanamu'
age = 15
city = 'seoul'
intro = f"반가워 나는 {name}이고 나이는 {age}야 사는곳은 {city}이야."
intro # 반가워 나는 nanamu이고 나이는 15야 사는곳은 seoul이야.
# coding convention : 코드 규칙(기업마다 다름)# 문자열 함수
#(1) strip()
a = ' python '
type(a)
a.strip() # 앞뒤 공백 제거
# (2) join()
words = ['하이', '반가워', '잘가']
result = "-".join(words)
result # 하이-반가워-잘가
#3 split()
result. split("-") # ['하이', '반가워', '잘가']
sample = '10kg-20kg-30kg'
# split 함수를 사용해서 숫자형 데이터만 분리하시오
res = sample.split('-')
res # ['10kg', '20kg', '30kg']
■ 리스트형 (List)
# 3. 리스트형(List)
# [1, 2, 3] 대괄호 [ ] 사이에 변수들이 담겨있는 형태
x = ['a', 'b', 'c', ['d', 'e']]
type(x) # list
# indexing & slicing
# indexing 한다함
x[-1] # ['d', 'e']
# 이걸 slicing 이라고 함
x[0:3] # ['a', 'b', 'c']
# divide and conquer : 분할/ 정복
new_x = x[3]
# new_x = ['d', 'e']
new_x[1] # e
# 데이터분석 -> pandas (행 또는 컬럼을 추가하고 싶어.)
# append() : 리스트 데이터에 값을 추가
fruits = ['포도', '오렌지', '메론']
fruits.append('딸기')
fruits # ['포도', '오렌지', '메론', '딸기']
# pop() : 리스트에서 아이템을 제거
# fruits에서 인덱스 값이 2인 데이터를 리턴. remove
remove_fruit = fruits.pop(2)
remove_fruit # 메론
fruits # ['포도', '오렌지', '딸기']# sort() : 값을 정렬
numbers = [100, 30, 1000, 300, 10000]
numbers.sort(reverse=True) # ascending: 오름차순, reverse=True 내림차순
numbers # [10000, 1000, 300, 100, 30]
■ 튜플형(Tuple), 딕셔너리형(Dict), 집합형(Set)
# 튜플형 (Tuple)
# - ( ), 소괄호로 둘러싸여져 있다.
# - ML(머신러닝)
# 튜플의 특징
# - 튜플은 한번 생성되면 변경이 불가능합니다.
# - 변경이 불가능: 처음 만들어진 튜플 요소에 추가, 삭제, 변경할 수 없습니다.
# - 이러한 불변성이 리스트와의 가장 큰 차이점.
a = (1,2,3)
type(a) # tuple
a = [1,2,3]
a[0] = 100
a # [100, 2, 3]
t = (1,2,3)
# t[0] = 100 # 값을 수정 => TypeError: does not support
#t.append(4) # 값을 추가 => has no attribute
# 원본 데이터는 유지하고, 새로운 컬럼은 추가
new_t = t + (4,)
new_t # (1, 2, 3, 4)
# API_KEY 또는 중요한 변수들 또는 변하지 않는 변수(상수변수)
# 딕셔너리형(Dict) -> JSON(공공데이터 API) - 프로토콜
# - 중괄호로 감싸져있고 { }, {key:value} 형태 구성
# EX)스마트홈
# - 스마트 조명: 휴대폰으로 불 끄기 -> 불이 꺼지잖아요. 원리
# - 내 휴대폰과 조명이 소통(프로토콜)을 한 거잖아요?
x = {'name':'nanamu', 'age': [15, 20], 'city':{'born':'jinju', 'live':'seoul'}}
x # {'name': 'nanamu', 'age': [15, 20], 'city': {'born': 'jinju', 'live': 'seoul'}}
x['age']
type(x) # dict
# x['ages'] # 오류 발생
x.get('ages', 0)
try:
x['ages']
except:
print("오류 발생")
x['ages'] = 0
x['ages']
# 오류 발생
# 0
list(x.keys()) # ['name', 'age', 'city', 'ages']
x.values() # dict_values(['nanamu', [15, 20], {'born': 'jinju', 'live': 'seoul'}, 0])# 집합형 (set)
# - 데이터의 중복을 허용하지 않음.
# - 순서를 보장하지 않음.
x = set([9,9,9,9,9,2,2,2,2,3,3,3,3,4,4,5,5,5])
x # {2, 3, 4, 5, 9}
■ 불형 (Boolean)
# 불형 (Boolean)
# - True , False
type(False)
type(1 <= 100) # 참
# bool
2. 제어문
☞ 들여 쓰기, 스페이스바 4번 or 탭 키 한번 클릭하여 사용
■ 제어문
- if
if 조건문:
실행할 코드(if 조건문이 참일 때)
elif 조건문:
실행할 코드(if 조건문이 참일 때)
else
실행할 코드(모든 if, elif 조건문이 거짓일 때)
# pass : 조건문을 수행하지 않고 넘기기
if 조건문:
실행할 코드(if 조건문이 참일 때)
pass
else
실행할 코드(모든 if, elif 조건문이 거짓일 때)
☞ 예시문
if(조건문)
- 만약에
- (조건문)이 참이면 => 실행하고,
- (조건문)이 거짓이면 => 다음 조건으로 넘어감
# input -> user로부터 값을 입력받고자 할 때 사용한다.
number = input('숫자를 입력하세요 : ') # '123' -> 123
number = int(number)
if number < 5:
print("숫자가 5보다 작습니다.")
elif number < 10:
print('숫자가 10보다 작습니다.')
else: # 모든 조건이 만족하지 않을 경우에만 실행
print("숫자가 10보다 큽니다.")
a = 1
b = 3
# 비교연산자 (값을 비교)
a == b # False
a != b # True
a < b # True
a <= b # 작거나 같다.
a > b # False
a >= b # False# 예제1
# 서울에서 부산을 간다고 가정하에 나의 주머니에 있는
# 돈(money)에 따른 조건문
# if => 7만원 있으면 비행기를 타고 (money==70000)
# elif => 5만원 있으면 기차를 타고
# elif => 3만원 있으면 버스를 타고
# else => 걸어간다.
money = int(input("당신은 얼마를 가지고 있나요?"))
if money >= 70000:
print("와우! 당신은 비행기를 탈 수 있습니다!")
elif money >= 50000:
print("그래도 당신은 ktx를 탈 수 있습니다!")
elif money >= 30000:
print("그래도 당신은 버스를 탈 수 있습니다..")
else:
print("걸어가기")# 예제2
# or -> 전체 조건문 중 하나라도 조건을 만족하면 True
# and -> 전체 조건문이 참이어야 True 그 외의 경우 False
try:
money = int(input("당신은 얼마를 가지고 있나요?"))
except:
if money == 'card': # show me the money...
money = 100000
card = True
if (money >= 70000) or (card == True):
print("와우! 당신은 비행기를 탈 수 있습니다!")
elif money >= 50000:
print("그래도 당신은 ktx를 탈 수 있습니다.")
elif money >= 30000:
print("그래도 당신은 버스를 탈 수 있습니다.")
else:
print("걸어가기")# 예제3
if (money >= 70000) and (card == True):
print ("비행기 탄다!")
elif money >= 50000:
print ("기차로 가야해요")
elif money >= 30000:
print ("안타까워요. 버스입니다.")
else:
print ("같이 가자!")
■ 반복문
- for
for 변수 in 리스트(또는 튜플, 문자열):
실행할 문장1for i in range(2, 11, 2):
print("Hello, World!", i)
range(10) # 0 <= x < 10
# range(0, 10)
☞ 예제
# 예제1
cities = ['seoul', 'jeju', 'jinju', 'busan']
for city in cities:
print(f'도시 이름 : {city}')
if city == 'jeju':
print('우도를 들어가요.')
elif city == 'busan':
print('해운대에 가세요.')
# 예제2
for i in range(len('python')): # len을 사용하여 python을 숫자형으로 변환
print(i)
print("반복문이 종료되었습니다.")
※ for문 문제
1. 1부터 1000까지 자연수의 합을 구해보세오.
sum = 0
i = 0
for i in range(1, 1001):
sum += i
print(sum) # 500500sum = 0
i = 0
while i < 1000:
i += 1
sum += i
print(sum) # 5005002. 1부터 1000까지 5의 배수의 합을 구해보세요.
◆ 내가 풀기
sum = 0
i = 0
for i in range(1, 1001):
if i % 5 == 0:
sum += i
print(sum) # 100500
◆ 강사님 풀이
sum = 0
i = 0
while i <1000:
i += 1
if i % 5 != 0:
continue
sum += i
print(sum) # 100500
3. 커피 자판기에 재고가 5잔이 있고, 커피 한 잔의 가격은 300원입니다. 돈을 입력받고, 커피 재고가 다 떨어질 때까지 주문을 반복하는 코드를 작성하세요. 다음과 같이 출력되어야 합니다.
< 아래 표현을 코드로 표현>
입력된 돈이 300원일 경우:
'커피를 줍니다.'
'남은 커피의 양은 00잔입니다.'
입력된 돈이 300원보다 클 경우:
'거스름돈 00원을 주고 커피를 줍니다.'
'남은 커피의 양은 00잔입니다.'
입력된 돈이 300원보다 작을 경우:
'커피의 가격은 300원입니다. 돈을 다시 돌려주고 커피를 주지 않습니다.'
'남은 커피의 양은 00잔입니다.'
커피가 다 떨어진 경우:
'커피가 다 떨어졌습니다. 판매를 중지합니다'
◆ 내가 풀기
total = 5
a = 0
while True:
u_input = int(input("받은 돈을 입력해주세요. : "))
if u_input == 300:
print('커피를 줍니다.')
total -= 1
print(f'남은 커피의 양은 {total}잔입니다.')
if total == 0:
break
elif u_input > 300:
total -= 1
a = u_input - 300
print(f'거스름돈 {a}원을 주고 커피를 줍니다.')
print(f'남은 커피의 양은 {total}잔입니다.')
if total == 0:
break
elif u_input < 300:
print(f'커피의 가격은 300원입니다. 돈을 다시 돌려주고 커피를 주지 않습니다.')
print(f'남은 커피의 양은 {total}잔입니다.')
else:
print(f'커피가 다 떨어졌습니다. 판매를 중지합니다.')
◆ 강사님 풀이
coffee = 5
while True:
money = int(input("돈을 넣어주세요."))
if money == 300:
print('커피를 줍니다.')
coffee -= 1
print(f'남은 커피의 양은 {coffee}잔입니다.')
elif money >= 300 :
print(f'거스름돈 {money-300}원을 주고 커피를 줍니다.')
coffee -= 1
print(f'남은 커피의 양은 {coffee}잔입니다.')
else:
print('커피의 가격은 300원입니다. 돈을 다시 돌려주고 커피를 주지 않습니다.')
print(f'남은 커피의 양은 {coffee}잔입니다.')
if coffee == 0:
print('커피가 다 떨어졌습니다. 판매를 중지합나다.')
break☞ 풀이를 보니깐 마지막 빠져나가는 부분이 실행되면서 자동으로 끝나게끔 하는 걸 인지하고 내가 풀어본 것과 비교하면서 보니 어느 부분이 잘못된 건지 알 수 있어서 좋았습니다.
- while
# 조건문이 참(True)인 경우에 문장이 반복되서 실행
whlie 조건문:
실행할 문장
# break : 조건문 강제종료
whlie 조건문:
실행할 문장
break
# continue 해당 루프가 끝나고 다음 루프로 이동
#Ex
whlie a < 5:
a += 1
if a % 2 == 0: # a의 값을 2로 나머지가 0일때
continue
print(a)
☞ 예제
# 예제3
# 반복문 (while)
a = 0
while a < 5: # 무한루프
# a = a + 1
a += 1
print(a) # 1, 2, 3 .. 5
☞ for문, while문 연습문제
1부터 5까지 더하는 프로그램을 만들어 보시오.
(1) for, (2) while
단, 결과값은 sum 변수에 담으시오.
# (1)for
sum = 0
for i in range(1, 6):
sum = sum+i
#sum = sum+i
print(sum)(2) while
sum = 0
a = 0
while a < 5:
a = a +1
sum = sum + a
print(sum)
☞ 총 문제 풀기
※ 총 문제
문제 1. 1부터 10까지의 정수 중에서 짝수만 출력하는 코드를 작성하세요.
for i in range(1, 11):
if i % 2 == 0:
print(i)
문제 2. 사용자로부터 입력받은 숫자가 양수인지 음수인지 출력하는 코드를 작성하세요.
u_input = int(input("숫자를 입력해주세요 : "))
#u_input = int(number)
if u_input > 0:
print("양수")
elif u_input < 0:
print("음수")

문제 3. 1부터 100까지의 정수 중에서 3의 배수이면서 5의 배수인 정수의 합을 구하는 코드를 작성하세요.
sum = 0
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
sum = sum+i
sum
# 315
문제 4. 사용자로부터 n개의 정수를 입력받아, 이 중에서 가장 큰 값과 가장 작은 값을 구하는 코드를 작성하세요.
num = int(input("정수를 입력하세요."))
u_input_list = []
for i in range(num):
u_input = int(input(f'{i+1}번째 숫자'))
u_input_list.append(u_input)
u_input_list
# (1) 정렬을 한다. sort() => x[0], x[-1]
# (2) List -> min, max() 활용한다.
# (3) List 값을 반복문을 돌리면서 값을 확인한다.
min_val = u_input_list[0] # 30
max_val = u_input_list[0] # 30
for i in u_input_list:
if i < min_val:
min_val = i
# 최대값 : 50
# 최소값 : 30
if i > max_val:
max_val = i
print(f'최대값 : {max_val}')
print(f'최소값 : {min_val}')
문제 5. 사용자로부터 입력받은 숫자의 구구단을 출력하는 코드를 작성하세요.
u_input = int(input("구구단을 외우자, 몇단을 구하고 싶은지 입력하세요."))
sum = 0
i = 0
for i in range(1, 10):
if i == u_input:
for a in range(1, 10):
print(i*a)
# 좀더 이쁘게 출력을 원한다면
u_input = int(input("구구단을 외우자, 몇단을 구하고 싶은지 입력하세요."))
sum = 0
i = 0
for i in range(1, 10):
if i == u_input:
for a in range(1, 10):
print(f'{i} * {a} = {i*a}')
☞ 연습문제를 풀었는데 생각보다 "어? 어쩌지.. 생각이 안 나... 어떤 식으로 풀어야 할까?"라는 생각이 들면서 수업 때 필기했던 부분을 한번 더 찾아보고 이런식으로 해야 할지 고민도하고 이것저것 써보면서 시간을 보냈습니다. 비록 처음하는거라 서툴고 시간이 오래 걸렸지만 많은 연습 문제와 복습을 통해 자신 있게 풀 수 있도록 노력해야겠어요!
■ List, Dict Comprehension
- 리스트 안에 for문을 포함하여 한 줄로 편하게 코드를 작성할 수 있게 하는 문법
- ex) 표현신 for 항목 in 반복가능객체 if 조건문
# 예시
ls = []
for i in range(1, 5): # 1~4까지 ls에 담기
ls.append(i)
print(ls)
# list comprehension
ls = [i for i in range(1,5)]
print(ls)# 예시2
names = ['Merry','John','Chris']
num = [1,2,3]
dic = {names[i]:num[i] for i in range(len(names))}
print(dic) #{'Merry': 1, 'John': 2, 'Chris': 3}
# dict comprehension
dic1 = {}
for i in range(len(names)):
dic1[names[i]] = num[i]
dic1 # {'Merry': 1, 'John': 2, 'Chris': 3}
3. 함수
■ 함수(def : define, definition 정의하다)
- 입력값을 받아서 명령을 수행하고 결과값을 반환
- 반복적으로 생성되는 코드들을 재활용하여 사용하고 싶을 때 사용, 호출을 할 때만 실행이 되는 일련의 코드 블록을 의미
def 함수명(변수1, 변수2,....):
수행문1
수행문2
...
return 결과값 #결과값이 없는 경우 생략 가능
def 함수명(매개변수):
실행할 문장
-> input이 들어가면 output이 나온다# 입력값에 2를 곱해주는 함수
def twice(i):
return i*2
a = 2
b = 3
print(twice(a))
print(twice(b))
# input: X, output: X
def my_name():
print(f'제 이름은 {name} 입니다.')
word = my_name()
print(word) # 에러
# input: O, output: X
def my_name(name):
print(f'제 이름은 {name}입니다.') # 변수를 받아서 처리해야하고
# 문자열로 들어가야한다
my_name('홍길동') #함수를 호출할 때는 함수이름() 괄호가 반드시 들어가야 한다.
print(word)# input: O, output: O
def my_name(name):
print(f'제 이름은 {name}입니다.') # 문장을 출력하는
return f'너의 이름은 {name}' # 값을 변수로 전달
word = my_name('홍길동')
print(word)
def sum(a, b):
result = a + b
return result
result = my_sum (1,2)
print(result)
# 출력값
# 3
# Noneresult = int('123') # 문자열 숫자 데이터를 넣으면 정수형 데이터 타입으로 변경해주는 함수
result
■ 변수의 범위
x = 1
def twice(x):
x = x * 2
return x
print(twice(x)) # retrun되어 x에 2가 들어간거지만
print(x) # 실제 x값이 변경된것은 아님
■ lambda로 간결하게 함수 만들어보기
lambda 변수1, 변수2,....:결과값
■ 클래스(class)
4. 예외처리
■ 예외처리
- 오류를 처리하는 방법
try: #try문을 실행
...
except 발생오류 as 오류변수: #만약 에러가 나면 수행문을 실행
...# try_ except : 예외처리 구문
try:
word = int(input('숫자를 입력해주세요: '))
except: # 예외처리
word = 0
if word < 100:
print("100보다 작습니다.")try:
num = int(input('숫자를 입력 : '))
result = 100 / num
print(f'결과값: {result}')
except ValueError:
# int() 변환에 실패한 경우 발생
print("숫자가 아닙니다. 문제가 아닌 숫자를 입력하세요.")
except ZeroDivisionError:
# 숫자를 0으로 나누려고 한 경우 발생
print("0이 아닌 다른 숫자를 입력하세요.")
except Exception as e:
# 위의 두 오류 경우가 아닌 경우
print(f'오류 문구 : {e}')
finally:
print('계산이 끝났습니다. ')
5. 라이브러리
■ 라이브러리란?
- 다른 사람들이 만들어 둔 유용한 함수들의 모음
- 표준 라이브러리 : 파이썬을 설치할 때 자동으로 설치됨
- 외부 라이브러리 : 기본으로 설치된 라이브러리가 아니므로 새로 설치
import 라이브러리명 # 라이브러리 불러오기
!pip install 라이브러리명 # 외부 라이브러리 다운
■ 살펴볼 라이브러리
- random
- datetime
- math
- numpy
- Counter
■ random 함수
- random() : 0 ~ 1 사이의 실수형의 수를 반환
- randint(시작, 끝) : 특정 범위 안의 랜덤한 정수를 반환
- random.choice(리스트) : 리스트 중에 랜덤하게 요소를 뽑기
- random.sample(리스트, 개수) : 리스트 중 입력한 개수만큼 랜덤하게 요소를 뽑기
- random.shuffle(리스트) : 리스트를 랜덤하게 섞기
▶ 랜덤으로 random 함수 안에 0~1까지 숫자 중 실수 하나를 뽑기
import random
random.random() # 랜덤으로 random 함수안에 0~1까지 숫자중 실수 하나를 뽑기
▶ 1~1000까지 숫자 중 랜덤으로 뽑기
random randint(1, 1000) # 1~1000까지 숫자중 랜덤으로 뽑기
▶ 리스테서 1가지 요소를 랜덤하게 뽑기
a = [i for i in range(5)]
random.choice(a) # 리스트에서 1가지 요소를 랜덤하게 뽑기
▶리스트에서 지정한 개수만큼 뽑아서 리스트로 반환
random.sample(a, 2)
▶리스트를 마음대로 섞어서 정렬을 해주기
random.shuffle(a)
print(a)
데이터분석
1. 데이터 전처리
■ datetime 클래스
- 날짜와 시간을 정함
■ timedelta 클래스
- 시간 구간을 정하며 날짜 연산을 할 때 사용
■ datetime 함수
- now() : 현재 시각을 반환
- year, month, day, hour, minute, second, microsecond : 날짜, 시간 값을 반환
- date() : 연월일로 이루어진 날짜 객체를 반환
- time() : 시간 객체를 반환
- strftime('날짜형식') : 날짜와 시간 정보를 문자열로 변환
- strptime(문자열, 날짜형식) : 문자열을 날짜로 변환
▶ 현재 시각
# 라이브러리 불러오기
from datetime import datetime
from pytz import timezone
from datetime import timedelta
print(datetime.now()) # 현재시간
print(datetime.now(timezone('UTC')))
print(datetime.now(timezone('Asia/Seoul')))

▶ 여러 날짜, 시각
x = datetime.now(timezone('Asia/Seoul'))
print(x)
print(x.year, x.month, x.day, x.hour, x.minute, x.second, x.microsecond)
print(x.date(), x.time())
print(x.weekday()) # {0:월, 1:화, 2:수, 3:목, 4:금, 5:토, 6:일}
▶ 날짜와 시각 정보를 문자열로 반환
x.strftime('%Y-%m-%d')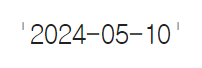
▶문자를 데이터 타입 객체로 변환
datetime.strptime('2023-05-01', '%Y-%m-%d')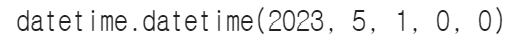
■ math 함수
- math.pi : 원주율
- math.e : 자연상수
- abs() : 절대값(내장함수)
- round() : 반올림(내장함수)
- math.ceil() : 올림
- math.floor() : 내림
- math.factorial() : 팩토리얼
- math.pow() : 제곱 연산
- math.sqrt() : 제곱근 연산
■ numpy
- 벡터 / 행렬 연산을 도와주는 라이브러리
import numpy as np
▶ 0~999까지 중에 리스트를 가지고 온 것 중에 100개를 가져와서 랜덤 샘플을 이용해 뽑기
ls = random.sample([i for i in range(1000)], 100)print(np.mean(ls))
print(np.var(ls))
print(np.std(ls))
print(np.sum(ls))
■ Counter
▶ 리스트에 요소가 몇 개인지 알아보고 딕셔너리 형식으로 변환
from collections import Counter
ls = ['a','a','b','b','b','c','d','d','d','d']
Counter(ls)
■ Pandas
- 쉽고 직관적으로 작업할 수 있도록 설계, 빠르고 유연한 데이터 구조를 제공하는 Python 패키지
- 시리즈(Series)와 데이터프레임(DataFrame)이라는 구조화된 데이터 형식을 제공
import 라이브러리명 as 부를 이름
# 패키지 설치
!pip install pandas
■ Pandas 주요 기능
- 데이터의 빠른 정렬, 슬라이싱, 인덱싱
- 데이터 그룹핑, 피봇팅
- 데이터 간의 join
- 데이터 요약, 통계
- 파이썬 자료구조(리스트, 튜플, 딕셔너리)와의 호환
- 외부 데이터(csv, 엑셀, SQL DB, txt)를 다루기 용이
■ 데이터 내용 확인
.columns : 컬럼명 확인
.head() : 데이터의 상단 5개 행 출력
.tail() : 데이터의 하단 5개 행 출력
- 괄호() 안에 숫자를 넣으면 그 숫자만큼 행을 출력
.shape : (행,열) 크기 확인
.info : 데이터에 대한 전반적인 정보 제공
.type() : 데이터 타입 확인■ 컬럼명 확인
print(titanic.columns)
■ 상단 5개 행 출력
titanic.head()
■ 하단 5개 행 출
titanic.tail()
■ 행과 열의 크기 확인
titanic.shape
■ 데이터에 대한 정보 확인
titanic.info()
■ 데이터 타입 확인
type(titanic)
■ 데이터 필터링
불리언(Boolean) 인덱싱 : True값을 가진 행만 추출
.isin() : 각각의 요소가 데이터 프레임 또는 시리즈에 존재하는지 파악하여 True/False 값 반환
불리언 인덱싱 _ .isin() : 데이터의 특정 범위만 추출
.isna() : 결측 값은 True 반환, 그 외는 False 반환
.notna() : 결측 값은 False 반환, 그외는 True 반환Ex) 불리언(Boolean) 인덱싱 : 조건이 True 행만 추출
1. 35살 초과인 데이터 추출
# 나이가 35 초과 조건
print(passenger["Age"] > 35)
2. 35살 초과인 데이터 추출하여 불리언 인덱싱 해주기
# passenger에 나이가 35 초과 조건에 해당되는 True값을 저장해서 above35 넣기
above35 = passenger[passenger["Age"] > 35]
above35.head()
◆ Series
- 데이터가 순차적으로 나열된 1차원 배열의 형태
- index와 value가 일대일 대응 관계
▶ 딕셔너리로 시리즈 만들기
dic = {'a':1,'b':2,'c':3} # a,b,c를 키로 받고 1,2,3을 값으로 받는 딕셔너리 만들고
dic_series = pd.Series(dic) # pd.Series에 넣기dic_series
▶ 리스트로 시리즈 만들기
- 딕셔너리의 키처럼 인덱스로 변환될 값이 없음.
- 인덱스를 별도 지정하지 않으면 디폴트로 정수형 위치 인덱스가 지정
ls = [1,2,3] # 리스트 만들고
ls_series = pd.Series(ls, index=['a','b','c']) #인덱스 이름을 설정ls_series
▶ 시리즈의 값(values), 인덱스(index), 값의 타입(dtypes) 확인하기
print(dic_series.values, end='\n\n')
print(dic_series.index, end='\n\n')
print(dic_series.dtypes, end='\n\n\n')
print(ls_series.values, end='\n\n')
print(ls_series.index, end='\n\n')
print(ls_series.dtypes)
■ Dataframe
- Series를 이어 붙여 표 형태로 만들면 Dataframe이 된다.
- 데이터 프레임은 행과 열로 만들어지는 2차원 배열의 형태
- 데이터 프레임의 열은 각각의 시리즈 객
▶ 표를 pandas dataframe으로 만들기
| Name | Number | Month |
| John | 1 | Feb |
| Merry | 2 | Oct |
| Chris | 3 | Nov |
import pandas as pd
dic = {'Name':['John','Merry','Chris']
, 'Number':[1,2,3]
, 'Month':['Feb','Oct','Nov']}
df = pd.DataFrame(dic)
df| Name | Number | Month | |
| 0 | John | 1 | Feb |
| 1 | Merry | 2 | Oct |
| 2 | Chris | 3 | Nov |
▶ 리스트로 데이터프레임 만들기
ls = [['John', 1, 'Feb']
,['Merry',2,'Oct']
,['Chris',3,'Nov']]
df = pd.DataFrame(ls, columns=['Name','Number','Month'])
df| Name | Number | Month | |
| 0 | John | 1 | Feb |
| 1 | Merry | 2 | Oct |
| 2 | Chris | 3 | Nov |
▶ 시리를 결합해 데이터프레임 만들기
name_series = pd.Series(['John','Merry','Chris'])
number_series = pd.Series([1,2,3])
month_series = pd.Series(['Feb','Oct','Nov'])
df = pd.DataFrame({'Name':name_series, 'Number':number_series, 'Month':month_series})
df| Name | Number | Month | |
| 0 | John | 1 | Feb |
| 1 | Merry | 2 | Oct |
| 2 | Chris | 3 | Nov |
▶ 데이터프레임의 값(values), 인덱스(index), 값의 타입(dtypes), 컬럼(columns) 확인하기
print(df.values, end='\n\n')
print(df.index, end='\n\n')
print(df.dtypes, end='\n\n')
print(df.columns)
■ 데이터프레임 요약정보 확인
- info() : 전체 행의 갯수, 컬럼 정보, 결측치, 데이터 타입을 보여줌
- describe() : 컬럼별 값의 갯수, 평균, 표준편차, 최솟값, 최댓값, 사분위수를 보여
◆ 데이터 불러오기, 저장하기
| File Format | Reader | Writer |
| CSV | read_csv | to_csv |
| Excel | read_excel | to_excel |
| JSON | read_json | to_json |
| SQL | read_sql | to_sql |
| HTML | read_html | to_html |
■ csv 파일
# 불러오기
데이터변수 = pd.read_csv(파일경로)
# 저장하기
데이터변수.to_csv(파일경로)import pandas as pd
☞ csv 파일 불러오고 저장해 보기
■ 실제 예제파일 불러오기
from google.colab import drive
drive.mount('/content/drive') # 드라이브 연결file_path = '/content/drive/MyDrive/Python/Part2) 파이썬을 이용한 데이터 분석/Part2) 파이썬을 이용한 데이터 분석/data/titanic_train.csv'
data = pd.read_csv(file_path)
data
■ 실제 예제 파일 저장하기
csv_file_path1 = '/content/drive/MyDrive/Python/Part2) 파이썬을 이용한 데이터 분석/Part2) 파이썬을 이용한 데이터 분석/data/csv_test1.csv'
csv_data1.to_csv(csv_file_path1)
■ index_col : 인덱스로 사용할 컬럼
csv_data1 = pd.read_csv(csv_file_path, index_col = 0) # 첫번째 컬럼을 인덱스로 사용
csv_data1.head()
■ usecols : 사용할 컬럼
# PassengerId 인덱스로 사용하고, (PassengerId, Survived, Pclass, Age) 컬럼만 사용
csv_data1 = pd.read_csv(csv_file_path, index_col = 'PassengerId', usecols = ['PassengerId','Survived','Pclass','Age'])
csv_data1.head()
■ 엑셀 파일
# 불러오기
데이터변수 = pd.read_excel(파일경로, sheet_name = 시트이름)
# 저장하기
데이터변수 = to_excel(파일경로, sheet_name = 시트이름)
☞ 엑셀 파일 불러오고 저장해 보기
■ 실제 예제파일 불러오기
excel_file_path = '/content/drive/MyDrive/Python/Part2) 파이썬을 이용한 데이터 분석/Part2) 파이썬을 이용한 데이터 분석/data/titanic_train.xlsx'
excel_data = pd.read_excel(excel_file_path, sheet_name='시트1')
■ 실제 예제파일 저장하기
excel_file_path1 = '/content/drive/MyDrive/강의자료_황수현_Python/Part2) 파이썬을 이용한 데이터 분석/data/excel_test.xlsx'
excel_data1.to_excel(excel_file_path1, sheet_name = 'sheet1')
■ header : 컬럼 이름으로 사용할 행
excel_data = pd.read_excel(excel_file_path, sheet_name='시트1', header=1)
excel_data.head()
■ index_col : 인덱스로 사용할 컬럼, usecols : 사용할 컬럼
excel_data1 = pd.read_excel(excel_file_path, sheet_name='시트1', header=1, index_col = 'PassengerId', usecols = ['PassengerId','Survived','Pclass','Age'])
excel_data1.head()
■ 웹 html 파일
- pd.read_html(html경로)
- encoding : 한글이 깨져서 나올 때 utf-8/cp949로 설정
■ 웹 html 파일 불러오기
html_path = 'https://finance.naver.com/sise/sise_quant.naver' # 네이버 증권관련 페이지
quant_data_list = pd.read_html(html_path)
■ 웹 html 파일 한글 깨짐
# 가져온 html 결과보기
quant_data_listquant_data_list = pd.read_html(html_path, encoding='cp949') # 깨진 한글 encoding 해주기
quant_data_listkospi = quant_data_list[1]
kospikospi.dropna(how='all').reset_index(drop=True)
◆ 조건에 맞는 데이터 추출
■ 행 조회
- 한 개 : 데이터프레임명[인덱스:인덱스+1]
- 여러 개 : 데이터프레임명[시작인덱스:끝인덱스+1]
# 1~9개까지 불러오기
df[:10]
■ 열 조회
- 한 개 : 데이터프레임명[컬럼명]
- 여러 개 : 데이터프레임명[[컬럼명1, 컬럼명2,.....,컬럼명n]]
# 한개 열
df['Survived']# 여러 열
df[['Survived','Pclass','Name']]# 데이터프레임 형식
df['Survived'].to_frame()
or
df[['Survived']]
■ .loc[ ]
- loc : 레이블값을 사용하여 조회/ 행 이름과 열 이름을 사용
- 데이터프레임명.loc[행 이름,열 이름]
- 열만 조회할 때는 행 조건에 : 를 입력
# 3인덱스를 가진 열
df.loc[3,]
■ .iloc[ ]
- iloc : 위치인덱스를 사용하여 조회/ 행 번호와 열 번호를 사용
- 데이터프레임명.iloc[행 번호, 열 번]
df1.iloc[3,]
df.iloc[[1,3,5],]
◆ 원하는 조건으로 데이터 추출하기
■ 데이터 정렬
- 데이터프레임명.sort_values(정렬기준컬럼)
- ascending=False : 내림차순으로 정렬
# Age 컬럼을 기준으로 정렬
df.sort_values('Age')Age 컬럼을 기준으로 ascending을 사용하여 내림차순 정렬
df.sort_values('Age', ascending=False)
◆ 특정 조건으로 데이터 추출하기
- 데이터프레임명[조건식]
- 데이터프레임명.query('조건식')
# Pclass 컬럼 데이터가 1인 것만
df[df['Pclass'] == 1]
or
#조건식에는 꼭 문자열로 해야함
df.query('Pclass == 1')# isin을 사용하여 필요한 데이터만 조회
df[df['PassengerId'].isin([3,100,500])]
◆ 인덱스, 행, 열
■ 인덱스
- 데이터프레임 행들의 이름
df.index
■ 인덱스 변경
- 인덱스 n개 변경 : 데이터명.rename({인덱스:바꿀 인덱스, 인덱스:바꿀 인덱스,....})
- 인덱스 전체를 변경 : 데이터명. index = 바꿀 인덱스 리스트
※표
| passenger Id | Survived | |
| 0 | 1 | 0 |
| 1 | 2 | 1 |
| 2 | 3 | 1 |
■ 인덱스 2개 변경
df1 = df.copy()
df1.rename({0:'row1', 1:'row2'})| passenger Id | Survived | |
| row1 | 1 | 0 |
| row2 | 2 | 1 |
| 2 | 3 | 1 |
■ 인덱스 전체 변경
df1.index = [i+1 for i in range(len(df1))]
df1.head()| passenger Id | Survived | |
| 1 | 1 | 0 |
| 2 | 2 | 1 |
| 3 | 3 | 1 |
→ 1열의 데이터값이 row1, row2, 2였지만 1, 2, 3으로 변경된 것을 볼 수 있음
■ 열을 인덱스로 설정
- 데이터명.set_index(컬럼명)
# PassengerId을 인덱스로 설정
df1.set_index('PassengerId')
■ 인덱스를 열로 변환
- 인덱스를 열로 변환하고 그 열을 남기기 : 데이터명.reset_index()
- 인덱스를 열로 변환하고 그 열을 삭제 : 데이터명.reset_index(drop = True)
| passenger Id | Survived |
| 1 | 0 |
| 2 | 1 |
# PassengerId 인덱스를 열로 변환
df1.reset_index()| passenger Id | Survived | |
| 0 | 1 | 0 |
| 1 | 2 | 1 |
# index였던 열을 삭제
df1.reset_index(drop=True)| Survived | |
| 0 | 0 |
| 1 | 1 |
■ 행 추가 / 제거
- 행 추가 : pd.concat([기존 데이터명, 붙일 데이터명]) / DataFrame.loc['새로운 행 이름'] = 데이터 값
- 행 제거 : 데이터명.drop(인덱스명, axis=0)
# df1과 df2를 리스트로 만들어 df3으로 합치기
df3 = pd.concat([df1, df2])
df3
■ 행 중복 제거
- 데이터명.drop_duplicates()
# df3 데이터의 중복 제거
df3.drop_duplicates()
■ 열 추가 / 제거
- 열 추가 : 데이터명[추가할 컬럼명] = 추가할 값 / DataFrame 객체['추가하려는 열 이름'] = 데이터 값
- 열 제거 : 데이터명.drop(제거할 컬명, axis=1)
# age_simplified 컬럼명과 df1['Age']//10 * 10의 결과값을 추가
df1['age_simplified'] = df1['Age']//10 * 10# given_name 컬럼 삭제
df1.drop('given_name', axis=1)
■ 열 이름 변경
- 열 이름 변경 : 데이터명.rename({열이름:바꿀이름1, 열이름:바꿀이름2,...}, axis=1)
- 열 이름 전체 변경 : 데이터명.columns = 열 이름 리스트
열이름 PassengerId를 Id로 바꾸기
df1.rename({'PassengerId':'Id'}, axis=1)
■ 데이터 통계
.mean() : 평균값
.median() : 중앙값
.describe() : 다양한 통계량 요약
.agg() : 여러개의 열에 다양한 함수를 적용
- group객체.agg([함수1, 함수2, 함수3,...]) : 모든 열에 여러 함수를 매핑
- group객체.agg({'열':함수1, '열2':함수2,...}) : 각 열마다 다른 함수를 매핑
.groupby() : 그룹별 집계
.value_counts() : 값의 개수
◆ 결측값 처리
■ 결측값 확인
- isna() : 결측값을 True로 반환
- notna() : 결측값을 False로 반환
# 결측값인 경우 True, 아니면 False 값으로 확인
df.isna()
■ 결측값 제거
- 데이터명.dropna(axis=0, how='any', subset='None')
- axis : {0 : index / 1 : columns}
- how : {'any' : 존재하면 제거 / 'all' : 모두 결측치면 제거}
- subset : 행 / 열의 이름을 지정
① 결측치가 있는 컬럼 삭제
df.dropna(axis=1)
② 결측치가 존재하면 행 삭제
df.dropna(how='any')
③ 특정열에 결측치가 있는 행 삭제
df.dropna(subset=['Cabin','Age'])
④ 결측 값이 들어있는 행 전체 삭제
titanic.dropna(axis=0)
⑤ 결측 값이 들어있는 열 전체 삭제
titanic.dropna(axis=1)
■ 결측값 대치
- 데이터 전체의 결측값을 특정 값으로 변경 : 데이터명.fillna(대치할 값)
- 특정 컬럼의 결측값을 특정 값으로 변경 : 데이터명[컬럼명].fillna(대치할 값)
- 결측값을 바로 위의 값과 동일하게 변경 : 데이터명.fillna(method='ffill')
- 결측값을 바로 아래의 값과 동일하게 변경 : 데이터명.fillna(method='bfill')
① 결측치를 모두 -1로 변경
df.fillna(-1).tail()
② 특정 컬럼(Age) 결측치 값을 -1로 변경
df1['Age'] = df1['Age'].fillna(-1)
③ 위에 결측치 값으로 변경
df.fillna(method='ffill').tail()
④ 아래 결측치 값으로 변경
df.fillna(method='bfill').tail()
◆ 타입 변환
■ 타입 확인
- .dtypes : 열의 타입을 시리즈로 반환
■ 특정 타입을 가진 컬럼만 추출
- 데이터명.select_dtypes(타입)
# int에 해당되는 정수만 조회
df.select_dtypes('int')# 문자열에 해당되는 것만 조회
df.select_dtypes('object')
■ 타입 변환
- 데이터명[컬럼명].astype(타입)
◆ 날짜 다루기
■ 문자형을 날짜형으로 변경
- 날짜가 문자형으로 되어있다면, 날짜형으로 변경 처리 → 날짜 계산이 가능
- pd.to_datetime(컬럼, format='날짜 형식')
| 형식 | 설명 |
| %Y | 0을 채운 4자리 연도 |
| %y | 0을 채운 2자리 연도 |
| %m | 0을 채운 월 |
| %d | 0을 채운 일 |
| %H | 0을 채운 시간 |
| %M | 0을 채운 분 |
| %s | 0을 채운 초 |
# format에 변경할 형식 넣기
pd.to_datetime(df['Date'], format='%Y-%m-%d')
■ 날짜를 원하는 형식으로 변경
- 데이터컬럼.dt.strftime(날짜형식)
# %Y-%m형식으로 변경
df['Date1'].dt.strftime('%Y-%m')
■ dt 연산자
| 연산자 | 설명 |
| year | 연도 |
| month | 월 |
| day | 일 |
| dayofweek | 요일(0-월요일, 6-일요일) |
| day_name() | 요일을 문자열로 |
■ 날짜 계산
- day 연산 : pd.Timedelta(day = 숫자)
- month 연산 : DateOffset(months = 숫자)
- year 연산 : DateOffset(years = 숫자)
# 예시
# Date1 데이터에 day값 1을 더해서 조회
df['plus day1'] = df['Date1'] + pd.Timedelta(days=1)
df.head()
■ 날짜 구간 데이터 만들기
- pd.date_range(start=시작일자, end=종료일자, periods=기간수, freq=주기)
| 형식 | 설명 |
| D | 일별 |
| W | 주별 |
| M | 월별 말일 |
| MS | 월별 시작일 |
| A | 연도별 말일 |
| AS | 연도별 시작일 |
# 예시
pd.date_range(start='2020-01-01', periods=30, freq='D')
# 2020-01-01을 시작으로 30일 기간을 일별로 나타내기
■ 기간 이동 계산(이동평균선에 자주 사용)
- 컬럼.rolling().집계함수
■ 행 이동
- 컬럼.shift(이동할 행의 수)
◆ 고급기능 다루기
■ apply 함수
- 사용자 저의 함수를 데이터에 적용하고 싶을 때 사용
- .apply(함수, axis=0/1)
예시1
def pclass_sibsp(x):
if x['Pclass'] == 1 and x['SibSp'] == 1: # x의 Pcalss값이 1이고 SibSp값이 1인 경우
return 1
else:
return 0# pclass_sibsp_filter열에 pclass_sibsp값을 확인
df1['pclass_sibsp_filter'] = df1.apply(pclass_sibsp, axis=1) #axis : 열이름을 참조했기 때문 1
예시2
# x값의 따라 NaN, 0, 1 값으로 반환
import numpy as np
def adult(x):
if x >= 19:
return 1
elif x < 19:
return 0
else:
return np.nanAge열의 값을 adult 조건의 따라 새로운 열 adult_yn에 입력
df1['adult_yn'] = df1['Age'].apply(adult)
df1.head(10)
☞ 간단하게 lambda로 가능
df1['pclass_sibsp_lambda'] = df1.apply(lambda x: 1 if x['Pclass'] == 1 and x['SibSp'] == 1 else 0, axis=1)
df1.head()
■ map 함수
- 값을 특정 값으로 치환하고 싶을 때 사용
- 데이터명[컬럼명].map(매핑 딕셔너리)
# 예시
gender_map = {'male':'남자', 'female':'여자'}
df1['Sex_kr'] = df1['Sex'].map(gender_map)
df1.head()
■ 문자열 다루기
| 메소드 | 설명 |
| .str.contains(문자열) | 문자열을 포함하고 있는지 유무 |
| .str.replace(기존문자열, 대치문자열) | 문자열 대치 |
| .str.split(문자열, expand=True/False, n=개수) | 특정 문자열을 기준으로 쪼개기 |
| .str.lower() | 소문자로 바꾸기 |
| .str.upper() | 대문자로 바꾸기 |
☞ .str.contains(문자열) 예시
# 예시
df2['Name'].str.contains('Mrs') # Name에 Mrs 포함하는지# 예시
# 특정 문자열을 포함한 데이터 추출
df2[df2['Name'].str.contains('Mrs')]
☞ .str.replace(기존문자열, 대치문자열) 예시
Name에서 ,를 공백으로 변환
df2['Name'] = df2['Name'].str.replace(',', '')
df2.head()
☞ .str.split(문자열, expand=True/False, n=개수) 예시
# n이 1개라서 열을 한개더 추가
df2['Name'].str.split(' ', expand=True, n=1)
◆ 데이터 결
■ 문자열 다루기
- pd.merge(데이터1, 데이터2, on=기준컬럼, how=결합방법)
- lnner join : 데이터 A, B에서 겹쳐지는 부분만
- Full outer join : A, B에서 모두
- left outer join : A을 기준으로 A + A와 B의 합쳐진 부분
- right outer join : B을 기준으로 B + A와 B의 합쳐진 부분

# 예시문
pd.merge(customer, orders, on='id', how='inner')
■ 두 데이터의 기준 컬럼명이 다를 경우
- pd.merge(데이터1, 데이터2, left_on=데이터1의 기준커럼, right_on=데이터2의 기준컬럼, how=결합방법)
# 예시
pd.merge(customer, orders, left_on='id', right_on='customer_id', how='inner')
◆ 분포와 통계량
■ 분포 및 요약 통계
- describe() : 컬럼별 값의 갯수, 평균, 표준편차, 최솟값, 최댓값, 사분위수를 보여줌
df.describe()
■ 대푯값
| 메소드 | 설명 |
| min() | 최솟값 |
| max() | 최댓값 |
| mean() | 평균 |
| median() | 중간값 |
| std() | 표준편차 |
| var() | 분산 |
| quantile() | 분위수 |
■ 변수의 상관관계 확인
- 상관관계 분석은 두 변수의 관련성을 구하는 분석
- 두 변수 간의 연관된 정도이지 인과관계를 설명하지 않음
- 상관계수 = 두 변수가 함께 변하는 정도 / 두 변수가 각각 변하는 정도

- .corr()
# 예시
df.corr(numeric_only=True)import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(df.corr(numeric_only=True), annot=True)
plt.show()
◆ 데이터 집계
■ groupby
- 같은 값을 한 그룹으로 묶어서 여러 가지 연산 및 통계를 구할 수 있
- 데이터.groupby(컬럼명).연산및통계함
■ 단일 그룹
| 함수 | 설명 |
| count() | 행의 갯수 |
| nunique() | 행의 유니크한 갯수 |
| sum() | 합 |
| mean() | 평균 |
| min() | 최소값 |
| max() | 최댓값 |
| std() | 표준편 |
| var() | 분산 |
☞ 단일 그룹
# 예시
df.groupby('Pclass').count()
df.groupby('Pclass').nunique()
df.groupby('Pclass').sum(numeric_only=True)
df.groupby('Pclass')[['Survived']].mean() # []안에 컬럼명 넣고 특정열만 가져오기
df.groupby('Pclass')[['Survived','Age']].mean() # 여러 리스트를 가져오려면 []안에 컬럼명 넣기
☞ 다중 그룹
# 예시
df.groupby(['Sex','Pclass']).mean(numeric_only=True) #groupby에 리스트로 열 넣기import numpy as np
df.groupby(['Sex','Pclass'])[['Survived','Age','SibSp','Parch','Fare']].aggregate([np.mean, np.min, np.max])
# 여러 통계값을 계산하려면 aggregate 함수 사용
◆ 데이터 재구조화
■ crosstab
- 범주형 데이터를 비교분석할 때 유용
- pd.crosstab(index=행, columns=열. margins=True/False, normalize=True/False)
■ 범주별 갯수 구하기
- pd.crosstab(행, 열)
■ 범주별 비율 구하기
- normalize = 'all' : 전체 합이 100%
- normalize = 'index' :행별 합이 100%
- normalize = 'columns' : 열 합이 100%
☞ 예시
# Sex, Survived 값의 대한 전체 합
pd.crosstab(df['Sex'], df['Survived'], normalize='all')
# margins를 추가하여 행과 열의 합 구하기
pd.crosstab(df['Sex'], df['Survived'], normalize='all', margins=True)
# 두개의 인덱스에서 Survived 컬럼에 해당하는 값의 행의 개수 구하기
pd.crosstab(index=[df['Sex'], df['Pclass']], columns=df['Survived'])
■ 피벗테이블
- 엑셀의 피벗테이블처럼 인덱스별 컬럼별 값의 연산을 할 수 있음
- pd.pivot_table(데이터명, index=, columns=, values=, aggfunc=)
■ stack
- 컬럼 레벨에서 인덱스 레벨로 데이터프레임을 변경
■ unstack
- 인덱스 레벨에서 컬럼 레벨로 데이터프레임을 변경
■ melt
- pd.melt(데이터명, id_vars=기준 컬럼)
2. 시각화
◆ matplotlib과 seaborn
■ matplotlib
- 파이썬 데이터 시각화의 가장 기본적인 라이브러리
- 장점 : 유연하게 커스텀이 가능
- 단점 : 코드가 길고 어려움
■ seaborn
- matplotlib을 좀 더 쉽고 아름답게 시각화하는 라이브러리
■ seaborn 선형 회귀선 있는 산점도
regplot() : 선형 회귀선이 있는 산점도 시각화
regplot() 함수의 파라미터
- x축 변수
- y축 변수
- 데이터 셋
- axe 객체
- fit_reg : 선영 회귀선 표시 여부
선형 회귀선 : 간단한 선형 데이터 집합에 사용되는 가장 적합한 직선(=추세선)
☞ 기본 문법
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt # 시각화 라이브러리 가져오기
import seaborn as sns
# 기본적 시각화 코드
plt.figure(figsize=(가로길이, 세로길이)) #그래프 크기 설정
sns.000plot(data=데이터, x=X축 컬럼, y=Y축 컬럼, hue=범례 컬럼) #seaborn으로 그래프 그리기
plt.title(제목) #제목 설정
plt.xlabel(라벨) #x축 라벨 설정
plt.ylabel(라벨) #y축 라벨 설정
plt.legend(loc=범례 위치 설정)
plt.xticks(rotation=x축 각도 설정)
plt.yticks(rotation=y축 각도 설정)
plt.show() #그래프 출력
☞ 예시
# 사용할 범례를 넣기
sns.barplot(data=df, x="island", y="body_mass_g", hue="sex")plt.figure(figsize=(10,5))
sns.barplot(data=df, x='species', y='body_mass_g')
plt.title('body mass per species')
plt.xlabel('per species')
plt.ylabel('body mass')
plt.show()
◆ 스타일 설정
■ sns.set_style(스타일)
■ sns.set_palette(팔레트)
- 스타일 : darkgrid, whitegrid, dark, white
☞ 스타일 예시
☞ 어두운 배경 그래프
sns.set_style('darkgrid')
sns.barplot(data=df, x='species', y='body_mass_g')
plt.show()
☞ 하얀 배경 그래프
sns.set_style('whitegrid')
sns.barplot(data=df, x='species', y='body_mass_g')
plt.show()
◆ 한글폰트 설정
① 폰트 설치
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
② 런타임 → 런타임 다시 시작
③ 폰트 적용
plt.rc('font', family='NanumGothic')
◆ 고화질 설정
%config InlineBackend.figure_format = 'retina'
◆ 산점도
■ sns.scatterplot(data=데이터, x=x출 컬럼, y=y축 컬럼, hue=색) - 산점도 기본
■ sns.lmplot(data=데이터, x=x축 컬럼, y=y축 컬럼, hue=색) - 산점도에 회귀선 추가
☞ scatterplot
# style을 사용하여 점 모양을 다르게 표현
sns.scatterplot(data=penguins, x='bill_length_mm', y='bill_depth_mm', style='sex', hue='island')
plt.show()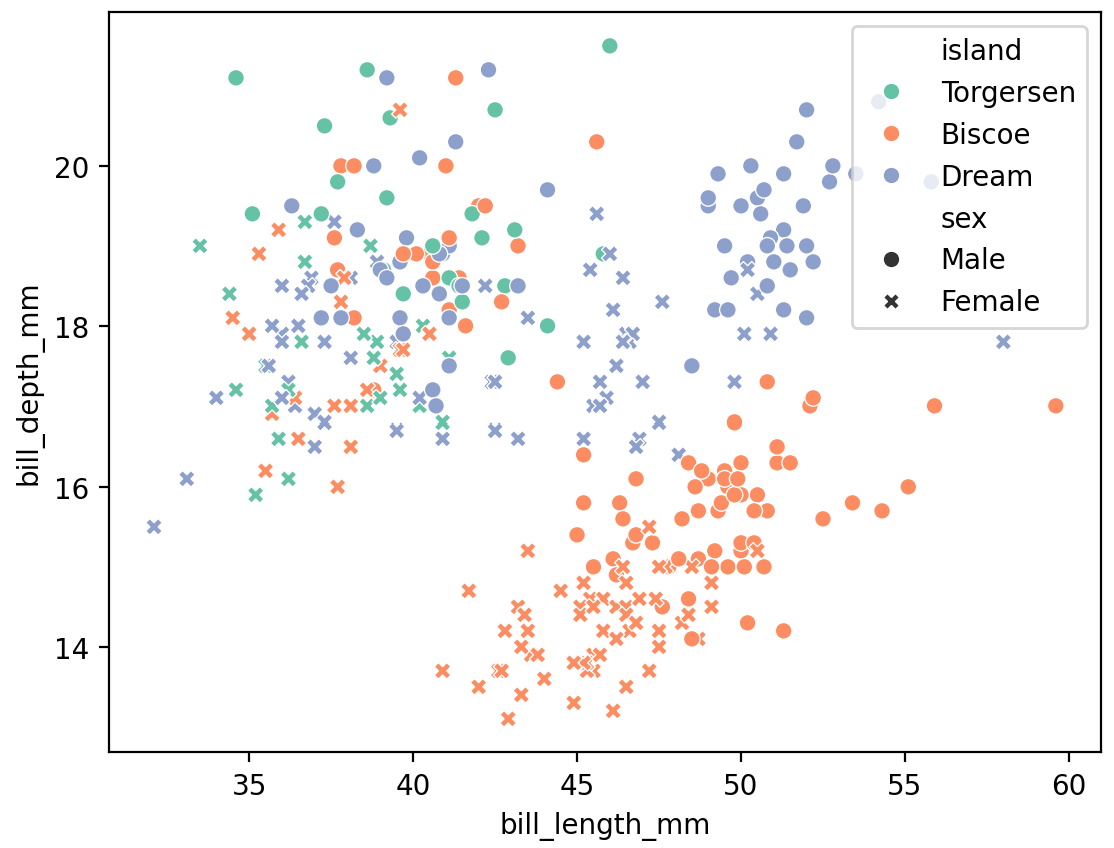
☞ relplot
# 구역을 나누고 싶다면 relplot 사용하여 구역을 나눌 컬럼을 col에 넣기
sns.relplot(data=penguins, x='bill_length_mm', y='bill_depth_mm', hue='sex', col='island', kind='scatter')
plt.show()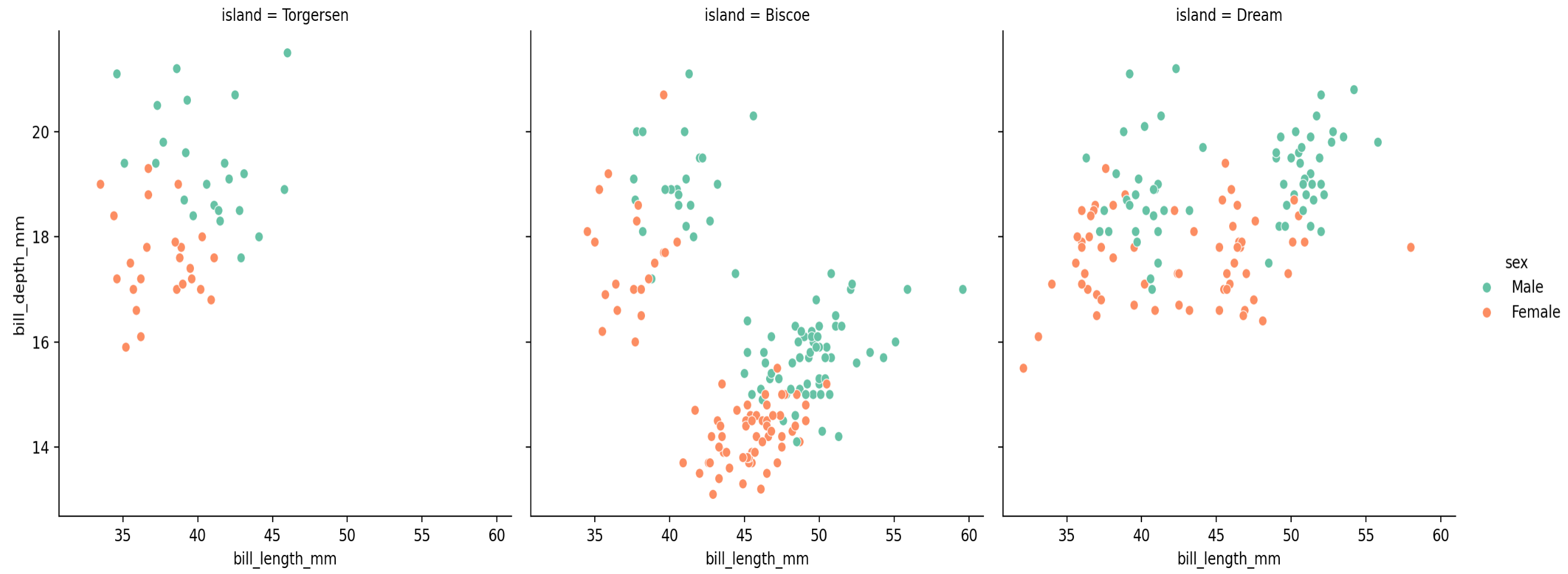
☞ lmplot
# lmplot을 사용하여 회귀선 사용
sns.lmplot(data=penguins, x='bill_length_mm', y='bill_depth_mm', hue='sex', col='island')
plt.show()
◆ 분포 살펴보기
☞ 히스토그램
sns.displot(data=데이터, x=x축 컬럼, y=y축 컬럼, hue=색)sns.displot(data=penguins, x='flipper_length_mm')
plt.show()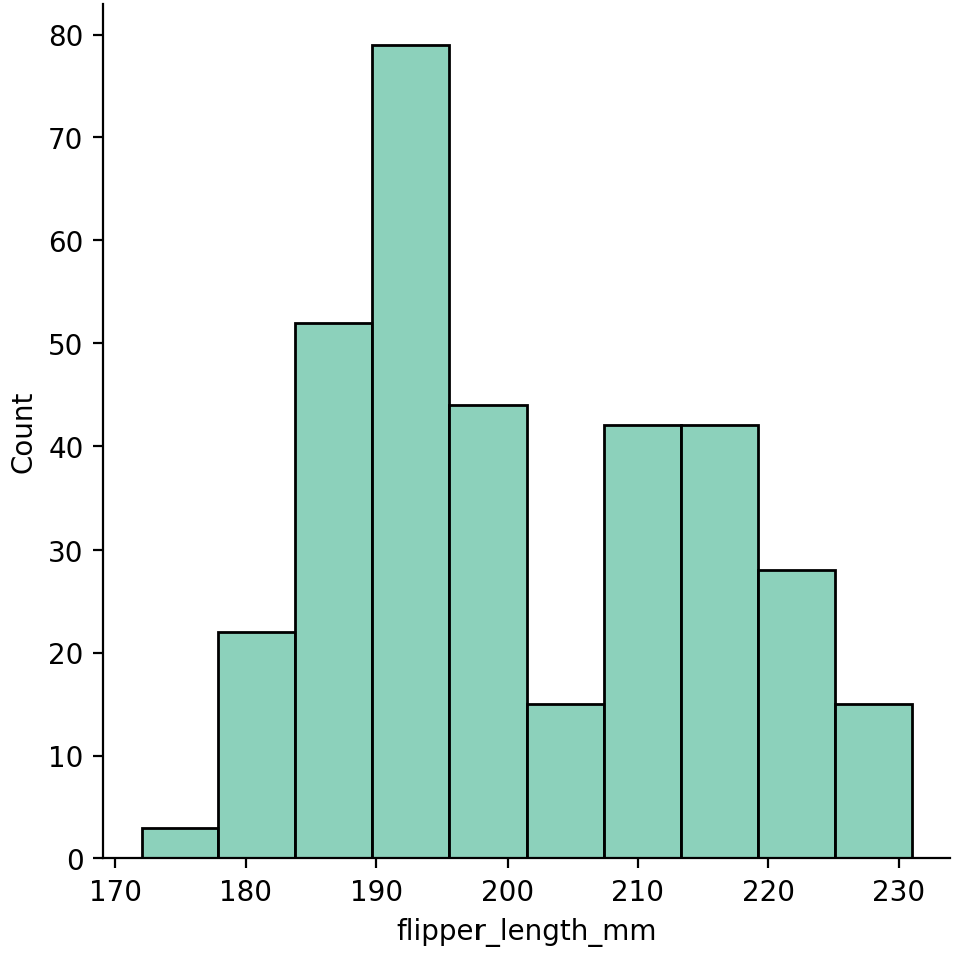
☞ 밀도 분포
sns.displot(data=데이터, x=x축 컬럼, hue=색, kind='kde')sns.displot(data=penguins, x="flipper_length_mm", kind="kde")
plt.show()
☞ 상자 그림
sns.boxplot(data=penguins, x=x축 컬럼, y=y축 컬럼, hue=색)sns.boxplot(data=penguins, x='body_mass_g', y='species', hue='sex')
plt.show()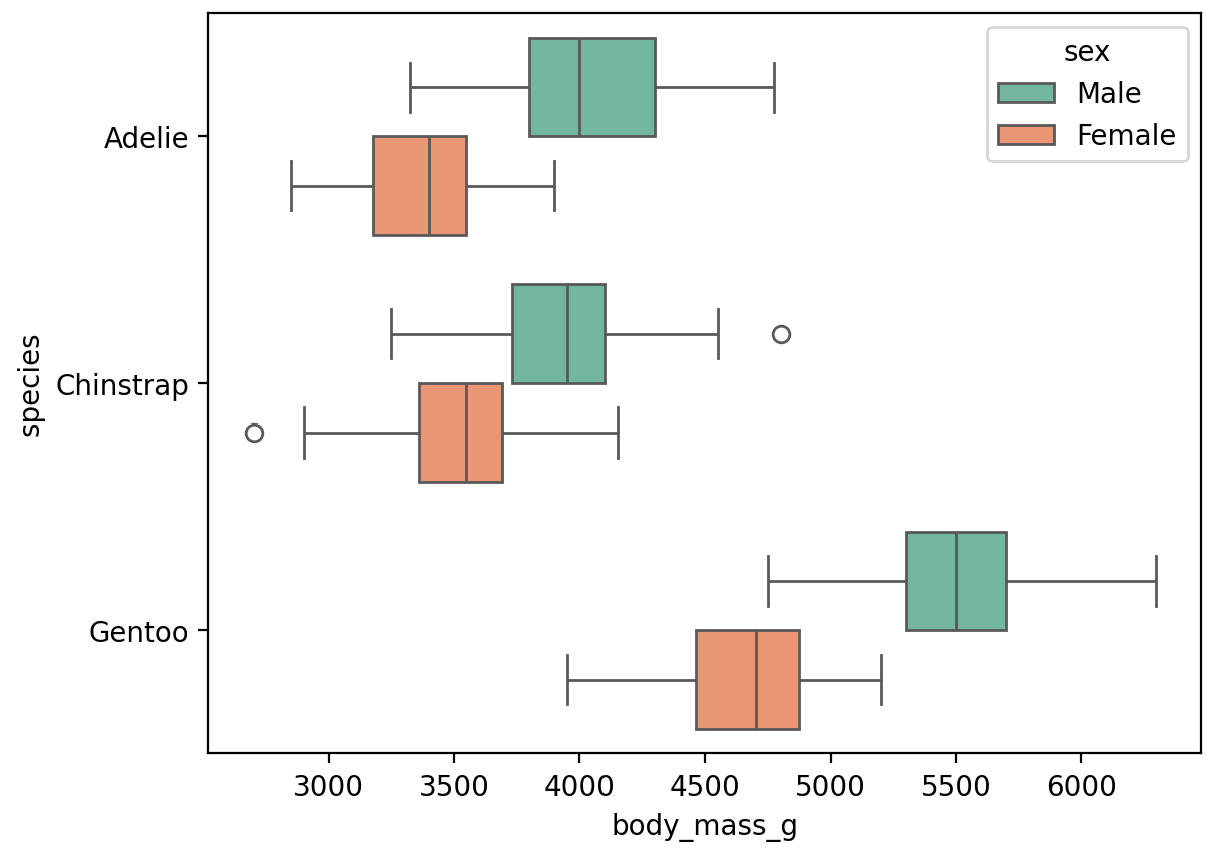
☞ 여러 컬럼들간의 분포
sns.pairplot(data=데이터, hue=색)sns.pairplot(data=penguins, hue='species')
plt.show()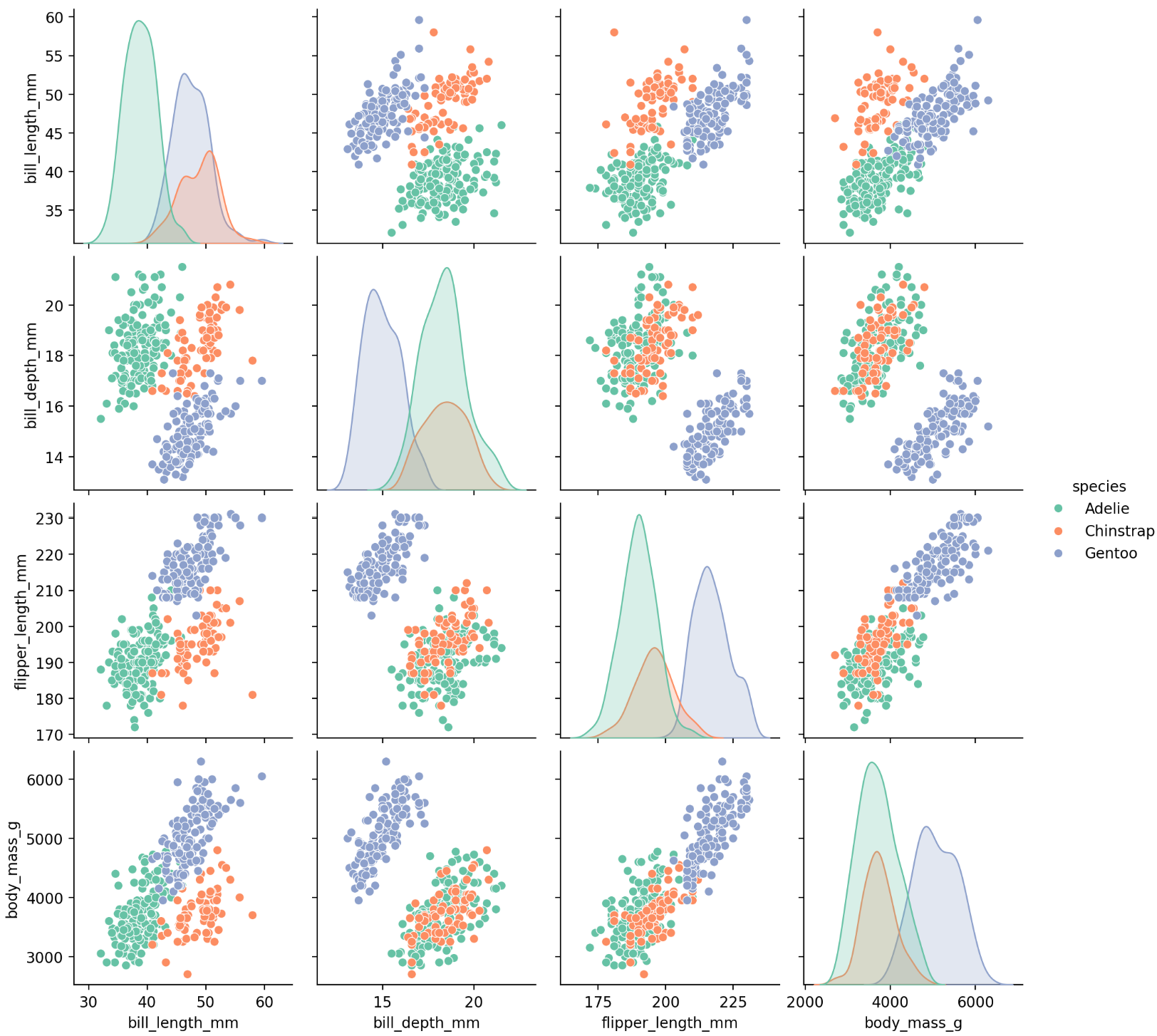
◆ 막대 그래프
■ sns.countplot(data=데이터, x=x출 컬럼, hue=색) - x축의 범주별로 행의 개수를 카운트하여 시각화
■ sns.barplot(data=데이터, y=y축 컬럼, hue=색)
☞ countplot
sns.countplot(data=titanic, x='class', hue='alive')
plt.show()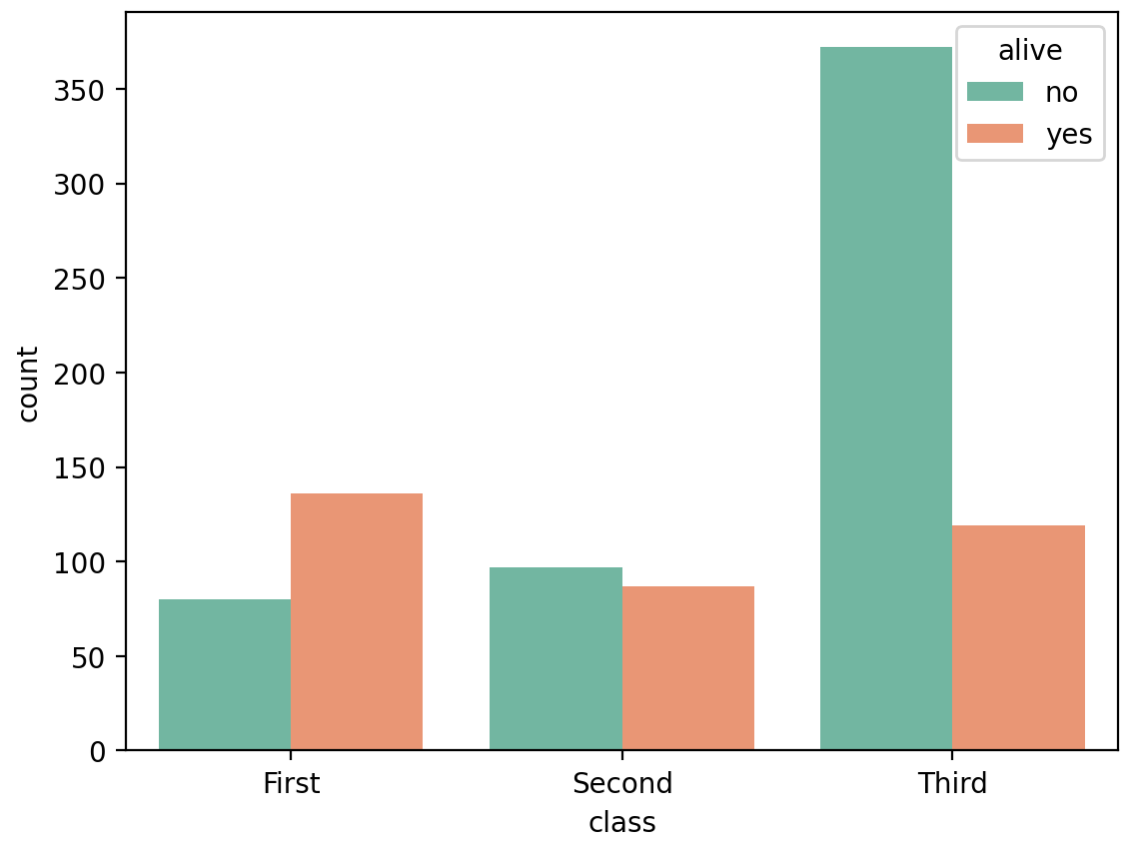
☞ barplot
sns.barplot(data=titanic, x='class', y='survived', hue='sex')
plt.show()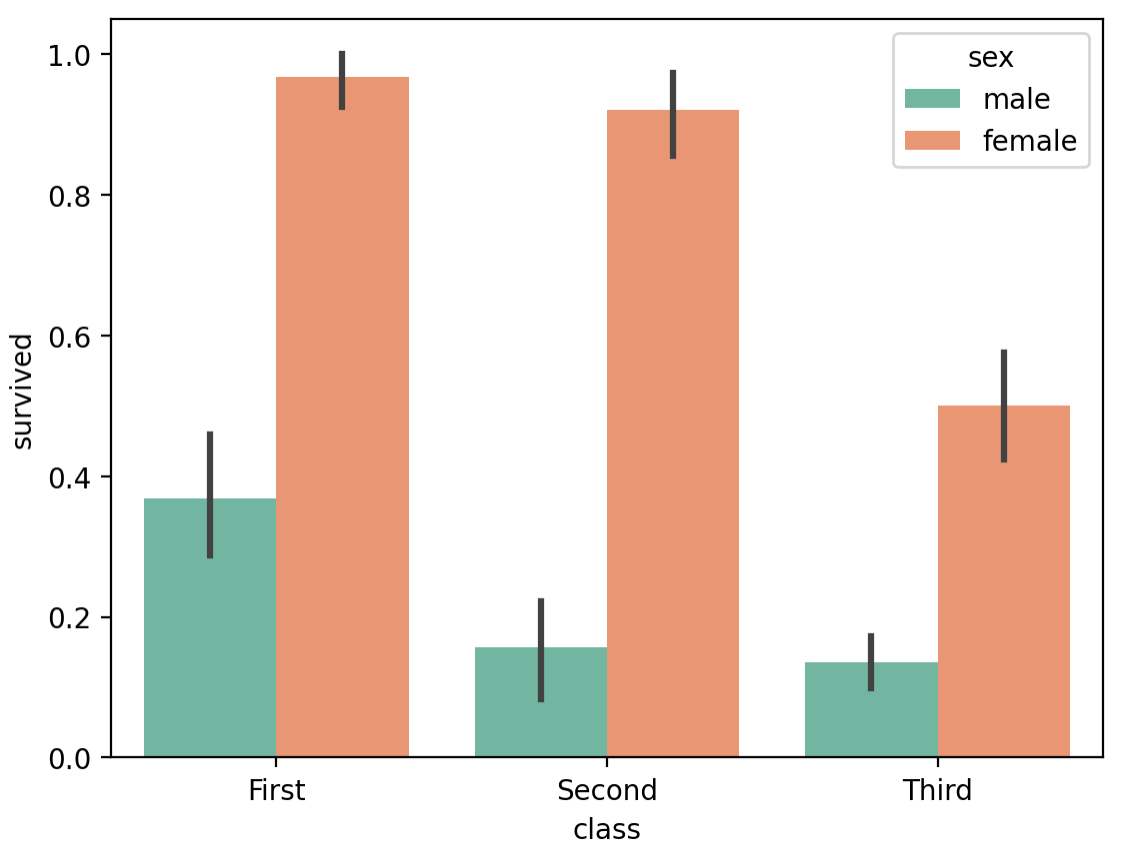
◆ 선 그래프
■ sns.lineplot(data=데이터, x=x출 컬럼,y=y축 커럶, hue=색)
☞ lineplot
sns.lineplot(data=flights, x="year", y="passengers", hue='month')
plt.show()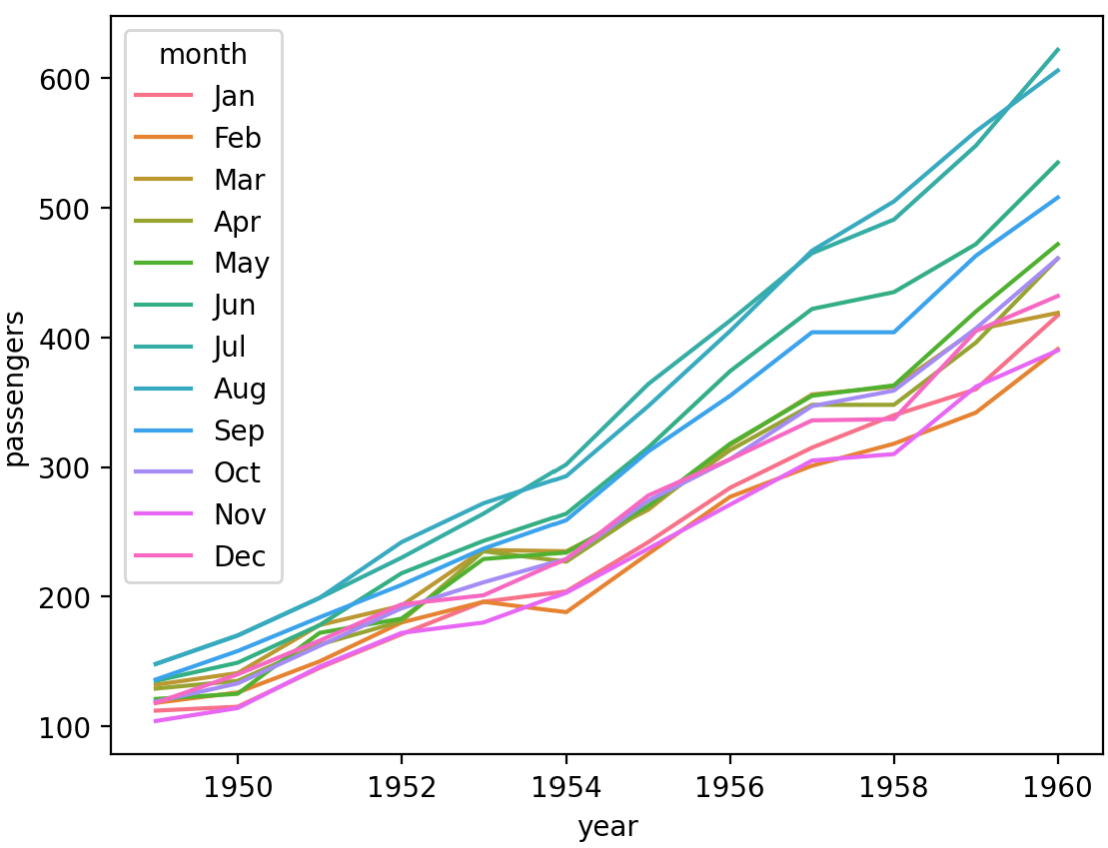
◆ 히트맵
■ sns.heatmap(data=데이터, annot=값 표시 여부, fmt=값 포맷, cmap=컬러맵)
☞ heatmap
sns.heatmap(data=titanic_corr, annot=True, fmt='.2f', cmap='YlOrBr')
plt.show()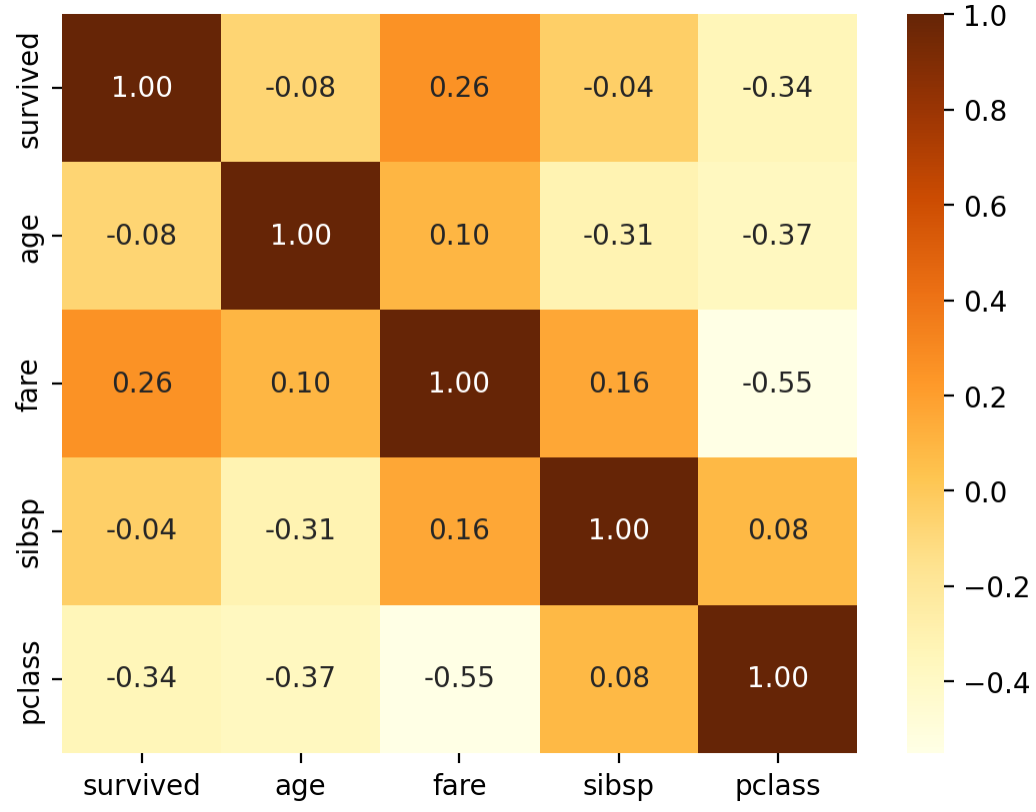
1. 크롤링
■ jupyter 실행
1. 바탕화면 검색창에 jupyter notebook을 검색

2. cmd창 뜨고 웹 뜨는거 확인
3. New -> New folder 클릭해서 새 폴더를 만들어주고 -> 폴더 들어가서 New -> Netebook 클릭

4. Python 3(ipykernel) 선택 -> Select 클릭

■ 크롤링하기 전, 라이브러리 설치 등
# 라이브러리 설치
# chrome-driver 컨트롤을 도와주는 라이브러리
!pip install selenium
# webdriver-manager : chrome-driver를 다운받아주는 라이브러리
!pip install webdriver-manager
# 설치가 잘 된 건지 버전 확인
import selenium
selenium.__version__
※ 참고
AI 관련 라이브러리 - Tensorflow, Pytorch, Scikit-Learn
# 크롬 드라이버 설치
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
ChromeDriverManager().install()
# 크롬창 띄우기
browser = webdriver.Chrome()
browser.get('http://www.naver.com')
↑
에러 뜰 시 수동으로 진행
크롬창 → 설정 → Chrome 정보(최신 업데이트 잘 되었는지 확인) → 그래도 실행이 안되면
아래에서 크롬 버전 다운로드 → 다운로드된 파일에서 exe 파일을 jupyter 사용할 폴더 안에 넣기
Chrome for Testing availability (googlechromelabs.github.io)
Chrome for Testing availability
chrome-headless-shellmac-arm64https://storage.googleapis.com/chrome-for-testing-public/124.0.6367.155/mac-arm64/chrome-headless-shell-mac-arm64.zip200
googlechromelabs.github.io
■ 네이버로 날씨 데이터
1. 먼저 네이버 브라우저 띄우기
from selenium import webdriver
from seleniuhttp://m.webdriver.common.by import Bybrowser = webdriver.Chrome() # 크롬 열기url = 'http://naver.com'
browser.get(url)
or
browser.get('http://www.naver.com') # 네이버 이동
2. 실행된 브라우저창에서 검색창에 마우스 우클릭 검사 -> element(요소) 탭 확인
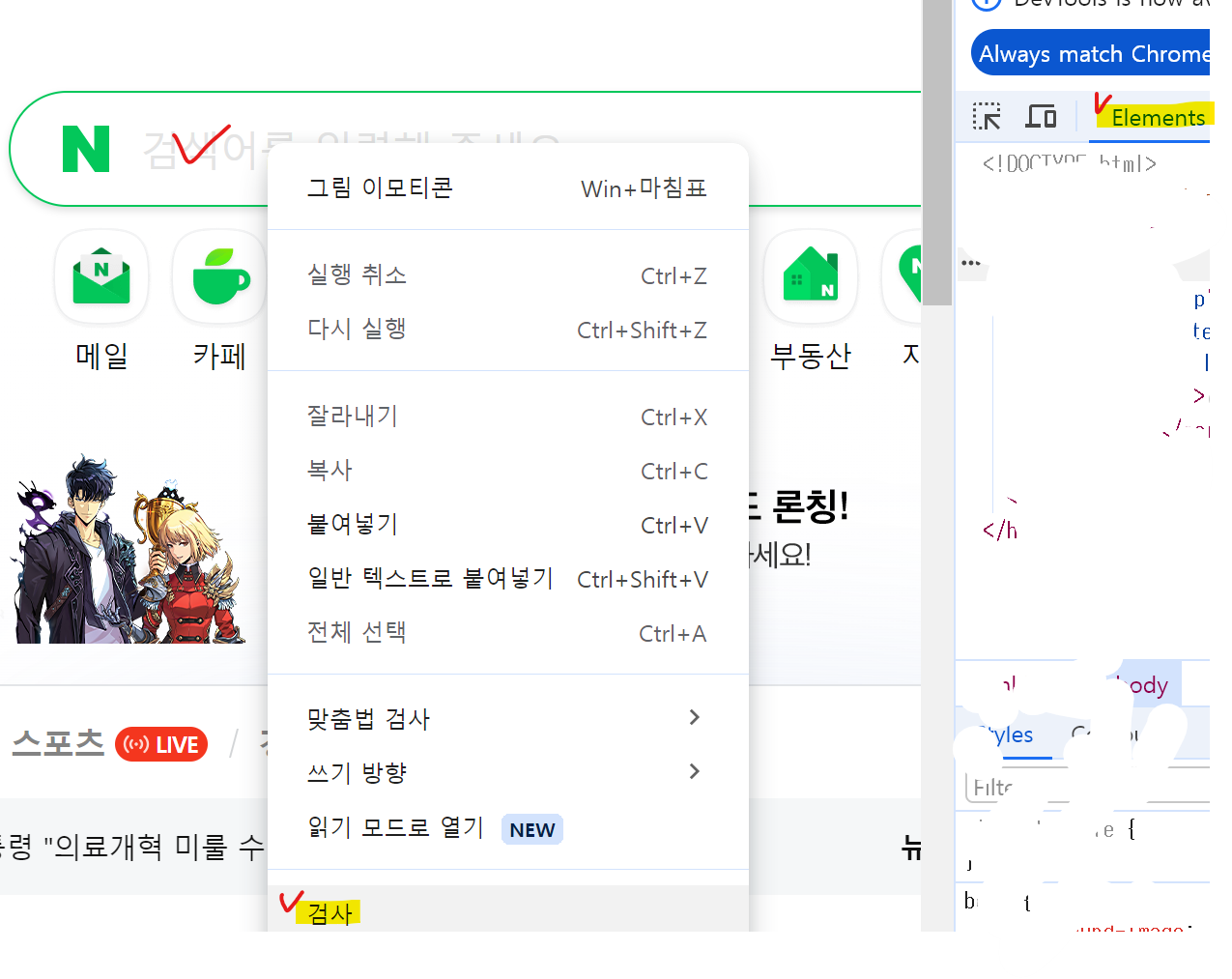
3. 검색창 클릭
browser.find_element(By.CLASS_NAME, 'search_input').click() #입력
# class_name은 브라우저에 나온 요소의 이름을 찾아서 가져온것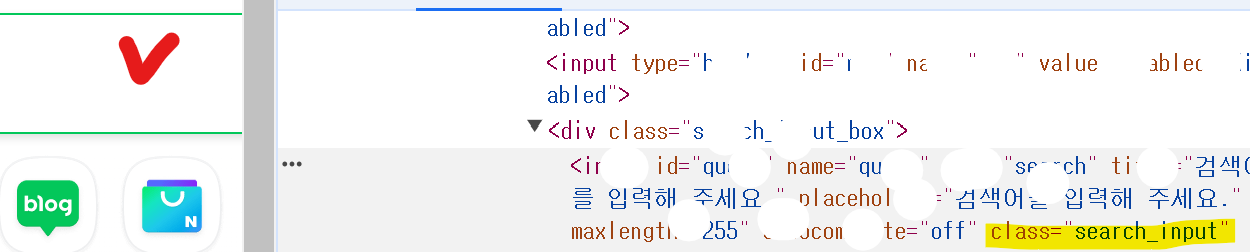
4. 검색창에 날씨 입력
browser.find_element(By.CLASS_NAME, 'search_input').send_keys('날씨')
5. 검색 아이콘을 클릭
browser.find_element(By.CLASS_NAME, 'btn_search').click()
browser.find_element(By.ID, 'search-btn').click()
6. 온도 데이터
data = browser.find_element(By.CLASS_NAME, 'temperature_text').text
data.split('\n')
or
data = browser.find_element(By.CLASS_NAME, 'temperature_text').text
data.split('\n')[1]
# browser.find_element(By.CLASS_NAME, 'temperature_text').find_element(By.CLASS_NAME, 'celsius').text
# browser.find_element(By.CLASS_NAME, 'temperature_text').find_element(By.CLASS_NAME, 'blind').text
7. 체감, 습도, 풍향 데이
#data = browser.find_element(By.CLASS_NAME, 'summary_list').text
#data.split('')
parent = browser.find_element(By.CLASS_NAME, 'summary_list')
parent.find_elements(By.CLASS_NAME, 'sort')
■ 부동산 & 구글 뉴스 데이터
◆ 부동산 데이터
1. 데이터를 얻고 싶은 사이트의 url 복사해서 열기
url = 'https://new.land.naver.com/complexes/111515?ms=37.4972982,127.106488,18&a=APT:PRE:ABYG:JGC&e=RETAIL&ad=true'
browser.get(url)
2. 얻을 데이터 class_name 찾기
browser.find_element(By.CLASS_NAME, 'complex_price--trade').text
3. 금액만 가져오기
parent = browser.find_element(By.CLASS_NAME, 'complex_price--trade')
parent.find_element(By.CLASS_NAME, 'data').text
◆ 구글 뉴스 데이터
1. 해당 처음 뉴스기사 url 이동
url = 'https://www.google.com/search?q=%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D&sca_esv=c039891655a7704c&ei=S4E8ZqaKGqeEvr0PrOyv6Ag&udm=&ved=0ahUKEwjm24Tfi4CGAxUngq8BHSz2C40Q4dUDCBA&uact=5&oq=%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D&gs_lp=Egxnd3Mtd2l6LXNlcnAiD-uNsOydtO2EsOu2hOyEnTIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgARIzwtQlQVYqgZwAXgBkAEAmAF-oAHbAaoBAzEuMbgBA8gBAPgBAZgCA6AC5AHCAgoQABiwAxjWBBhHwgIIEAAYgAQYogSYAwCIBgGQBgqSBwMyLjGgB8wH&sclient=gws-wiz-serp'
browser.get(url)
2. 뉴스 제목
browser.find_element(By.CLASS_NAME, 'n0jPhd').text
3. 뉴스 내용
browser.find_element(By.CLASS_NAME, 'GI74Re').text
4. 언론사
browser.find_element(By.CLASS_NAME, 'MgUUmf').text
5. 작성시간
browser.find_element(By.CLASS_NAME, 'LfVVr').text
6. 링크
browser.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
'데이터분석 부트캠프' 카테고리의 다른 글
| 데이터분석 부프캠프 14기 - 5주차 (0) | 2024.05.24 |
|---|---|
| 데이터분석 부프캠프 14기 - 4주차 (0) | 2024.05.17 |
| Python 주피터 설치 방법 & 가상환경 설정 (0) | 2024.05.03 |
| 커리어 성장 컨퍼런스_데이터분석 전문 데프콘 강의 후기 (1) | 2024.04.30 |
| 데이터분석 부프캠프 14기 - 2주차 (0) | 2024.04.30 |


