◆ 목차
- 통계학 / 엑셀 데이터 탐색
- 1주차 이어서 탐색적 데이터 분석(EDA)
- 데이터 전처리 / 머신러닝 / 데이터 시각화
- Python
1. 통계학
■ 통계학 정의
- 산술적 방법을 기초로 하여, 주로 다량의 데이터를 관찰하고 정리 및 분석하는 방법을 연구하는 수학의 한 분야
① 학문으로서의 통계학
② 실무 능력으로서의 통계학
☞ 사례에 대한 예시를 보여주셨는데 그중 ARIMA 분석기법이 나왔습니다. 어떤 분석기법인지 잘 몰라서 따로 알아보았습니다!
AR(Autoregression) 모형과 MA(Moving Average) 모형을 합친 모형이라고 합니다.
- 시계열 데이터의 정상성(Stationary)을 가정
■ 정상성이란?
- 평균, 분산이 시간에 따라 일정한 성질이라고 합니다, 이것은 시계열 데이터의 특성이 시간의 흐름에 따라 변하지 않음을 의미하는 것입니다.
■ 정상 시계열 변환
- 변동폭이 일정하지 않은 경우 → 로그 변환
- 추세, 계절성이 존재하는 경우 → 차분(Differencing, Yt - Yt -1)
- 1차 차분으로 정상성을 띄지 않으면 차분을 반복합니다.
■ ARIMA 모형이란?
- d차 차분한 데이터에 AR(p) 모형과 MA(q) 모형을 합친 모형.
■ AR 모형식
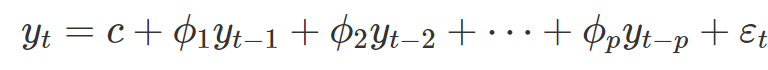

■ OKR, KPI 등 지표를 통한 방법론
- 적절한 지표를 선정하는 방법과 기준
■ Growth Marketing(Performance Marketing)
→ 비즈니스의 근거가 되는 데이터 수치는 이미 다양한 도구를 통해서 수집, 가공, 시각화가 이루어지고 있습니다.
→ 데이터를 기반으로 수많은 의사 결정을 수행하는 것은 더 이상 데이터 직군 종사자만의 일이 아닙니다.
■ 실무적으로 통계수치를 옳바르게 해석하기 위한 방법은?
- 실무적 요구 능력
1) 통계 수치를 해석
2) 올바른 인과 관계 분석
3) 인사이트를 도출하는 일
■ 기술 통계학
- 요약 통계량, 그래프 표 등을 이용해 데이터를 정리, 요약하여 데이터의 전반적인 특성을 파악하는 방법
■ 추론 통계학
- 데이터가 모집단으로부터 나왔다는 가정하에
■ 가설 검정
- 통계적 추론의 하나로서, 모집단 실제의 값이 얼마가 된다는 주장과 관련해, 표본의 정보를 사용해서 가설의 합당성 여부를 판정하는 과정
① 귀무 가설
- 기본적으로 참으로 추정되며 처음부터 버릴 것으로 예상하는 가설
② 대립 가설
- 보통 독립 변수와 종속 변수 사이에 어떤 특정한 관련이 있다는 결과가 도출
■ 대립 가설의 종류
- 귀무 가설과 반대되는 대립 가설에는 3가지 형태가 있음
■ p-value
- 귀무 가설이 맞다는 전제 하에, 표본에서 실제로 관측된 통계치와 같거나 더 극단적인 통계치가 관측될 확률
■ t-test
- 두 집단(또는 한 집단의 전/후)의 평균에 통계적으로 유의미한 차이가 있는지를 검정하는 것을 의미
- 서로 다른 두 집단이나 같은 집단을 비교할 수도 있다고 합니다!
■ t-test 시행 단계(적합한 t-test 방법을 선택하기 위한 F검정 필요)
- 변수(집단) 선택 → F-검정 → t-test → 결과 해석
■ F - 검정
- 두 집단의 분산에 통계적으로 유의미한 차이가 있는지를 검정
① F-검정의 귀무 가설
- 두 집단의 분산에 유의미한 차이가 없다 → 등분산 가정
② T-test / F-검정의 대립 가설
- 두 집단의 분산에 유의미한 차이가 있다 → 이분산 가정
■ t-test 가설 설정
- 두 집단의 평균에 통계적으로 유의미한 차이가 있는지를 검정
■ 회귀 분석의 개념
- 2개 이상의 연속형 변수(수치)인 종속 변수와 독립 변수 간의 관계를 파악하는 분석
y = ax + b
y는 종속 변수(우리가 알고 싶은 값), x는 독립변수(우리가 알고 있는 값)
■ 회귀 분석의 목적(y와 x사이의 1차 방정식 구하기)
- 두 변수 간의 관계를 파악해 우리가 알고 싶은 값을 예측하는 것
① 단순 선형 회귀 분석
② 단순 선형 회귀 분석의 원리
■ 단순 선형 회귀 분석의 평가와 해석
- 결정계수, F값, Y절편 및 X1의 계수 확인
① 결정계수
- 0 ~ 1을 가지며 1에 가까울수록 회귀 모형이 실제 값을 잘 설명함
② F값
- F값이 0.05 미만이면 이 회귀 모형이 유의미하므로 사용 가능함
③ y = ax+b
- y절편은 b값을, X1값은 a(기울기)를 뜻함
■ 다중 선형 회귀 분석
- 독립 변수가 x1, x2, x3...등으로 2개 이상일 때 독립 변수들과 종속 변수 간의 관계를 파악하는 분석
■ 다중 선형 회귀 분석의 평가와 해석
- 조정된 결정 계수, F값, Y절편 및 각 독립 변수의 p-value와 계수 확인
① P값이 0.05 보다 작은 변수들이 종속 변수 y(매출)에 영향을 미칠 것으로 기대되는 변수
→ 강사님께서는 이런 느낌으로 하신다고 하셨습니다!(참고)
00. 상관 분석을 활용해 16개 미만의 종속 변수와 상관관계가 강한 변수들을 추출
01. 모든 독립 변수들을 포함한 다중선형회귀분석
02. 유의미한 독립 변수들로만 다시 다중선형회귀분석
03. 유의미한 독립 변수들을 각각 종속 변수와 단순선형회귀분석
■ 오차값 계산
- 오차값 : 실제값 - 예측값
■ 결정 계수(r의 제곱)
- 0 ~ 1 사이의 값을 가지는 것(0 ~ 100%)
■ 분산형 차트에 추세선 넣기
- 분산형 차트 만들고 → 점 클릭하여 우클릭 → 추세선 서식에서 선형 체크 → 맨아래 수식을 차트에 표시를 체크
■ 시계열 데이터 분석
- 시간의 흐름에 따라 발생된 데이터를 분석하는 기법
■ 시계열 데이터의 유형
- 정상성을 가지고 있는 정상 시계열 데이터와 정상성을 가지고 있지 않은 비정상 시계열 데이터로 구분
① 정상성 : 추세나 계절성을 가지고 있지 않으며, 관측된 시간에 무관한 성질
② 비정상성
■ 지수 평활벌
- 현재 시점에 가까운 시계열 자료에 큰 가중치를 주고, 과거 시계열 데이터일수록 작은 가중치를 주어 미래 시계열 데이터를 예측하는 기법
■ 단순 지수 평활법
- 미래의 예측 값 = 과정의 실제 값 + a + 과거의 예측값 * (1-a)
a = 실제 값을 반영할 가중치(0 ~ 1 사이의 값)
■ FORECAST.EST
- 엑셀에서 사용할 수 있는 지수 평활법 관련 예측 함수
FORECAST.ETS(target_date(예측 날짜), values(알고 있는 실제 값들 ex-과거 매출 등), timeline(과거의 날짜들),
[계절성주기],[누락데이터처리],[중복시계열처리])
2. 기술 통계
■ 변량
- 자료의 수치, 데이터의 값을 의미
■ 계급
- 변량을 일정한 간격으로 나눈 구간
- 계급을 정할 때 변량의 최소, 최대를 고려
■ 도수
- 각 계급에 속하는 변량의 개수
■ 상대 도수
- 각 계급에 속하는 변량의 비율
■ 도수분포표
- 주어진 자료를 계급에 따라 나눔
- 각 계급에 속하는 도수를 조사
- 오른쪽 그림과 같이 순서대로 요약
■ 히스토그램
- 도수분포표를 시각화해서 보는 가장 기본적인 방법
■ 평균, 분산, 표준편차 개념
- 평균 : 산술평균(변량의 합을 변량의 수로 나눈 값)
- 분산 : 변량이 중심(평균)에서 얼마나 떨어져 있는지를 보기 위한 통계량
- 표준편차 : 분산의 제곱근, 관찰값들이 얼마나 흩어져 있는지를 하나의 수치로 나타내는 통계량
■ 정규분포, 표준정규분포, 표준화 개념
1) 정규분포 : 평균 u와 표준편차 시그마에 대해 확률밀도함수를 가지는 분포/ 연속형 데이터들이 종모양의 형태를 띰
- 실험 오차를 분석하면서 사용
- 독립적인 확률변수들의 평균은 정규분포에 가까워진다
- 평균, 표준편차에 따라 달라짐
2) 표준정규분포 : 정규분포 중에서 평균이 0, 표준편차가 1인 정규분포
3) 표준화 : 다양한 형태의 정규 분포를 표준 정규 분포로 변환하는 방법
- 표준 정규 분포에 대한 값을 이용해 원래 분포의 확률을 구할 수 있음.
- 다양한 데이터를 균일한 기준으로 비교 가능
- 다양한 통계량을 구하는 과정에서 계속 등장
■ 기술통계
- 데이터의 간결한 요약 정보
- 수치적인 통계량 또는 시각화
- 데이터의 특징을 파악하는 관점
→ EDA 단계에서 주요 사용
■ 추론통계
- 모집단으로부터 추출한 샘플을 사용
- 모집단에 대한 추론이 목적
- 전체 모집단을 조사할 수 없을 때 유용
- p-value를 구하는 등의 과정을 거쳐서 모집단에 대한 가설을 검정
■ 대표값
- 자료의 특성을 나타낼 수 있는 대표성을 띠는 수치
■ 기초통계량
① 중심경향성 : 데이터 분포의 중심을 보여주는 값
- 최빈값 : 가장 빈번하게 나타내는 값/ 범주형 자료에서 대표값으로 최빈값을 주로 사용
- 중앙값 : 자료를 크기 순으로 나열했을 때 가운데 위치하는 값/ 순서형 자료의 대표값으로 적합/ 이상치에 크게 영향 X
- 산술평균 : 자료의 값을 모두 더해서 자료의 수로 나눈 값/ 연속형 자료에 사용/ 이상치에 영향을 크게 받을 수 있음
- 가중평균 : 자료의 중요도에 따라 가중치를 부여한 평균
- 기하평균 : 성장률 등 이전 시점에 대한 비율에 대한 평균을 구할 때 유용 Ex) 주가 상승률
- 퍼짐 정도 : 자료가 얼마나 흩어져있고 얼마나 모여있는지
- 왜도 : 분포의 좌우 비대칭성 정도
- 첨도 : 분포의 뾰족한 정도
3. 회귀분석, 공분산
■ 회귀분석
- 변수 사이의 모형을 구한 뒤 적합도를 측정해 내는 분석 방법 / 대표적인 모형이 선형 회귀 모형
- 결과를 설명하기 위해서 하나의 변수만 영향을 주지는 않음
- 결과를 종속변수, 종속변수를 설명하기 위한 변수들을 독립변수라고 함
■ 공분산
- 2개의 확률변수의 선형 관계를 나타내는 값
★ 통계 실습을 통해 해보기!
☞ 통계를 따로 배워본 적은 없지만 강의를 통해 통계는 이런 거고 분석에 통계가 필요한 이유에 대해 조금은 알게 되는 시간이었습니다!
4. 데이터 분석 단계
■ 데이터 분석 과정
1) 데이터 분석 기획
2) 데이터 수집 및 정제
3) 데이터 분석 모델링
4) 평가 및 결론 도출
5) 분석 결과의 활용
■ 데이터 분석 단계의 대한 자세한 설명
① 데이터 분석 기획
- 비즈니스 이해 및 목표 설정
→ 비즈니스적으로 어떤 것을 이루고자 하는지
- 프로젝트 정의
→ 어떤 데이터를 바탕으로 어떤 것을 예측 / 측정할 것인지
② 데이터 수집 및 정제
- 분석에 필요한 데이터를 어떻게 수집할 것인지
- 데이터 전처리, 검증
→ 수집된 데이터의 적합성, 무결성 등을 검증
③ 데이터 분석 모델링
- 탐색적 데이터 분석(EDA)
→ 통계량 확인 및 시각화를 통한 데이터의 특성을 파악
- 모델링
→ 예측을 위한 수학적, 통계적 모델링
④ 평가 및 결론 도출
- 모델링을 통해 생성된 결과를 활용하여 결론 도출
- 성능에 대한 평가
1) 도메인에 따라, 비즈니스적 요구에 따라 성능의 기준은 달라집니다.
2) 상황에 따라 위의 과정을 수정해 가며 성능을 개선
⑤ 분석 결과의 활용
- 시스템 구현
→ 주기적으로 업데이트
- 비즈니스 인사이트
→ 의사 결정에 도움
→ 시각화(대시보드 등등)
- 서비스에 활용
→ 모델을 활용하여 서비스에 적용
3. Kaggle
■ Kaggle
- 데이터 분석 경진 대회 플랫폼으로 기업이나 단체에서 빅데이터를 제공
- 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁
→ 데이터 과학자 커뮤니티 기능도 있음
■ Kaggle을 통해 Dataset 다운
■ Kaggle을 통해 Dataset 다운(사이트 참고)
1) 사이트 접속 → 로그인 → Titanic 검색 → 탭에서 Competitions 선택
Kaggle: Your Machine Learning and Data Science Community
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
www.kaggle.com
2) Titanic - Machine Learning From Disaster 클릭 → 탭에 Data 클릭
3) 맨 아래 train.csv 클릭하고 Download All 다운로드
■ 분석 도구 Setting 방법
1) 파일 → 옵션 → 추가기능에서 아래쪽 관리에 Excel 추가 기능으로 선택하고 이동 클릭
2) 분석도구팩 체크 후 확인 → 데이터 탭에 데이터 분석 추가 확인됨
3) 먼저 숫자 데이터를 가지고 분석할 것이기 때문에 숫자 데이터 따로 옆열에 모아놓기
4) 데이터 탭에 데이터 분석 클릭 → 기술 통계법 클릭
5) 요약 통계량, 평균에 대한 신뢰 수준, K번째 큰 값, K번째 작은 값 전부 체크 후 확인
6) 통계 확인
5. 데이터 탐색 & 분석(EDA)
◆ 데이터 탐색 사례
- 대표값을 통한 데이터 탐색
→ 수집된 데이터로부터 통계량을 측정
→ 통계량을 통해 집간의 특성을 파악
- 기술 통계법 : 평균, 분산, 표준편차, 왜도, 첨도 등 통계량 확인
☞ 위에 실습했던 기술 통계법
1) 대표값으로 데이터 탐색 사례
- 엑셀 피벗 파트를 활용한 시각화
- Python을 통한 시각화
2) 데이터 시각화 : 차트를 통한 분포 확인
■ 분포를 확인할 때 같이 확인해야 할 수치
- 분포의 중심 → 평균, 중위값, 최빈값
- 퍼짐 정도 → 분산, 표준편차, 사분위수, 변동계수
- 분포의 모양(비대칭성) → 왜도, 첨도
3) 상관관계로 분석
- 각 변수 간의 비례 관계
- 변수간 상관분석, 시각
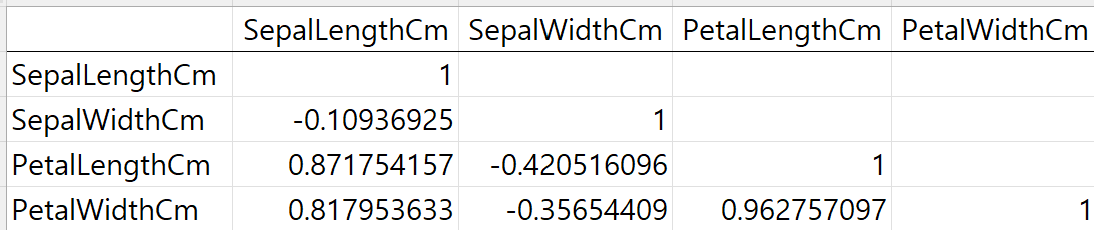
☞ IRIS Dataset을 활용하여 상관관계를 설명해 주셨습니다.
4) 결측치, 이상치 탐지
- 관측되지 않거나 추세에서 벗어난 데이터 확인
- Outliers
- boxplot(5개의 수치적 자료를 활용해 데이터의 분포와 범위를 표현한 그래프)
◆ 데이터 탐색과 통계 필요성
1) 기술 통계
- 관측된 데이터의 특성을 파악하는 좋은 수단
2) 추론 통계(많이 사용!!!!)
- 추출한 표본의 통계량 관찰 및 분석 기법을 활용하여 모집단을 추론/ p-value 등을 활용하여 추론의 신뢰도 확보
◆ 차트로 엑셀 데이터 쉽게 탐색하기
■ Exploratory Data Analysis, EDA
- 기초적인 통계 개념으로 데이터 전체를 파악
- 데이터의 형질에 대한 도메인 개념 축적
- 전처리의 방향성 제시
■ EDA 과정 실습
- 피벗 테이블을 활용한 기술 통계량 확인
- 차트를 통한 데이터 시각화
1) 히스토그램 - 수치형 변수의 분포 파악
2) 산점도 - 두 변수 간의 상관관계 파악
3) Box plot - 분위수 시각화 및 이상치 탐지
실습 1) 피벗 테이블
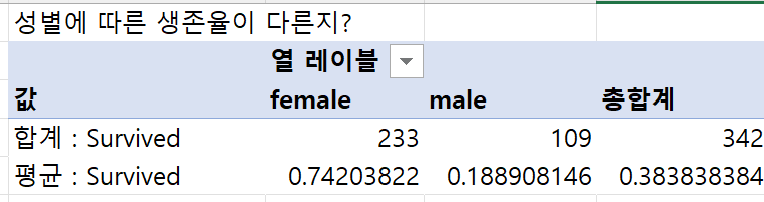
① 성별에 따라서 생존율이 다른지?
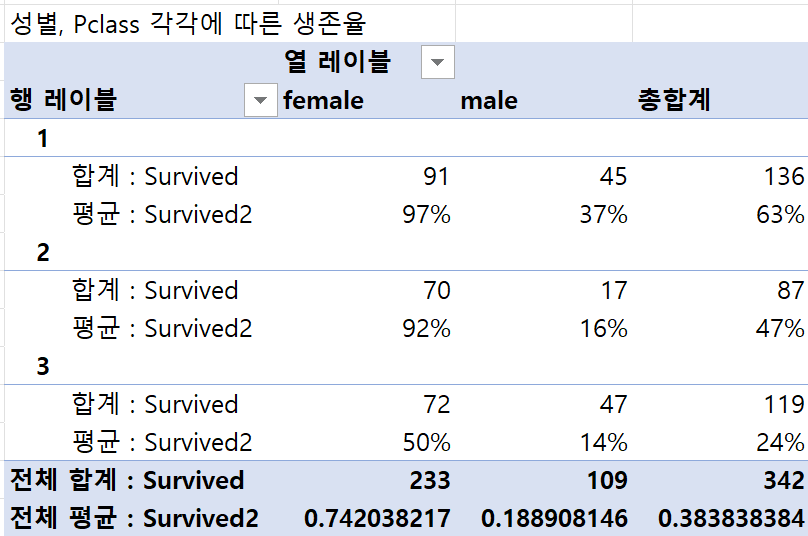
② Pclass에 따른 생존율이 다른지?

③ 성별, Pclass 각각의 따른 생존율
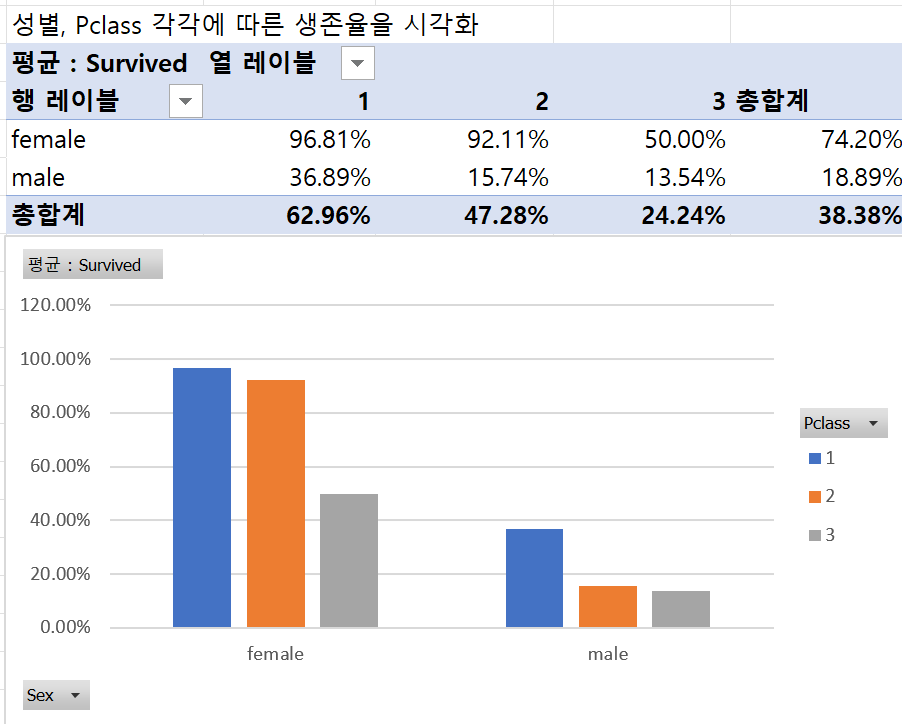
실습 2) 피벗 차트
① 성별, Pclass 각각에 따른 생존율 시각화
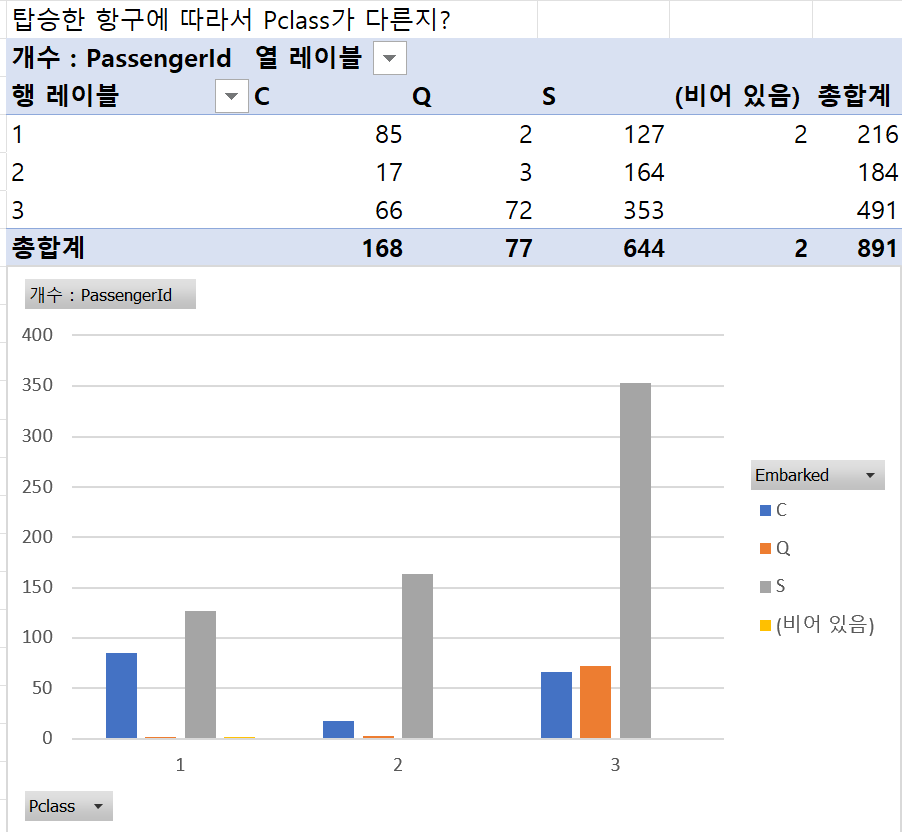
② 탑승한 항구에 따라서 Pclass가 다른가?
실습 3) 분산형 차트
- iris Dataset 다운로드
- setosa, versicolor, virginica 3가지를 비교하여 상관관계 확인하기

실습 4) 상관 분석
실습 5) Box Polat → 이상치를 탐색을 위한

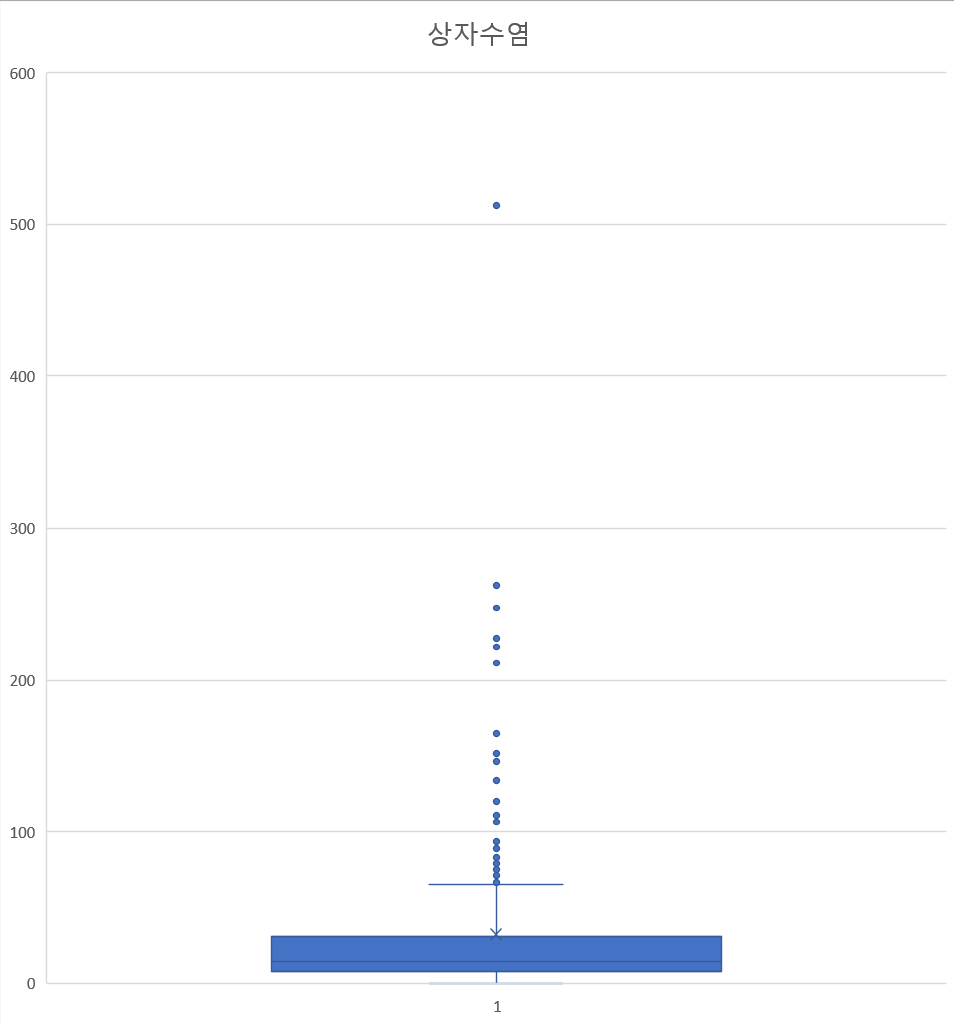
- Pclass별로 Fare의 분포를 Box plot으로 시각화

■ 전처리
- 데이터 분석에 앞서 전처리 과정을 통한 데이터 가공 및 변환
- 분포 탐색, 범주형 변수 비교 분석, 결측치 탐색 예시를 들어서 볼 수 있어서 좀 더 이해가 쉬웠습니다!
6. 공공데이터
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
→ 해당 사이트를 통해 공공데이터를 사용할 수 있습니다.
◆ 부트캠프 활용법 특강
■ 게임회사의 사업 PM이란?
- 기획, 개발을 뺀 나머지 업무 전부를 맡는 것이라고 말해주셨어요!
■ 프로젝트별로 정리 → 포트폴리오
1) 프로젝트 주제 : 어떤 문제를 해결하기 위한 프로젝트인지/ 한 줄 정의
2) 프로젝트 상세 : 기간, 활용 스킬
3) 역할 및 기여도 : 데이터 전처리, 개발, 시각화
★ 멘토 적극 활용!!!
1) 서류 준비
2) 과제 전형
3) 면접 준비
1. 기능을 활용한 데이터 전처리
■ 1주차에서 연습했던 함수들을 다시 한번 더 복습하고 연습문제를 한번 더 풀어보는 시간이 있었습니다!
■ 텍스트 나누기
- 1개의 셀에 있는 데이터를 구분 기호와 너비 등의 기준으로 2개 이상의 셀에 나누는 기능
■ ChatGPT를 통해 데이터 분석해보기
■ 중복된 항목 제거하기
■ 고급 필터
■ 데이터 유효성 검사(복습하는 실습 진행)
- 특정 셀이나 범위에, 상황에 따라 내가 유효하다고 인정하는 데이터만 입력되게 하는 기능
2. 머신러닝
■ 머신저닝이란?
- 경험과 학습을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구이며 인공지능의 한 분야
= 컴퓨터가 스스로 학습하여 인공지능의 성능을 향상하는 기술 방법
■ 딥러닝
- 인간의 뉴런
■ 머신저닝 구분
① 지도 학습(Supervised Learning)
- 정답이 있는 데이터를 활용해 데이터를 학습하고 학습한 모델이 얼마나 정답을 정확하게 맞추는지 평가하는 학습 분류, 회귀 문제들을 해결할 수 있음
■ 지도 학습의 종류
- Regression : 연속형 수치의 입력 값을 활용해 특정 수치를 예측하는 지도 학습(다음 해 매출액 예측)
- Classification : 주어진 입력 값을 2개 혹은 여러 개의 결과값으로 분류하는 지도 학습(스팸 메일 여부 판단, 대출 상환 여부 판단)
② 비지도 학습
- 정답이 없는 데이터를 활용해 데이터를 학습, 데이터가 어떻게 구성되어 있는지 혹은 어떻게 분류될 수 있는지에 대한 문제 해결
③ 강화 학습
- 에이전트가 취한 행동에 대해 보상 또는 벌점을 주어 가장 큰 보상을 받는 방향으로 유도하는 방법, 가장 큰 보상을 얻기 위해 에이전트가 해야 할 행동을 선택하는 방법을 정의하게 되는데 이를 '정책'이라고 함.
3. 데이터 시각화
■ 데이터 시각화
- 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정
■ 데이터 시각화가 중요한 이유!!
- 데이터 간의 관계를 식별하고 숨겨진 패턴이나 추세를 감지할 수 있도록 시작적 형태를 만드는걸 뜻합니다!
→ 데이터 중심 의사 결정 및 전략적 계획 수립을 지원하는 이야기를 만드는 스토리텔링입니다!
※ 예시
■ 나이팅게일의 로즈 아이어그램
→ 옛날 컴퓨터가 없었을 것 같은 시대에 사망자 현황 시각화를 했다는게 신기했고 이런 시각화는 보는 사람들이 보기 좋게 만들어주면 좋다는걸 쉽게 이해할 수 있는 예시였습니다!
차트를 그릴 때 고민하기!!
1) 숫자 데이터로 그릴지
2) 차트 종류 선택
- 어떤 종류를 선택하여 잘 보여줄지
3) 차트를 효과적으로 다룰 수 있는 효과
■ 차트를 효과적으로 디자인할 수 있는 4단계
1) 차트에 모든 데이터를 단색으로 변경
2) 강조해야 하는 데이터 선정
3) 메인 컬러 1개 선정
4) 2개의 중요 데이터에만 3의 메인 컬러 적용
■ 거품형 차트
- 거품의 위치, 거품의 크기, 거품의 색 등을 활용해 정보를 표시
☞ 여기서 차트 배경으로 사진 넣는 건 방법
(배경으로 할 사진을 먼저 복사 → 차트에서 우클릭 → 차트 영역 서식 → 그림 또는 질감 채우기 → 클립보드)
★ 실습을 통해 해보기!
- 데이터 시각화 폴더, 추가 실습 자료
※ 서적 추천!!!
- DATA SMART 엑셀로 이해하는 데이터 과학 입문, 존 포먼 지음
1. Python
■ Python
- 오픈 소스로 무료이면서 이해하기 쉬운 언어
- 문법이 간결하며 가독성이 뛰어남
- 인터프리터 언어이다 = 컴파일 없이 코드를 바로 실행 가능
- 인덴트(띄어쓰기)에 민감
☞ 웹 프로그래밍/ 데이터 분석/ 머신러닝 & 딥러닝/ 데이터베이스 프로그래밍 등 여러가지를 할 수 있음
2. 변수
■ 변수
- 데이터를 저장하고 추후에 사용할 수 있게 해주는 저장 공간
- 이름과 값으로 구성
- 이름은 변수를 참조할 때 사용, 값은 실제 데이터를 의미
■ 변수를 만드는 방법
- 변수 이름 = 저장할 값
# 예제 1
a = 10, b = 1
print(a + b)
# 출력값은 11# 예제 2
# a, b = a에 저장할 값, b에 저장할 값
a,b = 10, 20
print(a)
print(b)
# 출력값 10, 20 출력# 예제 3
a = b = 100
print(a)
print(b)
# 출력값은 100, 100
■ 변수 이름 규칙
- 영문자 + 숫자(혹은 언더바 "_") 형식으로 사용
Ex) a, a1, test1, test_1
■ 변수 종류
# 숫자형
a = 1
b = 0.1
# 문자형
a = "Hi"
# List
a = [1, 2, "Hi", b]
# 튜플(tuple)
a = (1, 2, 3, 'b')
# 딕셔너리(dict)
a = {'b': 1, 'c' : 2}
# 집합(set)
a = {1, 2, 3, 3}
■ print 함수
- 결과물을 출력하는 함수
- 변수 or 출력하고 싶은 결과물
■ 줄바꿈
- \n
3. 숫자형
■ 정수형(int) / 실수형(float)
- 정수형 : 123, -123, 0
- 실수형 : 1.2, -1.2, 20e3, - 20e3
■ 사칙연산
a = 3
b = 4
print(a + b) / 7
print(a - b) / -1
print(a * b) / 12
print(a / b) / 0.75
■ 다른연산
# 제곱
print( a ** b) # a의 b제곱
# 나눗셈 후 나머지
print(a % b)
# 나눗셈 후 몫
print(a // b)
■ 할당연산
- 변수 a는 100값을 가질 때, 변수 a에 1을 더해서 a에 덮어씌우기
a = 100
print(a) / 100
# 할당변수 사용
a = 100
print(a) / 100
a += 1
print(a) / 101
■ 문제에 적용해보기
★ 연습문제
품목 가격
사과 2500원
포도 4000원
망고 5500원
고객 품목 판매수량
A 사과 2
A 포도 3
B 포도 5
C 사과 1
C 포도 2
C 망고 1
1) 총 매출 구하기
사과 = 2500
포도 = 4000
망고 = 5500
a = 사과 * 2 + 포도 * 3
b = 포도 * 5
c = 사과 + 포도 * 2 + 망고
total = a + b + c
2) 고객단가 구하기
total = a + b + c
total / 3
3) 자연수 21이 홀수인지 짝수인지 판별
a = 21
a % 2 == 1
4) 코드에서 a에 들어갈 값은?
a = b = 10
a += 1
a *=2# 풀이
a = 10, b = 10
a += 1 / 10 + 1 / 11
a *= 2 / 11 * 2 / 22
3. 문자열
■ 문자열
- 문자 형태로 이루어진 자료형
- " " or ' ' 감싸주기
a = "Hi"
print(a) / "Hi"
■ 인덱스
- [ ]를 통해 지정할 수 있고 첫 번째 위치는 0, 마지막 위치는 -1로 표현
- : 를 통해 슬라이싱을 할 수 있음
Ex) 변수 [시작 인덱스:끝 인덱스:간격]
- 공백도 한 칸을 차지함

■ 문자열 길이 구하기
- len
Ex) a = "So, cute" / len(a)
■ 문자열과 숫자형의 혼용
- 숫자형을 문자열로 변형 / 문자열을 숫자형으로 변형
→ str(숫자형 변수) / 정수 : int, 실수 : float
→ print(a + str(b)) / print(int(a) + 1), print(float(a) + 1)
■ 문자열 포맷팅
- 문자열 안에 어떤 값을 삽입하는 방법
num = 10
a = "I happy {}".format(num)
num = 10
a = f"I happy {num}"
■ 문자열 함수
- upper : 대문자로 변환한 값을 출력
- lower : 소문자로 변환한 값을 출력
- lstrip(왼쪽), rstrip(오른쪽), strip(양쪽) : 공백 제거한 값을 출력
- count : 문자열 안의 특정 문자열 개수 세기
- find : 문자열 안의 특정 문자열이 처음 나온 위치 반환 / 문자열이 없으면 -1 반환
- index : find와 같으나 문자열이 없으면 오류 발생
- join : 특정 문자열을 각각의 문자 사이에 삽입하여 출력
- split : 특정 문자열을 기준으로 문자열을 나눈 값을 출력
- replace : 특정 문자열을 특정 문자열로 반환
- startswith, endswith : 특정 문자열로 시작하는지 끝나는지 확인
■ input 함수
- 변수 = input() 형식으로 변수에 들어갈 값을 입력받을 수 있음
a = input()
# aaa 입력
print(a)
# 출력값은 aaa이다
4. 리스트
■ 리스트(List)
- 요소들의 모음을 나타내는 자료형
a = [1, 2, 3, 4, 5]
print(a, type(a))
# 출력값은
# [1, 2, 3, 4, 5] <class 'list'>
■ 인덱싱
- 문자열과 마찬가지로 인덱싱을 적용할 수 있음
a
[1, 2, 3, 4, 5]
print(a[0])
print(a[3:])
# 출력값
# 1
# [4, 5]
■ 리스트 연산
- + : 리스트와 리스트를 순서대로 연결
- * : 리스트와 숫자형을 곱하여 리스트 안의 요소를 숫자만큼 반복한 하나의 리스트를 만듬
a = [1, 2, 3]
b = [4, 5, 6]
a + b
# 출력값
# [1, 2, 3, 4, 5, 6]
a * b
#출력값
# [1, 2, 3, 1, 2, 3, 1, 2, 3]
■ 리스트(List) 함수(외우기 힘드니 자주 연습 필요)
- len : 리스트의 길이를 구함
- sum, min, max : 리스트 요소들의 합, 최솟값, 최댓값을 구함
- in : 특정 요소가 리스트 안에 있는지 확인
- append, extend : 리스트의 맨 마지막에 요소를 추가, 리스트의 맨 마지막에 다른 리스트를 추가
- insert : 리스트의 특정 위치에 특정 요소를 삽입
- remove, pop : 리스트의 요소를 삭제
- count : 리스트의 특정 요소의 개수를 반환
- index : 리스트에 요소가 있는 경우 인덱스 값을 반환
- sort, sorted, reverse : 리스트를 정렬
- join : 리스트의 요소들을 하나의 문자열로 합침
- split : 문자열을 리스트의 요소들로 쪼갬
- range : 숫자의 범위를 리스트로 변환
5. 튜플(tuple)
■ 튜플
- 리스트와 비슷하게 여러 요소를 묶음
- 삭제나 수정은 불가능
a = (1, 2, 3, 4, 5)
print(a, type(a))
# 출력값
# (1,2,3,4,5) <class 'tuple'>
■ 튜플 함수
- len : 튜플의 길이를 구함
- sum, min, max : 튜플의 요소들의 합, 최솟값, 최대값을 구함
- in : 특정 요소가 튜플 안에 있는지 확인
- count : 튜플의 특정 요소의 개수를 반환
- index : 튜플에 요소가 있는 경우 인덱스 값을 반환
- join : 튜플의 요소들을 하나의 문자열로 합침
■ 튜플 함수 심화
- max(튜플, key = lambda x:x[인덱스]) : 다중 튜플의 경우 정렬 기준을 정의하여 튜플 내 최댓값을 탐색
- min(튜플, key = lambda x:x[인덱스]) : 다중 튜플의 경우 정렬 기준을 정의하여 튜플 내 최솟값을 탐색
6. 딕셔너리(Dict)
■ 딕셔너리
- Key(키): Value(값)의 쌍이 모여있는 사전 형태의 자료형
- Key: 값의 쌍을 중괄호 ({ })로 감싸주기
Ex) 변수명 = {'key1':value, 'key2':value,....}
dic = {'name':'mina', 'age':'15'}
# {'name': 'mina', 'age': '15'}
■ 딕셔너리 요소 추가
- 딕셔너리 변수명[추가할 키] = 추가할
dic #변수명을 적어 데이터 불러와서
print(dic)
dic['age'] = ['20', '30']
print(dic)
■ 딕셔너리 요소 삭제
- del 딕셔너리 변수명[삭제할 키]
del dic['age']
print(dic)
■ 딕셔너리 key로 value 찾기
- 딕셔너리 변수명[찾을키]
print(dic['name'])
print(dic['age'])
■ 딕셔너리 함수
- keys() : 키를 반환
- values() : 값들을 반환
- item() : 키와 값의 튜플 쌍들을 반환
dic # {'name':['namu','mina'], 'age':['10','20']}
print(dic.keys()) # dic_keys(['name','age'])
print(dic.values()) # dic_values([['mamu','mina'], ['10','20']])
print(dic.items()) # dic_items([('name', ['namu','mina']), ('age', ['10','20'])])
- get(원하는 키값) : 원하는 키값에 대응되는 값을 반환
dic.get('name')
# ['namu','mina']
- update : 새로운 딕셔너리를 추가
dic1 = {'a':[1,2], 'b':4}
dic2 = {'c':5, 'd':[6,7]}
dic1.update(dic2)
dic
# {'a': [1, 2], 'b': 4, 'c': 5, 'd': [6,7]}
7. 집합
■ 집합
- 순서가 없고 중복이 없는 자료형
- 요소들을 중괄호 ({})로 감싸면 됨
8. 불리언
■ True(참) or False(거짓)을 나타내는 자료형
2. Colab
■ Colab(분석환경)
- 구글에서 제공하는 서비스
■ Colab 사용하는 방법
① 구글 계정 로그인
② Google Drive 이동
③ 신규 → 더보기 → 연결할 앱 더보기 → 앱 검색(Colaboratory) → 설치
④ 강의 자료 내 Drive에 업로드하기
⑤ IPY&B라는 확장자를 가진 파일을 더블 클릭해서 열기 → Core App 환경 확인 가능
■ Colab 새로운 파일 만들기
① 신규 → 더보기 → Google Colaboratory → 만들고 공유
② 실습하고 싶은 코드 작성하고 저장
■ 코드 셀 / 텍스트 셀
- 코드 셀 : 코드를 입력하고 실행하는 셀
- 텍스트 셀 : 텍스트를 입력하고 실행하는 셀
■ 단축키
- 현재 셀 위에 새로운 셀 삽입 : Ctrl + M + A
- 현재 셀 아래에 새로운 셀 삽입 : Ctrl + M + B
- 코드 셀로 변경 : Ctrl + M + Y
- 텍스트 셀로 변경 : Ctrl + M + M
- 셀의 삭제 : Ctrl + M + D
- 현재 셀을 실행하고 현재 셀에 커서 유지 : Ctrl + Enter
- 현재 셀을 실행하고 다음 셀로 커서 옮김 : Shift + Enter
※ 파일 업로드 주의할 점
- 경로를 복사해 넣기 보단 구글 드라이브에 파일 업로드하고 가져오는걸 추천
→ 이유는 세션이 종료되면 파일이 사라지기 때문!!!
'데이터분석 부트캠프' 카테고리의 다른 글
| Python 주피터 설치 방법 & 가상환경 설정 (0) | 2024.05.03 |
|---|---|
| 커리어 성장 컨퍼런스_데이터분석 전문 데프콘 강의 후기 (1) | 2024.04.30 |
| 데이터분석 부프캠프 14기 - 1주차 (1) | 2024.04.26 |
| 데이터분석 부트캠프 OT (0) | 2024.04.22 |
| 패스트캠퍼스 데이터 분석가 14기 지원 후기 (1) | 2024.03.25 |

